- Spis treści
- I. Informacje podstawowe
- II. Instalacja
- III. Podręcznik uŋytkownika
- IV. Podręcznik administratora
- Zarządzanie pakietami
- Bootloader
- Kernel i urządzenia
- Konfiguracja systemu
- Pamięci masowe
- Administracja
- Interfejsy sieciowe
- Zastosowania sieciowe
- Usģugi dostępne w PLD
- Usģugi - wstęp
- ALSA - Džwięk w Linuksie
- Apache - Serwer stron internetowych
- BIND - Serwer Nazw
- CRON - Cykliczne wykonywanie zadaņ
- CUPS - Popularny system druku dla Uniksa
- DHCPD - Dynamic Host Configuration Protocol Daemon
- Exim - Transport poczty elektronicznej (MTA)
- Heimdal - Implementacja protokoģu Kerberos
- Jabber 2 - Serwer typu Instant Messaging
- MySQL - System Zarządzania Relacyjnymi Bazami Danych (ang. RDBMS)
- NFS - Network File System
- PDNS (Power DNS) - Serwer Nazw
- Postfix - Transport poczty elektronicznej (MTA)
- PostgreSQL - Baza danych SQL
- ProFTPD - serwer FTP
- Samba - wspóģpraca z Windows
- Snort - Sieciowy System Wykrywania Wģamaņ
- Syslog-ng
- X-Window
- V. Tworzenie PLD - Praktyczny poradnik
- VI. O podręczniku
I. Informacje podstawowe
Wprowadzenie
Streszczenie
Dziękujemy za zainteresowanie się PLD Linux Distribution!
W tym rozdziale przedstawione zostaną róŋne aspekty dotyczące projektu PLD, takie jak jego historia, cele, model rozwoju, itp.
Konwencje uŋyte w tej ksiąŋce
Aby jak najlepiej zrozumieæ i przyswoiæ informacje zawarte w tym podręczniku, warto zapoznaæ się wpierw z uŋytymi konwencjami.
$ komenda |
W ten sposób opisywane są komendy, które wykonaæ moŋemy z uprawnieniami uŋytkownika.
# komenda |
Tutaj natomiast przedstawiona zostaģa komenda, którą naleŋy wykonaæ z poziomu uŋytkownika root, czyli administratora.
Zbyt dģugie linie zrzutów ekranowych, które nie mieszczą się w jednej linii, podzielone są przy pomocy znaku \. Czyli:
# komenda z_bardzo_\ dģugim_parametrem |
naleŋy zinterpretowaæ jako:
# komenda z_bardzo_dģugim_parametrem |
W dokumentacji dosyæ często korzysta się z następującej konstrukcji:
{$zmienna} |
Tak oznaczane są miejsca, w których uŋytkownik moŋe lub musi samodzielnie dokonaæ wyboru i wstawiæ w miejsce ciągu znaków {$zmienna} odpowiednią wartoķæ.
Niejdnokrotnie w nazwach plików pojawia się znak "gwiazdki", który naleŋy odczytywaæ podobnie jak robi to powģoka (shell), a więc zastępuje dowolny ciąg znaków, przykģadowo:
/katalog/plik.* |
O tym podręczniku
Celem tego podręcznika jest pomoc w zainstalowaniu PLD Linux Distribution na Twojej maszynie. Nie jest to i nigdy nie będzie zamiennik dokumentacji systemowej. Jeķli będzie to Twoja pierwsza instalacja Linuksa, gorąco zachęcamy Cię do przeczytania wpierw tego podręcznika. Nawet jeķli jesteķ doķwiadczonym uŋytkownikiem, warto przestudiowaæ instrukcje dotyczące instalacji, aby upewniæ się, ŋe wszystko pójdzie gģadko.
Oprócz niniejszej dokumentacji moŋemy szukaæ pomocy w wielu innych miejscach. Pręŋnie dziaģają listy dyskusyjne oraz oficjalne kanaģy IRC (#PLD i #PLDhelp). Na często zadawane pytania (FAQ) odpowiedzi moŋna znaležæ na gģównej stronie WWW.
Jeķli uwaŋasz, ŋe dokumentacja jest niepeģna,
znalazģeķ bģędy, lub chciaģbyķ do nas doģączyæ prosimy
o wysģanie informacji na listę dyskusyjną
<pld-doc@pld-linux.org> lub o kontakt z jednym z
autorów dokumentacji, których listę zamieszczono w
sekcja Autorzy dokumentacji PLD w rozdziaģ O podręczniku
Krótka historia PLD
Wraz ze wzrostem zainteresowania Linuksem w Polsce, rosģy naciski na stworzenie polskiej dystrybucji tego systemu. Niemal wszyscy jej chcieli, a niektórzy nawet mówili, ŋe juŋ takową robią. Nic jednak z tego nie wynikaģo. Wreszcie, w lipcu 1998, zawiązaģ się projekt mający na celu stworzenie polskiej dystrybucji Linuxa. Projekt PLD, czyli Polish(ed) Linux Distribution, byģ na tyle dobrze zorganizowany, by przetrwaæ trudne początki. Nie obeszģo się oczywiķcie bez burzliwych dyskusji na temat ksztaģtu dystrybucji, doboru oprogramowania jak równieŋ wersji jądra, na której projekt ma byæ rozwijany. W efekcie zdecydowano się prowadziæ równolegle dwa projekty. Pierwszy zostaģ nazwany PLD-devel i byģ forpocztą dla obecnego PLD-stable. Prace nad 1.1 PLD (devel) koordynowali przede wszystkim Wojtek Ķlusarczyk, Marcin Korzonek i Arek Miķkiewicz. Miaģa to byæ pierwsza dystrybucja Linuxa zgodna z nowym, promowanym przez OpenGroup, standardem - Unix98. Równolegle druga grupa, na czele z Tomkiem Kģoczko i Arturem Frysiakiem, pracowaģa nad podwalinami wģaķciwej PLD-stable.
Nieco póžniej, przede wszystkim z braku wolnego czasu z prac nad projektem wycofali się Wojtek Ķlusarczyk, Andrzej Nakonieczny oraz Marcin Korzonek. Tomasz Kģoczko postanowiģ kontynuowaæ prace nad PLD, gromadząc wokóģ siebie coraz to większą liczbę developerów. Pojawiģa się domena pld.org.pl, a wraz z nią liczne adresy "funkcjonalne", takie jak ftp.pld.org.pl, www.pld.org.pl czy cvs.pld.org.pl. Ruch na listach mailingowych stawaģ się coraz większy, widaæ byģo, iŋ projekt zyskiwaģ na popularnoķci.
22 listopada 2002 roku ķwiatģo dzienne ujrzaģa pierwsza stabilna wersja dystrybucji PLD Linux Distribution 1.0 (Ra). Jeszcze w czasie jej stabilizacji rozpoczęģy się prace nad kolejną wersją.
Twórcy projektu zakģadali uniwersalnoķæ PLD, która pozwalaģaby na korzystanie z dystrybucji przez uŋytkowników z caģego ķwiata, jednak pojawiģy się obawy, ŋe nazwa Polish(ed) Linux Distribution odstraszy potencjalnych odbiorców z innych krajów. Postanowiono, ŋe zmieniona zostanie nazwa projektu. Pozostawiono charakterystyczny skrót "PLD" w niezmienionej postaci, zmieniono zaķ jego rozwinięcie - nazwa "PLD" staģa się rekurencyjnym skrótem od PLD Linux Distribution.
Pierwszego kwietnia 2007 roku wydana zostaģa wersja Ac, dģugi okres rozwoju przyzwyczaiģ uŋytkowników do nieustających aktualizacji oprogramowania. Taki model rozwoju dystrybucji okazaģ się na tyle wygodny, ŋe postanowiono by kolejne wydanie miaģy byæ rozwijane bez koņca. Oznacza to, ŋe na razie nie są planowane ŋadne kolejne wydania, a do stabilnej gaģęzi pakietów nieprzerwanie trafiają aktualizacje.
Informacje o PLD
Podstawowe informacje
PLD-Linux jest dystrybucją rozwijaną gģównie w Polsce. Jest to produkt grupy entuzjastów Linuksa chcącej stworzyæ system operacyjny dopasowany do wģasnych potrzeb. Aktualnie rozwojem dystrybucji interesuje się okoģo 200 osób, z poķród nich najbardziej aktywna jest grupa 50 deweloperów.
PLD jest jednym z najaktywniejszych projektów Open Source na ķwiecie. Dzięki temu powstaģa jedna z największych dystrybucji Linuksa, w trakcie prac nad drugą wersją systemu (Ac) iloķæ dostępnych pakietów zbliŋyģa się do trzynastu tysięcy.
Zaģoŋenia PLD
Jedną z największych bolączek administratorów jest chroniczny brak czasu, dlatego bardzo istotne jest zminimalizowanie nakģadu pracy przy codziennych zajęciach administracyjnych. Mając to na uwadze, stworzono dystrybucję, która zapewnia wysokie bezpieczeņstwo i ģatwoķæ administracji. PLD jest tak projektowane by w moŋliwie najkrótszym czasie uruchomiæ bezpieczny, wydajny i ģatwy w zarządzaniu system produkcyjny. Zaģoŋono, ŋe administrator nie moŋe traciæ czasu na kompilację jądra, programów czy teŋ pisania rc-skryptów.
PLD jest uniwersalną i elastyczną dystrybucją, dzięki czemu sprawdzi się w róŋnorodnych zastosowaniach. Przy jej tworzeniu, gģówny nacisk jest jednak kģadziony na niezawodne dziaģanie usģug. Utarģo się nawet powiedzenie, ŋe PLD jest dystrybucją tworzoną przez administratorów dla administratorów, mamy więc do czynienia z systemem dobrze przygotowanym do pracy w roli serwera.
Nie oznacza to bynajmniej, ŋe PLD nie nadaje się na system dla stacji roboczej, doskonale sprawdza się równieŋ w tym zastosowaniu. Zwykģy uŋytkownik nie znajdzie tu wielu uģatwiających ŋycie początkującym narzędzi, aby uŋywaæ PLD konieczna jest solidna porcja wiedzy. Mamy nadzieję, ŋe niniejszy podręcznik będzie pomocny w jej zdobyciu.
Poniŋej przedstawiono zestawienie najciekawszych cech systemu.
System
w systemie dostępne są silnie zmodularyzowane jądra, dzięki czemu w ogromnej większoķci wypadków nie trzeba go kompilowaæ na nowo; wystarczy wybraæ wģaķciwy kernel i zaģadowaæ potrzebne moduģy
w PLD zastosowano skrypty startowe (rc-skrypty) typu System-V, Pozwoliģo to na maksymalne zautomatyzowanie procesu instalacji usģug systemowych.
podobną koncepcją do rc-inetd kierowano się w tworzeniu pakietu rc-boot, pozwala on na ģatwe zarządzania bootloaderami
uŋywanie FHS 2.x jako specyfikacji struktury katalogów
caģkowite odejķcie od termcap i libtermcap (w PLD nie ma pakietu z libtermcap i samego termcapa; ani jeden pakiet nie jest związany z termcapem)
uporządkowane rozmieszczenia plików w gaģęzi /usr - ŋaden pakiet dystrybucyjny nie umieszcza plików w katalogach wewnątrz /usr/local
Bezpieczeņstwo
domyķlne jądro zawiera grsecurity
restrykcyjne uprawnienia dla uŋytkowników
przystosowanie do ģatwego przejķcia systemu na alternatywne metody autoryzacji (i -- w zaleŋnoķci od potrzeb -- szyfrowania) komunikacji po sieci, jak PAM, czy GSAPI, TSL/SSL... Jest bardzo prawdopodobne, ŋe juŋ w niedģugiej perspektywie duŋą rolę zacznie tu odgrywaæ SASL. W praktyce owo ģatwe dostosowywanie do np. kerberyzacji systemu jest realizowane takŋe z uŋyciem rc-inetd, która to platforma uģatwia znakomicie podmianę róŋnych serwisów na wersje skerberyzowane czy teŋ wykorzystujące inne mechanizmy jak np. socks5 (tutaj jeszcze jest maģo zrobione, ale furtka jest szeroko i jednoznacznie otwarta)
mechanizm sys-chroot uģatwiający zarządzanie ķrodowiskami typu chroot oraz dobre wsparcie dla ķrodowisk Linux VServer
Sieæ
PLD posiada najlepszą obsģugę przyszģoķciowego protokoģu IPv6 z poķród innych dystrybucji Linuksa.
uŋywanie iproute2 jako podstawowego narzędzia do operowania na interfejsach sieciowych, dzięki czemu np. skrypty startowe z PLD są prostsze i krótsze mimo większej funkcjonalnoķci w stosunku do swoich odpowiedników z RH; inną zaletą jest wsteczna kompatybilnoķæ z opisem interfejsów sieciowych z tym, co jest stosowane w initscripts z RH; kolejną cechą skryptów startowych jest to, ŋe -- w zaleŋnoķci od preferencji uŋytkownika -- mogą one wyķwietlaæ wszystkie komunikaty po polsku
PLD zawiera rc-inetd - interfejs do zarządzania usģugami typu inetd. Pozwala zarządzaæ takimi usģugami (np.: telnetd, cvs-pserver) bez znaczenia jakiego typu demon inetd jest uŋywany
Pakiety
PLD zawiera ogromne iloķci gotowych, binarnych pakietów; pozwala to uniknąæ instalacji oprogramowania spoza dystrybucji
w dystrybucji uŋywane są pakiety typu RPM, do zarządzania nimi stworzono program o swojsko brzmiącej nazwie Poldek, moŋna teŋ uŋywaæ klasycznego programu RPM
moŋliwoķæ samodzielnego budowania pakietów RPM pozwoli na ģatwe skompilowanie pakietu z nietypową funkcjonalnoķcią
znaczna liczba programów podzielona jest na mniejsze pakiety, pozwalające instalowaæ tylko te elementy systemu, które są akurat potrzebne
pakiety często są wstępnie skonfigurowane i gotowe do dziaģania, ponadto nakģadane są na nie istotne ģaty
w PLD nie są faworyzowane ŋadne z usģug czy programów. To czego uŋywamy zaleŋy tylko od nas
peģne przygotowanie pakietów do automatycznego uaktualnienia. Pakiety z RH kompletnie nie są na to przygotowane. Przygotowanie to wiąŋe się z restartowaniem serwisów przy ich uaktualnieniu, odpowiednim przygotowywaniem procedur uaktualnienia w taki sposób, by umoŋliwiæ automatyczną aktualizację nawet przy zmianie plików konfiguracyjnych
kompresowanie wszystkich plików dokumentacji z uŋyciem gzip (bzip2 nic w praktyce tu nie wnosi, a dostarcza tylko nowych kģopotów, czego doķwiadczają od czasu do czasu uŋytkownicy Mandrake)
separacja bibliotek statycznych w osobne podpakiety {$nazwa}-static (nie kaŋdy tego potrzebuje), a nagģówków do {$nazwa}-devel
uzupeģnianie opisów pakietów i dokumentacji w róŋnych językach. W duŋej częķci robi się to niejako przy okazji. Uŋytkownik moŋe sobie skonfigurowaæ i zainstalowaæ wybrane oprogramowanie ze wsparciem dla preferowanego zestawu języków, np.: angielski i niemiecki czy teŋ angielski i polski (zasoby dla innych języków zostaną pominięte). Tak unikalną moŋliwoķæ konfiguracji osiągamy dzięki konsekwentnemu oznaczaniu zasobów narodowych makrem %lang() w poszczególnych pakietach
Cechy uŋytkowe
PLD jest systemem przyjaznym dla programisty. Dostępne są narzędzia do tworzenia aplikacji w wielu językach programowania. Dotyczy wielu "standardowych" języków programowania takich jak C, C++, Perl czy Python. Dostępne są teŋ kompilatory do nieco mniej znanych języków takich jak SML, Prolog, OCaml jak teŋ eksperymentalne kompilatory: Cyclone, Ksi. Dodatkowo mamy wybór wielu narzędzi programistycznych i bibliotek.
maksymalna automatyzacja róŋnych powtarzalnych czynnoķci (dotyczy to zarówno metodologii bieŋącej pracy jak i zawartoķci pakietów)
dystrybucja jest przystosowana do obsģugi wielu języków narodowych, a w tym języka polskiego. Jest to najlepiej przygotowana dystrybucja na potrzeby polskich uŋytkowników
brak naģoŋonych z góry ograniczeņ co do zestawu pakietów, jakie mogą byæ w dystrybucji. W praktyce oznacza to, ŋe uŋytkownik ma do dyspozycji wszystko, co udaģo się nam zebraæ, Jeŋeli coķ zostanie opracowane i przystosowane do tego, ŋeby mogģo wspóģgraæ z resztą pakietów, to znaczy, ŋe komuķ byģo potrzebne, więc moŋe komuķ przydaæ się w przyszģoķci
Oficjalne wersje PLD
W PLD wersjom dystrybucji nadawane numery oraz dwuliterowe oznaczenia kodowe, które pochodzą od skrótowych oznaczeņ pierwiastków. Pierwszej wersji PLD nadano oznaczenie Ra (Rad), zaķ kolejne odpowiadają nazwom pierwiastków poukģadanych zgodnie z kolejnoķcią okreķloną przez ich liczbę atomową. Aktualnie mmy trzy oficjalne wydania: Ra, Ac, Th, jest teŋ nieoficjalny fork Titanium prowadzony przez jednego z deweloperów.
Model rozwoju PLD Linux Distribution
Rozwój PLD Linux Distribution przebiega w sposób otwarty i elastyczny. Efekt koņcowy to wynik nakģadu wielu osób, nie tylko developerów posiadających prawo zapisu do repozytorium CVS (o którym poniŋej), ale takŋe uŋytkowników zgģaszających informacje o bģędach lub nadsyģających poprawki lub propozycje zmian. Z chęcią przyjmiemy nowych developerów, a osoby chcące byæ bardziej związane z projektem powinny zapisaæ się na listę dyskusyjną developerów pld-devel-pl@lists.pld-linux.org.
Informacje o PLD i sposobie jego rozwoju:
Repozytorium CVS
Žródģa PLD Linux Distribution trzymane są w repozytorium CVS (Concurrent Versions System, http://www.cyclic.com/CVS/index.html), wolnodostępnym systemie kontroli wersji dostarczanym wraz z naszą dystrybucją. Serwer CVS PLD Linux Distribution (http://cvs.pld-linux.org/) jest dostępny dla wszystkich w trybie tylko dla odczytu (Read Only), oraz dodatkowo w trybie do odczytu/zapisu (Read/Write) dla developerów. Repozytorium zostaģo podzielone na kilka moduģów w celu uģatwienia pracy osobom doņ commitującym (okreķlenie commit pochodzi z podręcznika systemowego cvs).
Serwer DistFiles
W zamierzchģych czasach wszystkie pliki (a więc kody žródģowe, ģatki (patche), poprawki, itp) potrzebne do zbudowania pakietów trzymane byģy w repozytorium. Niestety CVS nie zostaģ zaprojektowany do przechowywania plików binarnych (a archiwum tar.gz takim jest) i próba zmuszenia go do przechowywania takowych dostarczaģa róŋnych problemów. A to osoba posiadające stosunkowo wolne ģącze zaczęģa wrzucaæ kilkudziesięcio megabajtowy plik, skutecznie blokując moŋliwoķæ pracy innym developerom na kilka godzin. Uciąŋliwe byģy teŋ pozostające tzw. 'locki', czyli blokady na moduģach repozytorium (przede wszystkim SOURCES/). Rozwiązaniem tych problemów byģo wprowadzenie w maju 2003 roku serwera DistFiles, do którego przeniesiono większoķæ plików binarnych z CVS.
Core Developers Group
Gdyby PLD Linux Distribution byģo firmą, Core Developers Group najtrafniej moŋna by okreķliæ jako Radę Nadzorczą. Jej celem jest podejmowanie w sposób demokratyczny krytycznych dla dystrybucji decyzji oraz rozwiązywanie konfliktów, których nie daģo się zaŋegnaæ w inny sposób. W skģad Grupy wchodzą developerzy aktywnie udzielający się w projekcie.
Lista dyskusyjna pld-devel-pl@lists.pld-linux.org
Na liķcie tej prowadzone są dyskusje na temat bieŋących prac nad dystrybucją, jak równieŋ ustalane są plany na przyszģoķæ. Jeķli nie posiadasz prawa zapisu do repozytorium, a chciaģbyķ podzieliæ się efektami swych prac z innymi, lista ta jest najlepszym miejscem na poinformowanie o tym fakcie.
Buildery
Mianem builderów okreķlane są specjalnie przygotowane ķrodowiska (często na dedykowanych maszynach), na których budowane są pakiety, które póžniej zostaną umieszczone na serwerach FTP projektu. Kaŋda z linii dystrybucji ma swoje oddzielne buildery, stworzone z pakietów dla niej przeznaczonych.
Nie wszyscy developerzy mają prawo do puszczania zleceņ na buildery, czyli rozkazów zbudowania poszczególnych pakietów - przywiliej ten ma ledwie garstka osób, zaznajomionych z automatyką oraz znających potrzeby danej dystrybucji. Rzadko kiedy zachodzi potrzeba bezpoķredniego grzebania w strukturze danego ķrodowiska - codzienna praca opiera się na wysyģaniu odpowiednio przygotowanych maili, podpisanych kluczem PGP osoby uprawnionej.
Projekty związane z PLD
Rescue CD
Jest to niewielka dystrybucja startująca z pģyty CD, bez koniecznoķci instalacji na twardym dysku. Zawiera zestaw wyspecjalizowanych narzędzi pomocnych w przypadku usuwania awarii systemu. Rescue CD oparto o jądro PLD i wyposaŋono w zestaw najbardziej niezbędnych programów, dzięki czemu udaģo się uzyskaæ niewielkie rozmiary dystrybucji. Pozwala to zaģadowanie caģoķci do pamięci operacyjnej, a następnie a wyjęcie pģyty CD z czytnika. Lista dostępnych programów jest umieszczona na domowej stronie WWW projektu.
PLD Live CD http://livecd.pl/
Pierwszy, oparty o PLD Ac projekt, mający na celu stworzenie kompletnej dystrybucji Linuksa startującej z pģyty CD, zawiera znaczną iloķæ narzędzi i programów uŋytkowych. PLD Live jest przygotowane dla zwykģych uŋytkowników chcących bliŋej poznaæ PLD, zawiera system X Window i liczne programy uŋytkowe. Z zaģoŋenia w PLD Live dokonywano jak najmniej zmian w stosunku do bazowej dystrybucji.
PLD Live.th http://livecd.pld-linux.org
Wersja Live zbudowana na bazie Th i ķrodowiska GNOME
PLD-Linux LiveCD http://kde4.livecd.pld-linux.org/index.php
Wersja Live zbudowana na bazie Titanium i ķrodowiska KDE
Zasoby sieciowe PLD
Waŋne adresy
Strona gģówna - http://pld-linux.org
Dokumentacja - http://pl.docs.pld-linux.org
Listy dyskusyjne - http://lists.pld-linux.org
Częķciowe archiwa list dyskusyjnych - mail-archive.com, Gmane
Serwer IRC (freenode) http://irc.freenode.net
Serwer IRC (IRCnet) http://ircnet.org
Serwer PLDNet: irc.pld-linux.org
Istniejące kanaģy:
#pld - kanaģ przeznaczony dla Developerów.
#pldhelp - kanaģ uŋytkowników PLD
#pldlivecd - kanaģ uŋytkowników LiveCD
Kanaģy w powyŋszych sieciach są poģączone za pomocą specjalnego bota. Przydatny w takich przypadkach moŋe byæ skrypt do programu irssi znajdujący się na stronie http://vorlon.icpnet.pl/~agaran/forwardfix.pl lub w zasobach poldka (poldek -i irssi-script-forwardfix), który ma zadanie przekazywaæ wiadomoķci między sieciami.
System zgģaszania bģędów - http://bugs.pld-linux.org
Rescue CD - http://rescuecd.pld-linux.org
PLD Live CD - http://livecd.pld-linux.org
Žródģa obrazów ISO
Obrazy ISO są katalogowane wg. schematu {$serwer}/{$wersja}/{$arch} np.: ftp.iso.pld-linux.org/2.0/i586. Wersje systemu szerzej opisano w sekcja Oficjalne wersje PLD w rozdziaģ Wprowadzenie, zaķ architektury w sekcja Architektury pakietów w rozdziaģ Zarządzanie pakietami.
Dla kaŋdego z obrazów ISO dostępna jest suma MD5, umieszczona w pliku o rozszerzeniu md5. Dzięki niej będziemy mogli sprawdziæ przed nagraniem czy pobrany obraz nie zawiera ŋadnych zmian. Do obliczenia skrótów MD5 w pod systemami uniksowymi posģuŋymy się programem md5sum, zaķ w systemach Microsoftu uŋyjemy dostępnego na serwerze programu md5sum.exe.
Serwery FTP z obrazami ISO:
TASK, Gdaņsk, Polska - ftp://ftp.iso.pld-linux.org
Serwery z pakietami
Pakiety są katalogowane wg. schematu {$serwer}/dists/{$wersja}/{$žródģo}/{$arch} np.: ftp.pld-linux.org/dists/2.0/PLD/i586/. Wersje systemu szerzej opisano w sekcja Oficjalne wersje PLD w rozdziaģ Wprowadzenie, žródģa w sekcja Žródģa pakietów w rozdziaģ Zarządzanie pakietami, zaķ architektury w sekcja Architektury pakietów w rozdziaģ Zarządzanie pakietami.
PLD moŋemy zainstalowaæ z sieci za pomocą protokoģu FTP, HTTP lub RSYNC. Pakiety moŋemy pobieraæ z gģównego serwera PLD lub z jednego z wielu lustrzanych.
FTP - serwer podstawowy
FUH KERNEL, VNET.sk, Bratysģawa, Sģowacja - ftp://ftp.pld-linux.org/ , ftp://ftp.sk.pld-linux.org/ ,
FTP - serwery lustrzane
Gdaņsk, Polska - ftp://ftp2.pld-linux.org/
Uniwersytet Kardynaģa Stefana Wyszyņskiego, Polska - ftp://ftp3.pld-linux.org/ , ftp://ftp.csi.pld-linux.org/
ATM S.A., Warszawa, Polska - ftp://ftp4.pld-linux.org/ , ftp://ftp.atm.pld-linux.org/
Uniwersytet Warszawski, Wydziaģ Prawa i Administracji, Polska - ftp://ftp5.pld-linux.org/ , ftp://ftp.wpia.pld-linux.org/
TASK, Gdaņsk, Polska - ftp://ftp6.pld-linux.org/ , ftp://ftp.task.pld-linux.org/
Politechnika Wrocģawska, Polska - ftp://ftp.pwr.wroc.pl/pld/
ICM, Polska - ftp://ftp.icm.edu.pl/pub/linux/distributions/pld-linux/
Bratysģawa, Sģowacja - ftp://spirit.bentel.sk/mirrors/PLD
HTTP - serwery lustrzane
Gdaņsk, Polska - http://ftp2.pld-linux.org/
ATM S.A., Warszawa, Polska - http://ftp4.pld-linux.org/
TASK, Gdaņsk, Polska - http://ftp.task.pld-linux.org/
Bratysģawa, Sģowacja - http://spirit.bentel.sk/PLD/
RSYNC
Osoby zainteresowane udostępnianiem serwera lustrzanego przy
pomocy protokoģu RSYNC proszone są o kontakt z nami w celu
uzyskania szczegóģowych informacji:
<feedback@pld-linux.org>
Historia powstania naszego logo
Wstęp
Pomysģ na nasze logo zrodziģ się w gģowie Agnieszki Sloty. Projekt graficzny zostaģ stworzony przez Marcina Mierzejewskiego (Kevin) i Maæka Zieliņskiego.
Loga duŋe
Moŋe byæ uŋywane tylko wtedy, gdy:
produkt z logiem jest uŋywany zgodnie z udokumentowanymi na www.pld-linux.org zasadami (na przykģad oficjalne pģyty CD)
uzyskają aprobatę PLD Linuksa do uŋywania loga w okreķlonych celach
Częķæ caģkowitego produktu uznana jest oficjalnie za naleŋącą do PLD (tak jak jest to opisane w punkcie pierwszym) i jeķli posiada wyražnie zaznaczone informacje, ŋe tylko ta czeķæ zostaģa zatwierdzona
Zastrzegamy sobie prawo do uniewaŋnienia i modyfikacji licencji dla danego produktu
Pozwolenie na uŋywanie oficjalnego loga zostaģo przyznane dla wszelkiego typu odzieŋy (t-shirty, czapki, itd) ale pod warunkiem, ŋe są one wykonywane przez developerów PLD i nie są sprzedawane dla zysku.
Wyjaķnienie: Licencja "zapoŋyczona" z Debiana.
Ikony do umieszczania na stronach WWW
Powered by PLD Linux
To logo i jego zmodyfikowane wersje mogą byæ zamieszczane dla podkreķlenia poparcia dla projektu, lecz nie oznacza ono, ŋe dany produkt jest częķcią projektu.
Przypomnienie: docenimy jeķli dodasz do obrazka link wskazujący na www.pld-linux.org i umieķcisz go na swojej stronie.
Ikony stworzone przez uŋytkowników
To logo i jego zmodyfikowane wersje mogą byæ zamieszczane dla podkreķlenia poparcia dla projektu, lecz nie oznacza ono, ŋe dany produkt jest częķcią projektu.
Przypomnienie: docenimy jeķli dodasz do obrazka link wskazujący na www.pld-linux.org i umieķcisz go na swojej stronie.
Galeria rysunków Karola Kreņskiego
Pod tym adresem http://www.inf.sgsp.edu.pl/pub/MALUNKI/PLD/ Karol Kreņski "Mimooh" umieķciģ sporą galerię obrazków związanych z PLD Linux Distribution
II. Instalacja
Instalacja systemu
Ten rozdziaģ prezentuje instalację systemu.
Wymagania
Minimalne wymagania w przypadku architektury x86:
procesor minimum klasy 386
16 MB pamięci RAM (ze swapem przynajmniej 32MB)
50MB wolnego miejsca na dysku twardym
napęd CD-ROM lub stacja dyskietek 3,5 cala
Przygotowanie
Instalator
Noķniki na których umieszczany jest instalator:
Gģówna pģyta CD (base iso)
Jest to pierwsza z peģnych pģyt CD, wystarcza do zainstalowania najwaŋniejszych pakietów, aby zainstalowaæ caģoķæ dystrybucji musisz zaopatrzyæ się w pozostaģe pģyty. Lista serwerów z których pobierzemy obrazy ISO znajduje się w sekcja Žródģa obrazów ISO w rozdziaģ Zasoby sieciowe PLD.
Pģyta MINI-ISO
Miniaturowa wersja dystrybucji przystosowana do nagrania pģyty typu MINI-CD (pģyty o ķrednicy 8cm). Zawiera najbardziej podstawowe pakiety. Lista serwerów z których pobierzemy obraz MINI-ISO znajduje się w sekcja Žródģa obrazów ISO w rozdziaģ Zasoby sieciowe PLD.
Dyskietki
Mamy do dyspozycji kilka dyskietek zawierających instalator lub dodatkowe moduģy jądra. Oprócz nich konieczne będzie jeszcze jakieķ žródģo pakietów (sieæ/CD-ROM/dysk twardy).
Gģówne obrazy dyskietek (bootdisk_cd.img, bootdisk_net.img, bootdisk_pcmcia.img) obsģugują jedynie najpowszechniej uŋywany sprzęt, jeķli nasz nie jest obsģugiwany, to instalator poprosi o jedną z dodatkowych dyskietek z moduģami jądra. Z tego względu na wszelki wypadek moŋna pobraæ pliki o nazwie addons{$numer}.img
Obraz dyskietki i resztę pakietów moŋemy pobraæ z gģównego serwera lub jednego z serwerów lustrzanych, listę adresów znajdziemy w sekcja Serwery z pakietami w rozdziaģ Zasoby sieciowe PLD. Przykģadowo uŋyjemy adresu: ftp.pld-linux.org/dists/{$wersja_PLD}/PLD/{$arch}/PLD/images/ ({$wersja_PLD} to interesująca nas wersja PLD zaķ {$arch} oznacza architekturę procesora). Dostępne są obrazy dyskietek dla następujących architektur: i386, i586, i686 oraz athlon.
Instalacja z sieci
Jeŋeli masz wystarczająco szybkie ģącze moŋesz zainstalowaæ system z sieci. W tym procesie mamy do wyboru instalację pakietów przy pomocy protokoģów: FTP, HTTP lub NFS.
Moŋemy uŋyæ MINI-ISO, pierwszej pģyty instalacyjnej lub dyskietki. W przypadku dyskietki musimy uŋyæ obrazu bootdisk_net.img lub bootdisk_pcmcia.img (urządzenia sieciowe PCMCIA).
Moŋemy teŋ zainstalowaæ rdzeņ systemu z MINI-ISO lub pierwszej pģyty instalacyjnej, a następnie kontynuowaæ proces instalacji za poķrednictwem sieci z dziaģającego juŋ systemu.
Instalacja z pģyty CD-ROM
Uŋywamy w tym celu pierwszej z peģnych pģyt CD (base) lub wszystkich dostępnych obrazów.
Jeķli BIOS naszej maszyny nie potrafi uruchamiaæ systemu operacyjnego z pģyty CD, musimy wspomóc się dyskietką i obrazem bootdisk_cd.img. Po uruchomieniu instalatora z dyskietki jako žródģo pakietów wybieramy CD-ROM.
Instalacja z dysku twardego
Istnieje moŋliwoķæ instalacji z lokalnego dysku twardego, uŋyjemy do tego obrazu dyskietki bootdisk_cd.img. Musimy jeszcze przegraæ zawartoķæ obrazu pģyty CD do katalogu na jednej z partycji dyskowych.
Dodatkowe informacje
Pobrane z internetu obrazy dyskietki nagrywamy poleceniem
# dd if=bootdisk.img of=/dev/fd0 |
lub przy pomocy programu rawrite.exe pod systemem Windows/DOS. Program rawrite.exe moŋemy pobrac przykģadowo z ftp.pld-linux.org/dists/{$wersja_PLD}/PLD/{$arch}/PLD/dosutils/.
PLD jest przygotowane dla wielu architektur sprzętowych, zanim więc przystąpisz do instalacji upewnij się ŋe wybierzesz wģaķciwą wersję. Więcej na ten temat moŋna znaležæ w sekcja Architektury pakietów w rozdziaģ Zarządzanie pakietami
Instalacja
Wstęp
Jeŋeli pierwszy raz instalujesz Linuksa, lub jesteķ bardzo początkującym uŋytkownikiem warto abyķ wiedziaģ kilka rzeczy. Na początek zapoznaj się ze sposobem oznaczania dysków i partycji opisanych dokģadniej w sekcja Nazewnictwo urządzeņ masowych w rozdziaģ Pamięci masowe
Kiedy juŋ zaopatrzymy się we wģaķciwy noķnik, uruchamiamy komputer i czekamy na pojawienie się ekranu instalatora. Zaczniemy od poznania sposobu poruszania się po instalatorze, do przesuwania/przewijania tekstu bądž opcji uŋywasz "strzaģek" na klawiaturze, wybór akceptujesz klawiszem ENTER. Klawiszem TAB poruszasz się pomiędzy opcjami instalatora.
Zaczynamy
Widząc standardowy ekran zgģoszeniowy naciskamy ENTER i czekamy aŋ uruchomi się instalator. Wybieramy język - w naszym przypadku polski. Przeczytawszy krótkie wprowadzenie jesteķmy w instalatorze.
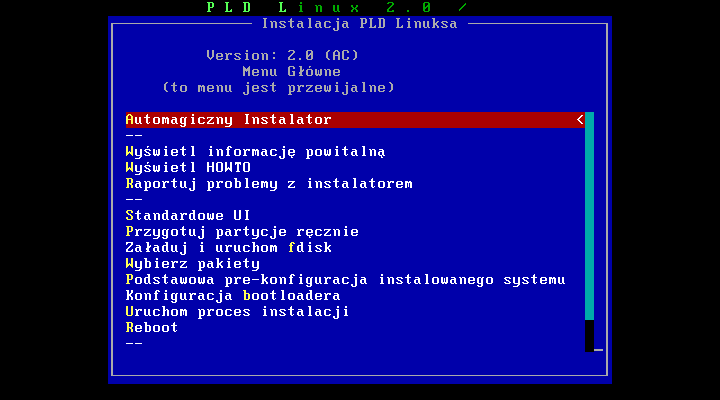
Teraz pojawiģo nam się menu, w którym mamy do wyboru sposoby instalacji. Jeŋeli posiadasz większą niŋ podstawową wiedzę nt. linuksa moŋesz wybraæ "Standartowe UI", gdzie większoķæ opcji umieszczona jest na jednym przejrzystym ekranie. Takŋe kolejne opcje pozwolą ustawiæ partycje, wybraæ pakiety, prekonfigurowaæ system oraz ustawiæ bootmanagera. Do edycji partycji mamy do wyboru program fdisk lub parted.
My wybieramy jednak opcję "Automagiczny Instalator", który sam przeprowadzi nas gģadko przez proces instalacji.
Žródģo
Instalacja z sieci
Doszliķmy do momentu gdzie musimy ustawiæ parametry žródģa, skąd będzie instalowaģ się system. Jeŋeli korzystamy z bootkietek musimy dobraæ odpowiednią w stosunku do žródģa z którego będziemy pobierali pakiety.
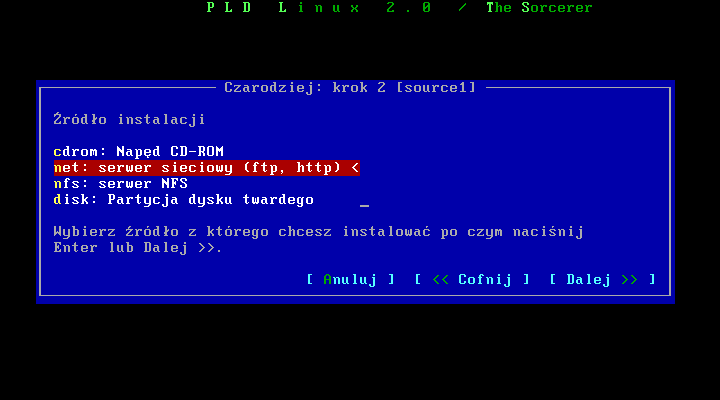
Powyŋej widzimy ekran wyboru žródģa ,ja wybraģem instalację z sieci, jednak instalacja z pģyty cd, dysku twardego czy nfs-u nie będzie znacząco się róŋniģa.
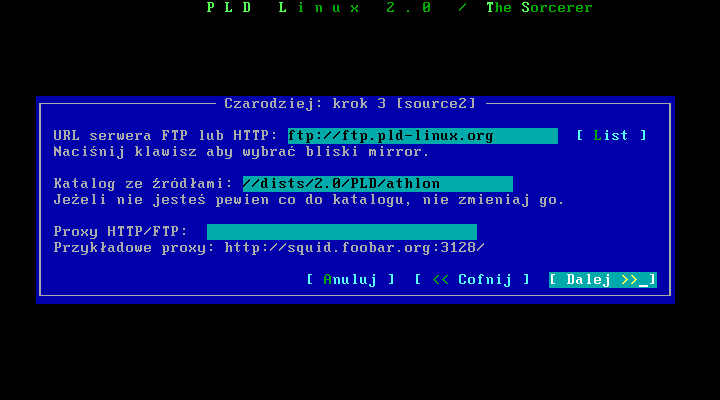
Następnie wybieram serwer ftp/http z którego chcę instalowaæ system, oraz ķcieŋkę do žródeģ. Jeŋeli masz w pobliŋu jakiķ mirror pld moŋesz skorzystaæ z niego, zamiast oficjalnego serwera.
Kolejne dwa ekrany to konfiguracja karty oraz poģączenia sieciowego. Wybrane parametry zaleŋą od posiadanego sprzętu i topologii sieci, wiec nie ma co nad tym się rozwodziæ.
Instalacja z cdromu
Jeŋeli instalujesz system z pģytek musisz zaopatrzyæ się albo w miniiso, albo przynajmniej w pierwszą (base) pģytkę.
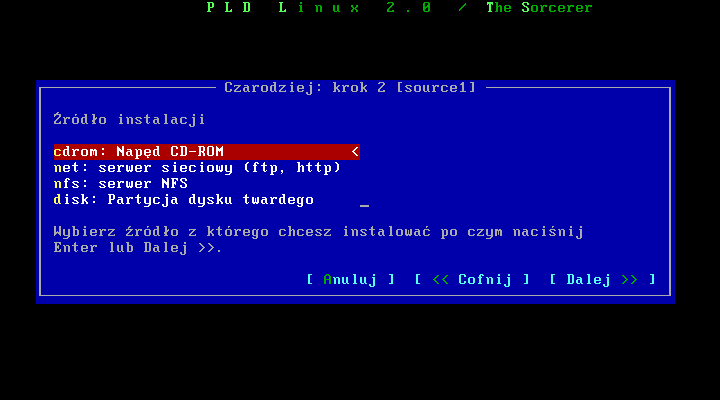
W menu wyboru žródģa wybieramy cdrom. Nie jest waŋne czy instalujemy caģy system z pģytek, czy tylko miniiso.
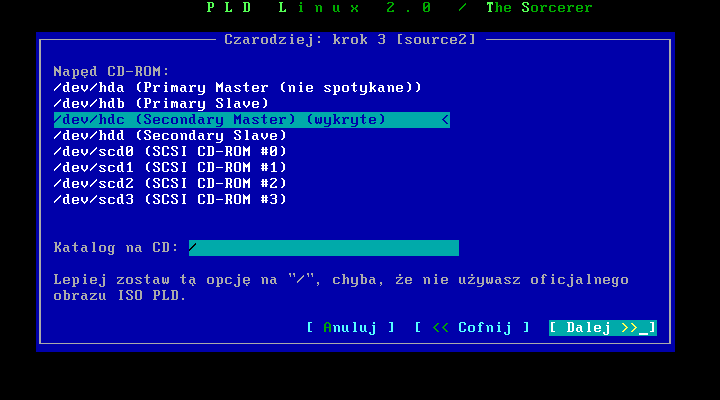
Teraz moŋemy wybraæ urządzenie, które sģuŋy w naszym systemie jako cdrom. System powinien znaležæ i zaznaczyæ istniejący w systemie napęd, jednak jeŋeli mamy więcej niŋ jeden to tutaj naleŋy zaznaczyæ w którym znajduje się pģytka instalacyjna. Moŋesz takŋe ustawiæ katalog w którym znajdują się pakiety, jednak jeŋeli uŋywasz oficjalnych pģytek nie naleŋy nic tutaj zmieniaæ.
Moŋesz teraz przejķæ do kolejnego kroku, czyli ustawieņ partycji.
Partycje
Nadszedģ czas na konfigurowanie partycji. Moŋemy wybraæ proponowane przez instalator ustawienia albo skorzystaæ z bardzo przyjemnego narzędzia o nazwie parted. Jako, ŋe na dysku moŋemy mieæ inny system (Windows) lepiej dla bezpieczeņstwa ustawiæ partycje ręcznie.
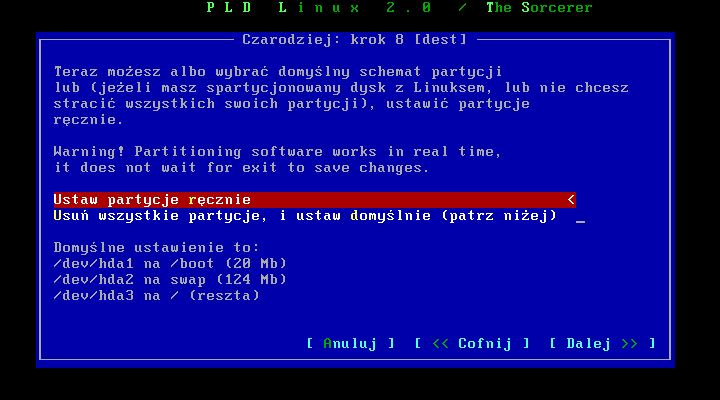
Wybierając opcję "ustaw partycje ręcznie" przechodzimy do parted
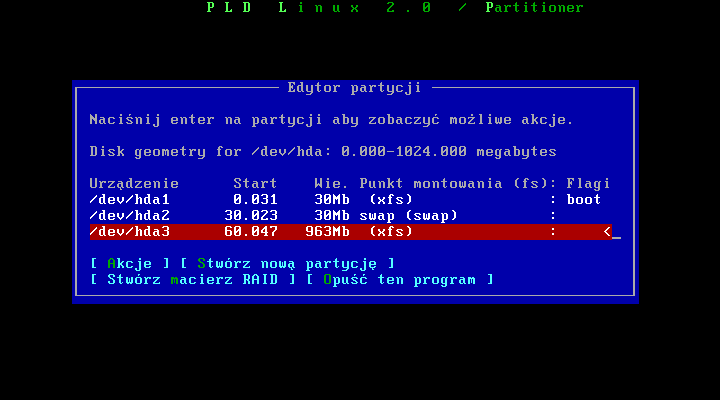
Interfejs jak widaæ jest bardzo prosty i intuicyjny. Jeŋeli mamy jakieķ wolne miejsce moŋemy utworzyæ nową partycje, stworzyæ macierz RAID, albo przeedytowaæ istniejącą juŋ partycję. UWAGA! Jeŋeli posiadasz nowy sprzęt, moŋesz mieæ problemy z instalacją systemu na raidzie. Problem ten wynika z tego, iŋ system, który wģaķnie instalujesz moŋe nie obsģugiwaæ Twojego raida.
Wchodząc w menu "Akcje" przechodzimy do menu edycji partycji.
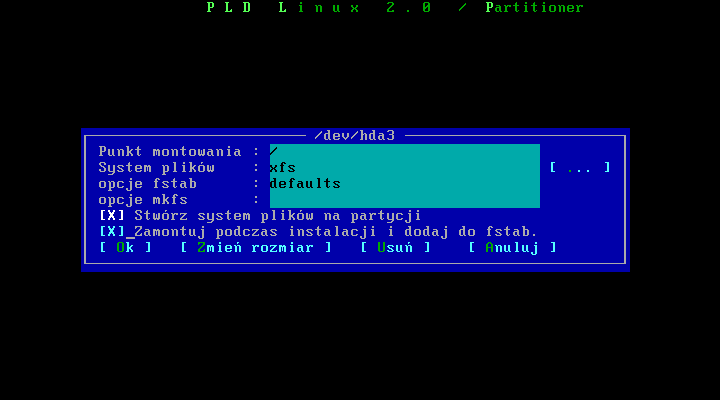
Moŋemy zmieniæ punkt montowania, system plików, rozmiar albo usunąæ partycję.
Po dokonaniu edycji tablicy partycji, oraz ustawieniu punktów montowaņ moŋemy opuķciæ parted i przejķæ do dalszej częķci instalacji.
Wybór pakietów
Przechodzimy teraz do kolejnej częķci instalacji, czyli wyboru pakietów.
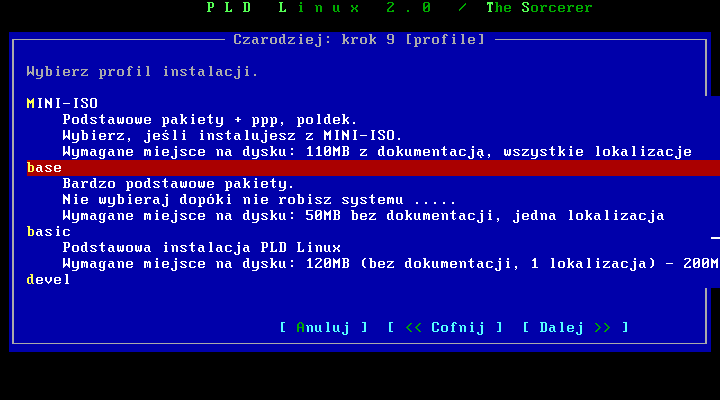
Mamy do wyboru następujące gotowe zestawy pakietów. Przy kaŋdym zestawie jest jego krótka charakterystyka, więc nie ma sensu się rozpisywaæ. Wybieramy taki zestaw jaki nam najbardziej pasuje, jednak nie warto przesadzaæ z pakietami, np stacja robocza z gnome nie będzie bardzo nadawaģa się na router. Po zainstalowaniu systemu będziesz zmuszony usunąæ masę niepotrzebnych pakietów, przez co stracisz mnóstwo czasu.
Dalej mamy moŋliwoķæ szczegóģowej selekcji pakietów, jeŋeli ufamy instalatorowi moŋemy pominąæ ten krok, jeŋeli natomiast znamy się trochę na linuksie wybieramy powyŋszą opcję i wchodzimy do menu.
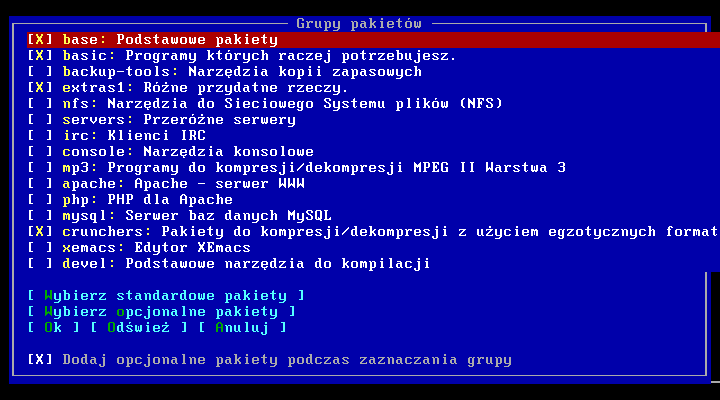
Na ekranie widzimy zaznaczone grupy pakietów, moŋemy zaznaczaæ dodatkowe, albo zrezygnowaæ z dotychczas wybranych. Moŋemy takŋe rezygnowaæ z pojedynczych pakietów z grup wchodząc w opcję standartowe pakiety. Pod linkiem "Wybierz opcjonalne pakiety" widzimy menu dzięki któremu mamy moŋliwoķæ bardziej spersonalizowanego wyboru interesujących nas pakietów.
Kolejnym krokiem jest pytanie czy chcemy zainstalowaæ dokumentację, na które lepiej odpowiedzieæ twierdząco. Mamy takŋe moŋliwoķæ wyboru wersji językowych dokumentacji. Jeŋeli nie jesteķmy pewni, moŋemy zostawiæ domyķlne ustawienia, czyli "ALL", jednak gdy chcemy mieæ dokumentację tylko po polsku i angielsku wpisujemy "pl:pl_PL:en:en_US". Naleŋy pamiętaæ, ŋe moŋe zdarzyæ się sytuacja iŋ pakiet nie ma jeszcze polskiej dokumentacji, więc zawsze warto zaznaczyæ język angielski.
Następne kroki to prekonfiguracja instalowanego systemu.
Prekonfiguracja systemu
Dotarliķmy do punktu gdzie musimy ustawiæ podstawowe parametry instalowanego systemu.
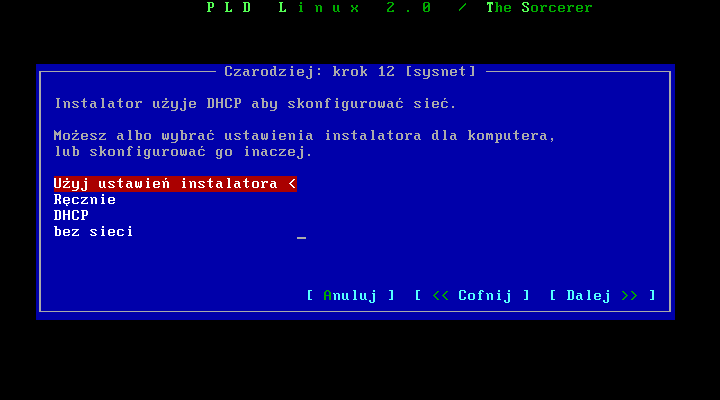
Pierwszym krokiem będzie ustawienie parametrów sieci (jeŋeli mamy do niej dostęp). Jeŋeli wczeķniej wybraliķmy instalację przez sieæ, moŋemy zastosowaæ te same preferencje takŋe w naszym systemie, jeŋeli jednak instalujemy z jakiegoķ noķnika (cdrom, dysk) naleŋy ręcznie wpisaæ ustawienia, lub pobraæ je z serwera dhcp.
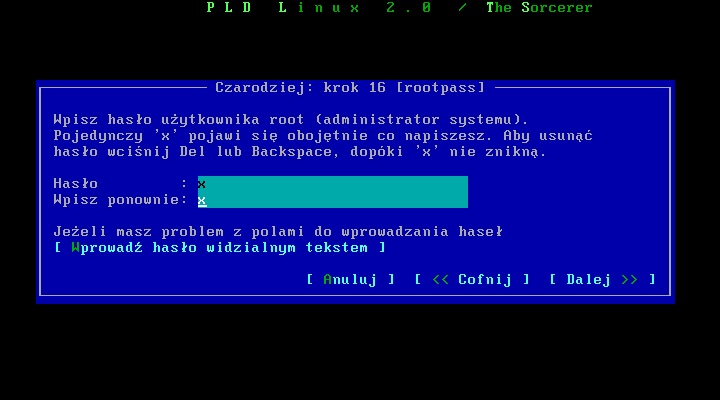
Kolejny krok to ustawienie hasģa uŋytkownika root. Ten punkt chyba nie wymaga komentarza. Naleŋy ustawiæ w miarę bezpieczne hasģo, bo jak wiadomo serwer jest tak bezpieczny jak jego najsģabsze ogniwo :) Moŋemy równieŋ zleciæ wygenerowanie hasģa instalatorowi.
Następną czynnoķcią jest ustawienie kont(a) uŋytkowników, moŋemy zrobiæ to teraz, albo po instalacji uŋywając polecenia useradd.
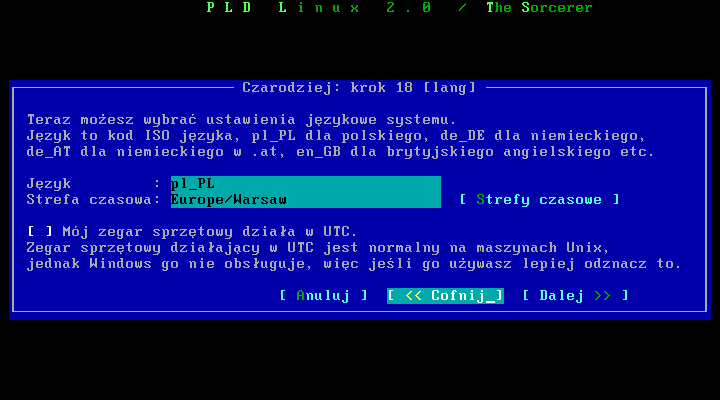
Pozostaģ jeszcze wybór strefy czasowej i synchronizacja (lub nie) zegara systemowego z UTC, i na tym koņczymy prekonfigurację systemu.
Bootmanager
Przyszģa kolej na ustawienie bootmanagera. Jeŋeli pld to nasz jedyny system na dysku moŋemy pominąæ ten krok, w przeciwnym przypadku musimy dodaæ wpisy innych systemów, aby byģa moŋliwoķæ uruchomienia ich przy starcie komputera. Oczywiķcie jeŋeli nie chcemy teraz konfigurowaæ bootmanagera moŋna zawsze to zrobiæ po ukoņczeniu instalacji, edytując plik /etc/lilo.conf.
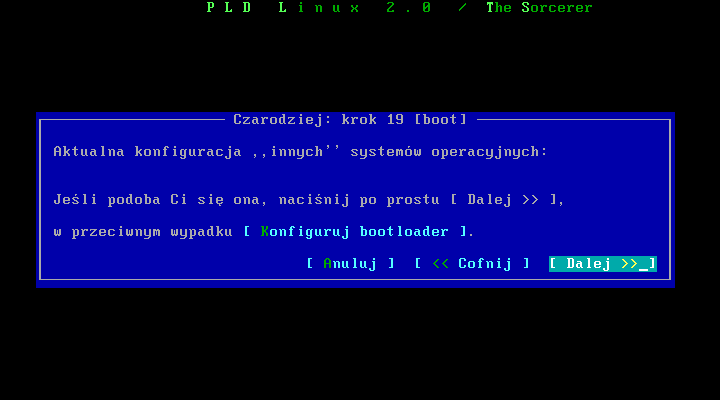
Wybieramy więc opcję "konfiguruj bootloader", która uruchamia skrypt konfigurujący.
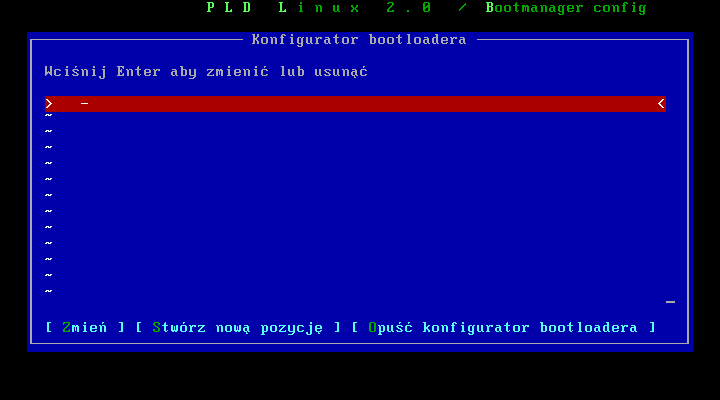
Jak widaæ nie mamy jeszcze ŋadnych wpisów, wybieramy "Stwórz nową pozycję" aby dodaæ jakiķ system operacyjny. Naleŋy tutaj pamiętaæ iŋ wpisujemy istniejące systemy na lokalnych dyskach, oprócz tego, który wģaķnie instalujemy.
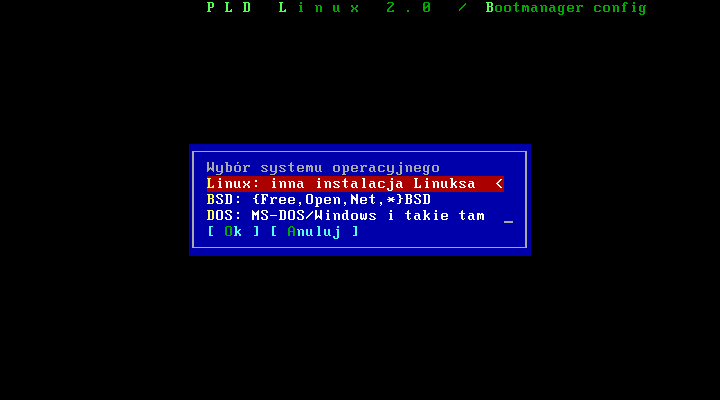
Pierwszym krokiem jest wybór systemu który chcemy ģadowaæ. Wybieramy np. DOS, następnie podajemy lokalizacje partycji na jakiej znajduje się system i przechodzimy do konfiguracji wpisu.
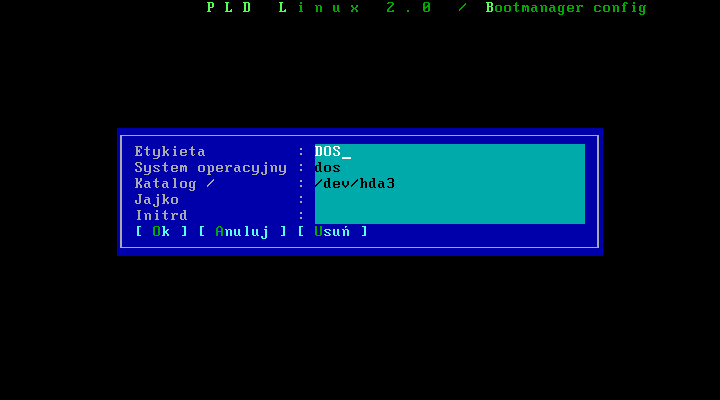
Jak widaæ na powyŋszym przykģadzie, musimy wpisaæ etykietę - czyli nazwę jaka będzie nam się wyķwietlaģa przy starcie komputera. Nazwa jest dowolna, jednak nie naleŋy przesadzaæ z dģugoķcią i lepiej nie uŋywaæ polskich znaków. Dwa kolejne pola, czyli "system" i "katalog /" mamy juŋ wypeģnione automatycznie. Jeŋeli dodajemy innego linuksa naleŋy podaæ lokalizację jądra systemu (kernela) oraz initrd jeķli mamy. W systemie DOS/Windows te pola są zbędne.
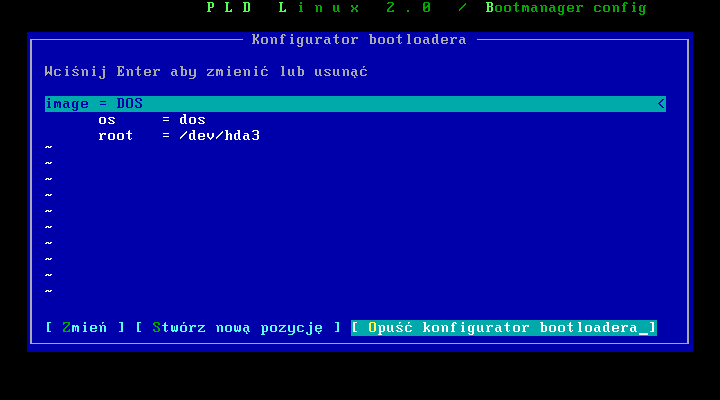
Po ustawieniu etykiety i zatwierdzeniu zmian moŋemy obejrzeæ nasz(e) wpis(y). Jeŋeli mamy więcej systemów dodajemy je po kolei, po skoņczeniu opuszczamy konfigurator przechodząc do kolejnej opcji.
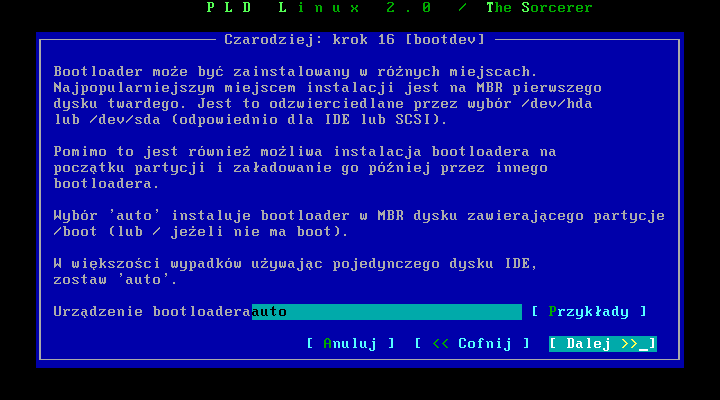
Ostatnią rzeczą jaką musimy zrobiæ aby zakoņczyæ proces konfiguracji bootloadera to wybór urządzenia na jakim ma byæ on zainstalowany. Najlepszym rozwiązaniem jest instalacja go w MBR (Master Boot Record) dysku z którego jest ģadowany system. Jeŋeli jednak nie jesteķmy pewni co do tego (lub nie wiemy co to jest MBR) najlepiej zostawiæ opcję auto, dzięki której instalator sam wybierze najlepsze urządzenie.
Koņczenie instalacji
Pozostaģa nam ostatnia rzecz, czyli instalacja pakietów. W tej częķci nie będziemy musieli nic robiæ, oprócz czekania. Więc jeŋeli wybraliķmy instalację z sieci i jakiķ większy zestaw pakietów moŋemy zaopatrzyæ się w jakąķ ksiąŋkę i poczytaæ, bo proces instalacji trochę potrwa :)
Sģowo komentarza na temat tego, co się dzieje na ekranie:
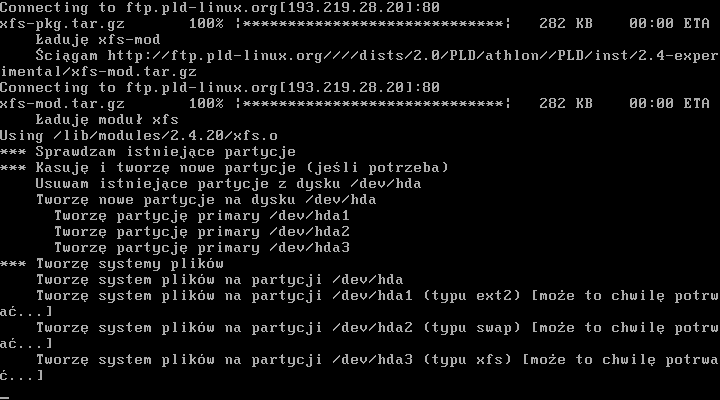
Tutaj widzimy jak system tworzy partycje, oraz system plików na nich. W zaleŋnoķci od wielkoķci partycji i szybkoķci dysku moŋe to trochę potrwaæ.
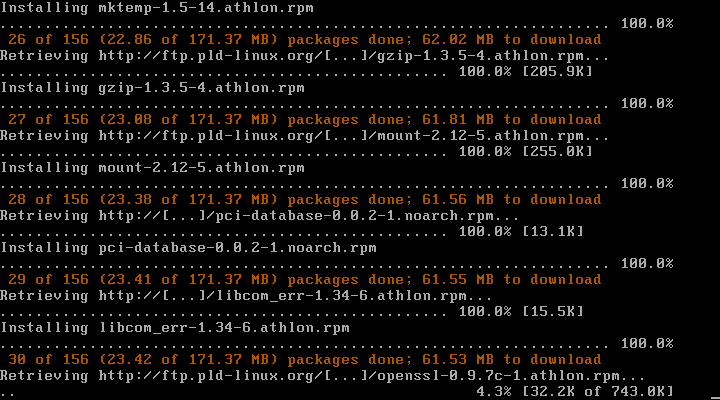
Dalej po pobraniu indeksów system przechodzi do instalacji pakietów (więcej o tym co to są indeksy w rozdziale poķwięconym poldkowi). To jest najdģuŋsza częķæ instalacji.
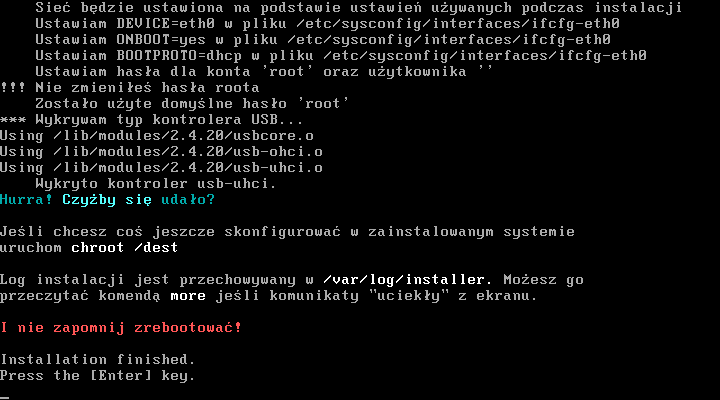
Jeŋeli nie wystąpiģy ŋadne bģędy zobaczysz taki ekran. Teraz wystarczy tylko zrestartowaæ system, wyciągnąæ pģytkę/dyskietkę z napędu, bądž ustawiæ bootowanie z dysku na którym zainstalowaģ się bootmanager (najczęķciej /dev/hda) i mamy gotowy system :)
Po instalacji
Po instalacji system uruchamiany jest w trzecim "poziomie pracy". Jeķli dana maszyna będzie korzystaģa z X-Window to zapewne zechcemy aby korzystaģa z piątego poziomu, o zarządzaniu poziomami pracy przeczytamy w sekcja Zmiana poziomu pracy systemu w rozdziaģ Administracja.
Instalator pozostawiģ w systemie pliki zawierające szczegóģy instalacji, oto ich lista:
/var/log/installer - szczegóģowy dziennik instalacji
/etc/installer.conf - lista ustawieņ instalatora
/etc/installer.pkgs - lista wybranych pakietów
/etc/installer.sysconf - wstępna konfiguracja systemu
Jeķli wybraliķmy jedną z minimalnych wersji systemu, to teraz powinna nastąpiæ wģaķciwa częķæ instalacji pakietów. W tym celu naleŋy uŋyæ programu Poldek, jego opis odnajdziemy w sekcja Poldek w rozdziaģ Zarządzanie pakietami
Instalacja przy uŋyciu chroota
Instalacja systemu przy uŋyciu chroot
Wstęp
Mamy moŋliwoķæ zainstalowania PLD przy uŋyciu innego systemu operacyjnego, sposób ten ma tę zaletę, ŋe daje nam okazję dobrego poznania PLD juŋ na etapie instalacji, a ponadto umoŋliwia wykonanie bardziej wyrafinowanych operacji, które są niedostępne z poziomu instalatora. Ta metoda instalacji pozwala zainstalowaæ bardzo maģą wersję systemu, (ok. 120MB), która wystarcza do uruchomienia systemu, skonfigurowania sieci, Poldka i pobrania kolejnych pakietów.
Do instalacji moŋemy uŋyæ dziaģającej dystrybucji, jednak najwygodniejsze będzie uŋycie dystrybucji typu live: RescueCD lub PLD-Live. Uŋycie systemu z pģyty CD ma tą zaletę, ŋe instalacja moŋe byæ wykonywana na docelowej maszynie, co uģatwi nam stworzenie prawidģowego obrazu initrd. Do instalacji Th naleŋy uŋyæ RescueCD 2.90 lub nowszej (kiedy się pojawią), zaķ do instalacji Ac - jednej ze starszych wersji np. 2.01.
Osoby ciekawe jak wygląda przebieg instalacji "na ŋywo", mogą obejrzeæ nagranie przykģadowej instalacji.
Uwaga! W niniejszym rozdziale nie zawarto wielu zbyt szczegóģowych opisów, dlatego w przypadku drukowania na papierze moŋe byæ konieczne dodrukowanie innych rozdziaģów dokumentacji.
Przygotowanie
Uruchomienie
W przypadku instalacji z dziaģającego systemu musimy podģączyæ dysk twardy do komputera i uruchomiæ go. W przypadku pģyty CD typu live - w BIOS-ie maszyny docelowej wģączamy opcję startu systemu z pģyty, a następnie umieszczamy noķnik w napędzie i czekamy na start systemu.
Wspóģczesne dystrybucje typu live same wykrywają sprzęt i ģadują odpowiednie moduģy kernela, jeķli jednak to się nie powiedzie to musimy wtedy wykonaæ tę operację samodzielnie, więcej na ten temat w sekcja Statyczne zarządzanie moduģami w rozdziaģ Kernel i urządzenia. Interesują nas jedynie moduģy kontrolera ATA/SATA/SCSI oraz interfejsu sieciowego.
Partycje/woluminy
System moŋemy zainstalowaæ na klasycznych partycjach dyskowych, woluminach LVM lub programowych macierzach, instalacja z chroot-a daje w tej kwestii duŋą swobodę. Opis tworzenia woluminów LVM przedstawiliķmy w sekcja LVM w rozdziaģ Pamięci masowe zaķ macierzy w sekcja RAID programowy w rozdziaģ Pamięci masowe. Dla uģatwienia jednak dalsze przykģady będą dotyczyģy zwykģych partycji.
Potrzebujemy co najmniej dwóch partycji: jednej na gģówny system plików i drugiej na obszar wymiany. Obszar wymiany nie jest wymagany do instalacji, jednak dla porządku utworzymy go juŋ na tym etapie. Przykģady będą dotyczyģy dysku /dev/sda. Nazewnictwo urządzeņ masowych wyczerpująco przedstawiono w sekcja Nazewnictwo urządzeņ masowych w rozdziaģ Pamięci masowe.
Na uprzywilejowanej pozycją będą tym razem uŋytkownicy kompletnych systemów, które umoŋliwiają uŋycie programu GParted lub QTParted, w przeciwnym wypadku uŋyjemy programu fdisk lub cfdisk np.:
# cfdisk /dev/sda |
Systemy plików
Inicjujemy obszar wymiany:
# mkswap /dev/sda1 |
# mkfs.ext3 /dev/sda2 |
Zapamiętujemy ukģad partycji i systemów plików, gdyŋ będzie on nam potrzebny do prawidģowego skonfigurowania pliku /etc/fstab. Teraz przyszedģ czas na utworzenie punktu montowania i podmontowania partycji np.:
# mkdir /pldroot # mount /dev/sda2 /pldroot |
Jeķli system ma uŋywaæ większej iloķci partycji (np. dla /boot) to montujemy je wszystkie.
Konfiguracja sieci
Zaģoŋyliķmy, ŋe będziemy instalowaæ pakiety z sieci, dlatego musimy skonfigurowaæ poģączenie. W opisach przyjęliķmy, ŋe maszyna jest podģączona do sieci Ethernet.
W przypadku RescueCD system domyķlnie próbuje pobraæ konfigurację z DHCP, dlatego od razu po uruchomieniu powinniķmy mieæ dziaģającą sieæ. Jeķli w sieci nie ma takiego serwera to musimy statycznie przydzieliæ parametry poģączenia. Zakģadając, ŋe chcemy ustawiæ adres 192.168.0.2 z maską /24 parametry pliku konfiguracji interfejsu (np.: /etc/sysconfig/interfaces/ifcfg-eth0) powinny mieæ następujące wartoķci:
DEVICE=eth0 IPADDR=192.168.0.2/24 ONBOOT=yes BOOTPROTO=none |
eth0 default via 10.0.0.254 |
nameserver 193.192.160.243 |
# service network restart |
Proxy
Jeķli potrzebujemy skorzystaæ z proxy ustawiamy odpowiednią zmienną ķrodowiskową np.:
# export ftp_proxy=w3cache.dialog.net.pl:8080 |
Konfiguracja Poldka
Zaczynamy od ustawienia najlepiej dopasowanej
architektury instalowanych pakietów, za pomocą opcji
_pld_arch w pliku
/etc/poldek/repos.d/pld.conf.
Więcej o architekturach pakietów w
sekcja Architektury pakietów w rozdziaģ Zarządzanie pakietami.
Dobrym pomysģem jest ustawienie opcji, umoŋliwiającej precyzyjne
wybieranie alternatywnych pakietów (dla nieco bardziej zaawansowanych):
choose equivalents manually = yes |
Teraz tworzymy katalog na indeksy Poldka np.:
# mkdir -p /pldroot/var/cache/poldek-cache |
cachedir = /pldroot/var/cache/poldek-cache |
Instalacja
Instalacja pakietów
Zanim zaczniemy instalowaæ pakiety musimy mieæ ķwiadomoķæ, ŋe zachodzi między nimi wiele zaleŋnoķci. Zostaną zainstalowane wszystkie wymagane dodatkowo pakiety, jednak nie mamy wpģywu na kolejnoķæ instalacji. Zdarza się, ŋe pakiet wymaga pliku lub programu, którego jeszcze nie ma w instalowanym systemie, przez co nie mogą byæ wykonane pewne operacje poinstalacyjne. Pojawią się nam wtedy na ekranie komunikaty bģędów, nie naleŋy się tym martwiæ, gdyŋ naprawimy ten problem reinstalując pakiet. Musimy jedynie wywoģaæ instalację z opcją --reinstall
Instalację rozpoczynamy od inicjacji bazy danych pakietów:
# rpm --root /pldroot --initdb |
W tej częķci instalacji zainstalujemy kolejno pakiety: setup, FHS, dev, pwdutils, chkconfig, dhcpcd, poldek, vim (lub inny edytor), geninitrd, module-init-tools, cpio, bootloader lilo lub grub, mount oraz mingetty. Moŋemy dodatkowo zainstalowaæ wiele innych pakietów, jednak moŋemy spokojnie to wykonaæ z dziaģającego juŋ systemu.
Mamy moŋliwoķæ uŋycia trybu interaktywnego Poldka:
# poldek --root /pldroot poldek> install setup FHS dev pwdutils chkconfig dhcpcd poldek vim geninitrd \ module-init-tools cpio grub mount login mingetty |
# poldek --root /pldroot -i setup FHS dev pwdutils chkconfig \ dhcpcd poldek vim geninitrd module-init-tools cpio grub mount login mingetty |
Jeķli zdecydowaliķmy sie macierze dyskowe, to powinniķmy zainstalowaæ dodatkowo pakiety: mdadm i mdadm-initrd (jeķli jest na gģównym systemie plików). Jeķli uŋywamy woluminów logicznych (LVM) to potrzebujemy pakiety odpowiednio lvm2 i lvm2-initrd.
Przygotowanie do instalacji kernela
Przed instalacją jądra musimy wykonaæ operacje konieczne do prawidģowego wygenerowania initrd:
Montujemy pseudo-system plików /proc:
# mount /proc /pldroot/proc -o bind
Konfigurujemy plik /pldroot/etc/fstab, tak by wpisy odpowiadaģy wybranemu przez nas ukģadowi partycji i systemów plików. Dla przykģadów z początku rozdziaģu wpisy będą wyglądaģy następująco.:
Więcej w sekcja Kluczowe pliki w rozdziaģ Konfiguracja systemu./dev/sda1 swap swap defaults 0 0 /dev/sda2 / ext3 defaults 0 0
Dokonaæ odpowiednich koniecznych operacji konfiguracyjnych w przypadku korzystania z macierzy RAID (plik /etc/mdadm.conf) lub woluminów LVM (/etc/lvm/lvm.conf).
Instalacja kernela
Musimy wybraæ, który kernel zainstalujemy, na początek powinniķmy się zainteresowaæ pakietami: kernel, kernel-grsecurity i ew. ich odmiany z SMP. W wyborze moŋe pomóc nam opis kerneli w sekcja Jądro systemu w rozdziaģ Kernel i urządzenia. Kiedy juŋ wybraliķmy, instalujemy wybrany pakiet:
# poldek --root /pldroot -i kernel |
Bootloader
Jeķli wybraliķmy LILO jako bootloader to powinniķmy odpowiednio zmodyfikowaæ plik konfiguracji (/pldroot/etc/lilo.conf), w przypadku uŋytej w przykģadach konfiguracji będzie wyglądaģ on następująco:
boot=/dev/sda read-only lba32 prompt timeout=100 image=/boot/vmlinuz label=pld root=/dev/sda2 initrd=/boot/initrd |
Kiedy konfiguracja jest skoņczona wydajemy polecenie:
# chroot /pldroot /sbin/lilo |
W przypadku GRUB-a plik konfiguracji (/pldroot/boot/grub/menu.lst) powinien wyglądaæ tak:
timeout 10 title pld root (hd0,1) kernel /boot/vmlinuz boot=/dev/sda initrd /boot/initrd |
# chroot /pldroot /sbin/grub |
grub> root (hd0,1) grub> setup (hd0) grub> quit |
Konfigurację bootloadera wyczerpująco przedstawiono w sekcja Wstęp w rozdziaģ Bootloader. Jeķli gaģąž /boot ma byæ na macierzy to powinniķmy umieķciæ bootloader na wszystkich wchodzących w skģad tej macierzy dyskach, szczegóģy tej operacji przedstawiliķmy w sekcja RAID programowy w rozdziaģ Pamięci masowe.
UDEV
Jeķli chcemy uŋywaæ systemu urządzeņ udev, to jest doskonaģa okazja ŋeby go zainstalowaæ. Podstawowe pakiety wymagają urządzeņ z pakietu dev, dlatego moŋemy go zainstalowaæ dopiero teraz:
# poldek --root /pldroot -i udev # poldek --root /pldroot -e dev |
Konta uŋytkowników
Aby móc się zalogowaæ do nowego systemu musimy nadaæ hasģo dla root-a:
# chroot /pldroot /usr/bin/passwd |
Nic nie stoi na przeszkodzie, ŋeby utworzyæ konta uŋytkowników i skonfigurowaæ uprawnienia. W tym celu posģuŋymy się narzędziami z pakietu shadow lub pwdutils, zanim to jednak zrobimy musimy ustaliæ z jakiej powģoki będą korzystaæ uŋytkownicy. Domyķlnie oba pakiety ustawiają uŋytkownikom powģokę /bin/bash, dlatego przy tworzeniu kont musimy ustawiæ ją na /bin/sh, lub zainstalowaæ Basha.
Zakģadając, ŋe mamy zainstalowanego Basha dodajemy konto uŋytkownika następująco:
# chroot /pldroot /usr/sbin/useradd -m jkowalski |
# chroot /pldroot /usr/bin/passwd jkowalski |
Operacje koņcowe
Przed restartem musimy odmontowaæ systemy plików:
# umount /pldroot/proc # umount /pldroot |
Na koniec wpisujemy polecenie reboot, wyjmujemy pģytę z napędu i czekamy aŋ uruchomi się nowy system.
Aktualizacje
Aktualizacja systemu PLD z RA do AC
Aktualizacja z Ra do Ac
Gdy mamy zainstalowane juŋ na dysku PLD 1.x, aby przejķæ do 2.0 (AC) nie musimy od nowa instalowaæ caģego systemu. Moŋemy posģuŋyæ się skryptem ra2ac. Pakiety z tego skryptu standardowo pobierane są z ftp. Czynnoķcią którą musimy wykonaæ zanim posģuŋymy się skryptem to aktualizacja kernela do wersji 2.4.x. Gotowe pakiety moŋemy pobraæ z dwóch žródeģ w zaleŋnoķci od architektury.
Dla architektur: i686 oraz ppc: ftp://ftp.pld-linux.org/dists/ra/updates/2.4/
Dla architektur: i386, i586, i686: ftp://atos.wmid.amu.edu.pl/pub/pld/ra-24/
Caģa aktualizacja systemu sprowadzi się do uruchomienia skryptu i ręcznej rekonfiguracji nowych wersji usģug.
Naleŋy pamiętaæ, ŋe AC jest na kernelu 2.6, lub 2.4 do wyboru, w tych kernelach nie ma ipchains-ów, zamiast tego jest narzędzie nazywające się iptables. Pomimo iŋ sģuŋy do tego samego, reguģki mają inną skģadnie. W kernelach 2.4 i 2.6 niektóre moduģy urządzeņ inaczej się nazywają, więc na to teŋ naleŋy byæ przygotowanym.
Skrypt jest przeznaczony dla ludzi, którzy wiedzą co robią i mają ogólne pojęcie o linuksie, jeŋeli jesteķ początkującym uŋytkownikiem PLD, to lepszą decyzją będzie od nowa zainstalowanie systemu.
Pierwszym krokiem powinno byæ zrobienie kopii zapasowej plików konfiguracyjnych - najlepiej przekopiowaæ gdzieķ caģy katalog /etc, jeŋeli masz np. postgresa, to waŋne jest abyķ zrzuciģ gdzieķ bazy. O innych waŋnych usģugach i zmianach w konfiguracjach powinniķmy poczytaæ wczeķniej. Wiele nowszych pakietów, stare pliki konfiguracyjne przekopiuje do plików z rozszerzeniem *.old
Zainstalowanego na komputerze kde lub gnome najlepiej jest usunąæ (ģącznie z katalogami i plikami zaczynającymi się od .kde i .gnome w katalogach domowych uŋytkowników) - gdyŋ zmiany są bardzo duŋe i praca ze starymi ustawieniami powoduje często wadliwą prace. Generalnie waŋne jest aby aktualizowaæ jak najmniejszą liczbę pakietów, wtedy wszystko powinno pójķæ w miarę gģadko. Resztę pakietów moŋna póžniej ręcznie doinstalowaæ po aktualizacji.
Teraz pobieramy z cvsu skrypt ra2ac poleceniem:
# cvs -d :pserver:cvs@cvs.pld-linux.org:/cvsroot get raac-converter cvs server: Updating raac-converter U raac-converter/ChangeLog U raac-converter/TODO U raac-converter/ra2ac |
Lub korzystamy z adresu www
Następnie uruchamiamy ra2ac:
# sh raac-converter/ra2ac |
Czekamy aŋ skoņczy się instalowanie pakietów, na przewijające się niespeģnione zaleŋnoķci i bģędy nie zwaŋamy :)
I na samym koņcu najbardziej nieprzyjemna częķæ aktualizacji - konfiguracja. Naleŋy teraz większoķæ usģug jeszcze raz przekonfigurowaæ, częķæ usģug będzie potrzebowaģa tylko przekopiowania konfigu z Ra, jednak inne (np. exim, postfix) wymagają od administratora edycji nowych plików konfiguracyjnych. Waŋne jest ŋeby poczytaæ w dokumentacji o zmianach w plikach konfiguracyjnych między wersjami które mieliķmy w RA, a wersjami występującymi teraz po skoņczeniu dziaģania skryptu.
III. Podręcznik uŋytkownika
- Spis treści
- Podstawy
- Zasoby systemu
Podstawy
W tym rozdziale znajdziesz podstawowe komendy i czynnoķci, które powinieneķ znaæ.
Wstęp
Dokument, który aktualnie czytasz zawiera minimalny zestaw instrukcji i porad koniecnych do instalacji i zarządzania dystrybucją PLD Linux. Większoķæ opisywanych mechanizmów i narzędzi ma o wiele większe moŋliwoķci, aby je poznaæ powinniķmy uŋywaæ podręczników systemowych info i man (przestarzaģy). Aby z nich korzystaæ musisz je zainstalowaæ (o ile nie są juŋ zainstalowane) poleceniami:
poldek -U man poldek -U info |
info {$hasģo} |
Jeķli szukasz prostego narzędzia o konkretnych moŋliwoķciach moŋemy przejrzeæ dokumentację systemową zestawu coreutils:
info coreutils |
Moŋesz równieŋ szukaæ pomocy na listach dyskusyjnych, IRC-u, czy forum. Listę tych jak i wielu innych uŋytecznych adresów odnajdziesz w sekcja Waŋne adresy w rozdziaģ Zasoby sieciowe PLD.
Wģączanie i wyģączanie systemu
Tradycyjną metodą wyģączania komputera jest komenda shutdown, np.:
# shutdown -h now |
Lub poweroff dająca ten sam efekt.
Uŋycie komendy halt jest teŋ wģaķciwe.
# halt |
Aby zresetowaæ system wpisujemy reboot albo korzystamy z kombinacji klawiszy CTRL+ALT+DEL.
W trakcie pracy moŋemy dowolnie przeģączaæ się pomiędzy trybami pracy. Sģuŋy do tego polecenie init {$nr} ({$nr} to liczba oznaczająca tryb pracy) np.
# init 5 |
Zmianę poziomu pracy szerzej opisano tutaj: sekcja Zmiana poziomu pracy systemu w rozdziaģ Administracja
Podstawowe operacje na plikach i katalogach
Zawartoķæ plików wyķwietlamy poleceniem cat.
$ cat archiwum |
Jeķli chcemy przyjrzeæ się plikowi, który nie mieķci się na ekranie po wykonania cat moŋemy uzyskaæ poleceniem less. Moŋemy wtedy przeglądaæ plik uŋywając "strzaģek", a kiedy skoņczymy - naciskamy q.
$ less plik |
Komendą touch moŋemy modyfikowaæ znaczniki czasu pliku, częķciej jednak uŋywa się jej do tworzenia pustych plików.
$ touch pusty_plik |
Polecenie mkdir tworzy katalog.
$ mkdir archiwum |
Za pomocą polecenia rmdir usuwamy puste katalogi.
$ rmdir archiwum |
Plik moŋemy przenieķæ, albo zmieniæ jego nazwę, za pomocą polecenia mv.
$ mv listing listing.old $ mv /home/listing.old /usr/src/ |
W podobny sposób operujemy na katalogach.
$ mv archiwum smietnik $ mvdir smietnik /usr/src/smietnik/ |
Do kopiowania sģuŋy polecenie cp.
$ cp listing podkatalog/ |
Kasujemy poleceniem rm.
$ rm plik // Kasuje plik. $ rm * // Kasuje wszystkie pliki w danym katalogu. $ rm * -i // Kasuje wszystkie pliki w danym katalogu z potwierdzeniem. $ rm * -f // Kasuje wszystkie pliki w danym katalogu bez pytania. $ rm -r // Kasuje wszystkie pliki, takŋe te w podkatalogach $ rm -rf /home/ // Kasuje wszystkie pliki i katalogi w katalogu /home/ |
Poruszanie się w drzewie katalogów
Do poruszania się w drzewie katalogów w trybie tekstowym moŋna uŋywaæ programu Midnight Commander uruchamianego poleceniem mc, jednak nie kaŋdy go instaluje, więc warto zapoznaæ się z kilkoma poleceniami przedstawionymi w tym rozdziale.
Do poruszania się w drzewie katalogów uŋywamy polecenia cd ķcieŋka np.:
$ cd /home/users/zenek/ |
Ten sam efekt uzyskamy poleceniem
$ cd users/zenek/ |
wykonanym w katalogu /home
Kilka innych przykģadów przedstawiamy poniŋej.
W systemach uniksowych wyróŋniamy kilka rodzajów specjalnych katalogów. Najwaŋniejszym w caģym drzewie jest katalog gģówny -korzeņ (ang. root) oznaczany przez ukoķnik: "/"
$ cd / |
Często po lewej stronie ķcieŋki podaje się korzeņ aby wskazaæ poģoŋenie katalogu lub pliku bez względu na miejsce z którego wydajemy polecenie np.:
$cd /etc/sysconfig |
Polecenie ls powoduje wyķwietlenie zawartoķci katalogu. Naleŋy po nim podaæ nazwę katalogu, który chcemy zobaczyæ, w przeciwnym wypadku wyķwietlona zostanie zawartoķæ katalogu bieŋącego.
$ls / bin dev home lib mnt proc sbin srv tmp var boot etc initrd media opt root selinux sys usr $cd /home $ls services users |
Parametr -a powoduje, ŋe funkcja pokazuje równieŋ pliki ukryte (zaczynające się od kropki). -R powoduje wylistowanie równieŋ podfolderów.
Polecenie pwd powoduje wyķwietlenie ķcieŋki bieŋącego katalogu.
$cd users/bart $pwd /home/users/bart/ |
Waŋnym katalogiem jest katalog domowy uŋytkownika - oznaczany znakiem tyldy (~). Kaŋdy uŋytkownik moŋe uŋywaæ w ķcieŋce tego znaku i zawsze będzie oznaczaģ jego wģasny katalog domowy np.:
$ ls ~/dokumenty |
Kolejnym takim katalogiem jest katalog nadrzędny oznaczany za pomocą dwóch kropek. Będąc w katalogu: /home/users/zenek moŋemy przejķæ o jeden poziom do góry uŋywając polecenia
cd .. |
Dzięki temu znajdziemy się w katalogu /home/users.
Data i czas
By wyķwietliæ aktualny czas i datę systemową posģugujemy się komendą date:
$ date sob kwi 26 23:48:33 CEST 2003 |
Czas dziaģania komputera sprawdzamy komendą uptime.
$ uptime 5:27pm up 6:51, 4 users, load average: 0.32, 0.08, 0.02 |
W sytuacji gdy chcemy z zmierzyæ czas potrzeby na wykonanie operacji/czynnoķci/procesu to posģugujemy się komendą time.
$ time find /home/users/rennis/ HELLO real 0m13.297s user 0m0.060s sys 0m0.230s |
Przykģad ten poszukuje pliku HELLO w moim katalogu domowym, co zajmuje systemowi ~13s.
Edycja plików konfiguracyjnych
W systemach z rodziny UNIXa konfiguracja systemu jest przechowywana w plikach tekstowych. Zaletą tego rozwiązania jest moŋliwoķæ konfigurowania systemu przy pomocy bardzo prostych narzędzi, wadą zaķ to ŋe moŋna ģatwo popeģniæ bģąd. Dlatego jeķli chcemy tylko przeglądaæ plik powinniķmy uŋyæ programu less np.:
# less /etc/poldek/poldek.conf |
Jeķli jesteķmy pewni ŋe chcemy dokonaæ zmian, powinniķmy wczeķniej wykonaæ kopię zapasową pliku (pliki kopii zapasowej koņczy się tyldą).
# cp /etc/poldek/poldek.conf /etc/poldek/poldek.conf~ |
Teraz moŋemy zacząæ modyfikowaæ plik, domyķlnie instalowanym edytorem plików jest vim, dlatego dobrze jest umieæ się nim posģugiwaæ choæby w podstawowym zakresie. Bardzo uŋyteczną cechą Vima jest kolorowanie skģadni podstawowych plików konfiguracji (o ile nasz terminal jest kolorowy), dzięki czemu ģatwo moŋemy zauwaŋyæ ewentualne bģędy.
Aby otworzyæ nim plik do edycji wydajemy polecenie
# vim /etc/poldek/poldek.conf |
Początkującym moŋna zaproponowaæ edytor mcedit będący częķcią programu mc (Midnight Commander), inne nieco mniej popularne edytory to: emacs, pico, joe
Naleŋy pamiętaæ o tym, ŋe prawo zapisu plików w katalogu konfiguracji systemu (/etc) ma tylko superuŋytkownik (root) i z takimi uprawnieniami naleŋy uruchamiaæ edytor. Pliki konfiguracyjne w linuksie muszą koņczyæ się znakiem nowej linii, dlatego przed zapisem naleŋy pamiętaæ o sprawdzeniu czy jest wstawiony. Po raz kolejny swoją przewagę nad innymi edytorami pokazuje Vim, który automatycznie wstawia znak nowej linii.
Podstawowe narzędzia kontroli sieci TCP/IP
Aby uŋywaæ przedstawionych tu programów, naleŋy mieæ uprawnienia superuŋytkownika lub byæ zapisanym do odpowiedniej grupy. Listę grup i odpowiadających im uprawnieņ zamieszczono w sekcja Zarządzanie uprawnieniami w rozdziaģ Administracja. Bardziej zaawansowane narzędzia sieciowe opisano w sekcja Narzędzia sieciowe w rozdziaģ Zastosowania sieciowe.
Ping
Najczęķciej uŋywanym narzędziem diagnostycznym jest program ping - pozwala on zbadaæ istnienie poģączenia między dwoma komputerami, drogę pomiędzy nimi, czas potrzebny na przejķcie pakietu oraz sprawdza czy drugi komputer pracuje w danym momencie w sieci. Przy okazji ping dokonuje tģumaczenia adresu domenowego na numer IP. Program ten jest przydatny do okreķlania stanu sieci i okreķlonych hostów, ķledzenia i usuwania problemów sprzętowych, testowania, mierzenia i zarządzania siecią, oraz do badania sieci. Polecenie ping {$nazwa/$numer_IP} wysyģa specjalne pakiety ICMP do wskazanego komputera i czeka na odpowiedž. Moŋemy podawaæ jako cel adres domenowy lub numer IP. Przy okazji program ten dokonuje tģumaczenia adresu domenowego na numer IP.
$ ping pld-linux.org PING pld-linux.org (81.0.225.27) 56(84) bytes of data. 64 bytes from 81.0.225.27: icmp_seq=1 ttl=44 time=135 ms 64 bytes from 81.0.225.27: icmp_seq=2 ttl=44 time=99.8 ms 64 bytes from 81.0.225.27: icmp_seq=3 ttl=44 time=149 ms --- pld-linux.org ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2001ms rtt min/avg/max/mdev = 99.840/128.084/149.144/20.761 ms |
pracę programu przerywamy skrótem ctrl+c
Na powyŋszym wydruku przedstawiono 3 odpowiedzi na wysģane pakiety. Jeden wiersz oznacza odpowiedž na jeden pakiet, dla kaŋdego z nich podawane są parametry trasy pomiędzy komputerami. Najistotniejszym parametrem jest czas odpowiedzi (time). W przypadku problemów z siecią częķæ pakietów moŋe zostaæ zagubiona, będzie wskazywane przez specjalny licznik (icmp_seq) oraz przez koņcowe statystyki. Brak jakiejkolwiek odpowiedzi moŋna interpretowaæ jako brak poģączenia sieciowego z interesującym nas komputerem, blokadę tego typu pakietów na komputerze zdalnym lub zwyczajne wyģączenie maszyny. Na koņcu wyķwietlane są dodatkowo szczegóģowe statystyki. Przy prawidģowym poģączeniu czas odpowiedzi dla sieci lokalnej zazwyczaj nie przekracza 1 ms zaķ w internecie moŋe sięgnąæ nawet kilkuset ms.
Komenda moŋe daæ równieŋ efekt podobny do poniŋszego:
[root@g82 ~]# ping google.pl PING google.pl (216.239.57.99) 56(84) bytes of data. From 192.168.6.1 icmp_seq=1 Packet filtered From 192.168.6.1 icmp_seq=2 Packet filtered --- google.pl ping statistics --- 2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 1000ms |
Moŋe to oznaczaæ, ŋe w naszej sieci zabronione jest wysyģanie pingów poza LAN.
Traceroute
Nieco bardziej zaawansowanym programem jest traceroute. Pokazuje on trasę jaką przechodzą pakiety między naszym komputerem, a sprawdzanym przez nas hostem. Wskazuje on czasy przesģania pakietów pomiędzy sąsiadującymi ze sobą routerami (tzw. czasy przeskoków), znajdującymi się na trasie poģączenia dwóch maszyn. Pozwala ķledziæ trasę pakietów oraz wykrywaæ róŋnego rodzaje problemy w sieciach np.: bģądzenie pakietów w sieci, "wąskie gardģa" sieci, oraz awarie poģączeņ.
$ traceroute pld-linux.org traceroute to pld-linux.org (81.0.225.27), 30 hops max, 38 byte packets 1 192.168.1.1 (192.168.1.1) 0.295 ms 0.608 ms 0.484 ms 2 217.153.188.173 (217.153.188.173) 1.012 ms 0.648 ms 0.495 ms 3 217.8.190.153 (217.8.190.153) 30.894 ms 28.983 ms 29.719 ms |
Jak widaæ, polecenie to wypisuje linie zawierające TTL, adres bramki oraz czas przebycia kaŋdej z próbek z róŋnych gatewayów. Jeķli nie byģo odpowiedzi w ciągu trzech sekund to dla próbki drukowane jest '*'
MTR
Godnym uwagi programem jest MTR, jest narzędziem ģączącym funkcje opisanych wczeķniej programów. Program ten ķledzi trasę poģączenia między dwoma punktami podobnie jak traceroute i odķwieŋa wyniki w regularnych odstępach czasu.
$ mtr pld-linux.org |
Proxy
Zdarza się, ŋe chcemy lub musimy korzystaæ z serwera poķredniczącego (proxy), w tym celu trzeba wskazaæ programowi jego adres i port. Konfiguracja proxy w GNU/Linuksie zaleŋy od programu klienckiego i moŋe byæ wykonana na jeden z trzech sposobów, oto ich lista:
zmienne ķrodowiskowe - z nich korzystają gģównie programy dziaģające w trybie znakowym np.: lynx, wget, poldek. Definiujemy je następująco: {$protokóģ}_proxy np. serwer proxy dla FTP wskazujemy za pomocą zmiennej ftp_proxy zaķ dla HTTP za pomocą http_proxy np.:
Są programy, które akceptują nazwy tych zmiennych napisanych wyģącznie wielkimi literami, tak więc dla wygody i pewnoķci moŋemy zdefiniowaæ obie wersje. Więcej o zmiennych ķrodowiskowych znajdziemy w sekcja Zmienne ķrodowiskowe w rozdziaģ Konfiguracja systemu.export ftp_proxy=w3cache.dialog.net.pl:8080
opcje programu - wiele bardziej rozbudowanych aplikacji uŋywa wģasnej konfiguracji proxy. Są to przewaŋnie programy dla ķrodowiska X-Window np.: gFTP, Firefox, Opera.
konfiguracja ķrodowiska - programy ķciķle związane ze ķrodowiskami graficznymi Gnome lub KDE uŋywają ustawieņ tychŋe ķrodowisk. Do tego typu programów naleŋą np.: Epiphany, Konqueror.
Zasoby systemu
Tutaj opisano sposób badania zasobów systemu operacyjnego.
Iloķæ miejsca na dysku
Wiele poleceņ zwracających wielkoķci zajmowanej pamięci obsģuguje parametr -h przedstawiający wielkoķci w jednostkach bardziej wygodnych dla czģowieka.
Komenda df sģuŋy do pokazania iloķci miejsca na zamontowanych partycjach.
$ df -h System plików rozm. uŋyte dost. %uŋ. zamont. na /dev/hdc1 36G 5.6G 29G 16% / |
Natomiast komendą du moŋna sprawdzaæ objętoķæ plików oraz caģych katalogów. Uruchomienie du -h wyķwietli listę plików, katalogów i ich objętoķci (z bieŋącego katalogu)
$ du -h 4.1kB ./archiv/httpd 4.1kB ./archiv/mysql 4.1kB ./archiv/exim 17kB ./archiv 4.1kB ./httpd 4.1kB ./mysql 111kB ./exim 107kB ./ircd 4.1kB ./mail 2.1MB . |
Za pomocą opcji -s uzyskamy sumę objętoķci
wszystkich plików
$ du -sh /bin 3,4M /bin |
Procesy i zasoby
Listę wszystkich uruchomionych procesów oraz dotyczące ich dane otrzymamy dzięki poleceniu ps
$ ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1350 0.0 0.1 1788 868 ? Ss May27 0:00 syslog-ng zenek 2252 0.0 1.2 11316 6668 ? Ss May27 0:01 xfce4-session root 2301 0.0 0.3 2748 1556 tty2 Ss May27 0:00 -bash |
Oraz w formie drzewa procesów rodziców i procesów potomnych
$ ps xf PID TTY STAT TIME COMMAND 2459 ? S 0:32 xmms 2460 ? S 0:00 \_ xmms 2461 ? S 0:00 \_ xmms 2465 ? S 0:00 \_ xmms 2816 ? S 0:00 \_ xmms |
W przypadku potrzeby ciągģego ķledzenia zmian w systemie moŋemy uŋyæ programu top. Program ten pokazuje najbardziej zasoboŋerne procesy. Dodatkowo na bieŋąco wyķwietla caģkowite zuŋycie procesora (CPU), pamięci operacyjnej(Mem) oraz zajętoķæ przestrzeni wymiany (Swap).
$ top top - 01:38:54 up 3:28, 4 users, load average: 0.10, 0.08, 0.08 Tasks: 63 total, 2 running, 61 sleeping, 0 stopped, 0 zombie Cpu(s): 2.3% us, 1.3% sy, 0.0% ni, 96.1% id, 0.0% wa, 0.3% hi, 0.0% si Mem: 516244k total, 440344k used, 75900k free, 11840k buffers Swap: 1076312k total, 0k used, 1076312k free, 328012k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2240 root 15 0 62644 24m 45m S 1.6 4.9 7:37.40 X 2892 zenek 16 0 1880 928 1672 R 0.6 0.2 0:00.05 top 2695 zenek 16 0 6532 3824 5056 R 0.3 0.7 0:01.63 xterm 1 root 16 0 1532 584 1372 S 0.0 0.1 0:00.82 init |
Informacje o samej pamięci i przestrzeni wymiany uzyskamy dzięki komendzie free
$ free
total used free shared buffers cached
Mem: 516244 445536 70708 0 11880 332728
-/+ buffers/cache: 100928 415316
Swap: 1076312 0 1076312
|
Caģkowita iloķæ zuŋytej pamięci (razem z buforami dyskowymi) mieķci się w pierwszym wierszu w kolumnie USED. Zaķ iloķæ pamięci zuŋytej jedynie przez programy mieķci się w drugim wierszu w tej samej kolumnie.
Do ķledzenia zmian zuŋycia zasobów systemu w funkcji czasu warto poleciæ program vmstat z liczbą sekund w parametrze. Podany czas jest odstępem pomiędzy pomiarami, program pokazuje zmiany w wykorzystaniu pamięci, obszaru wymiany, czasu procesora, przerwaņ czy wielkoķci transferu do i z urządzeņ masowych:
# vmstat 2 procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 0 0 0 276896 980 89812 0 0 377 6 482 818 6 2 90 1 0 0 0 276780 980 89816 0 0 0 0 456 770 0 0 100 0 0 0 0 276772 980 89816 0 0 0 28 461 846 0 0 100 0 |
Do procesów których jesteķmy wģaķcicielami moŋemy wysyģaæ sygnaģy (root moŋe wysģaæ sygnaģ do kaŋdego procesu). Aby zakoņczyæ jakiķ proces naleŋy do procesu wysģaæ sygnaģ TERM. Dokonuje się tego poleceniem kill lub killall. Pierwsze zabija proces o podanym numerze PID (unikalnym identyfikatorze procesu) np.:
$ kill 2901 |
Drugie z poleceņ zabija wszystkie procesy, które mają podaną nazwę np.:
$ killall xmms |
Sygnaģ TERM moŋe byæ nieskuteczny w niektórych wypadkach, wtedy naleŋy uŋyæ bardziej brutalnej metody - sygnaģu KILL. Moŋemy go wysģaæ programem kill lub killall z odpowiednim parametrem: "-9" lub "-KILL":
kill -9 2901 |
W systemach uniksowych moŋna ustawiaæ priorytety uruchamianym programom bądž teŋ modyfikowaæ bieŋący priorytet dziaģającego procesu. Priorytet jest nazywany jest "liczbą nice". Mówi ona jak mili jesteķmy dla systemu i innych uŋytkowników. Priorytet moŋemy ustawiaæ od -20 do +19, przy czym domyķlna wartoķæ zazwyczaj wynosi 0. Ujemne wartoķci oznaczają wyŋszy priorytet, zaķ dodatnie niŋszy. Ujemną wartoķæ moŋe nadaæ tylko superuŋytkownik.
Aby uruchomiæ proces z priorytetem innym niŋ domyķlny naleŋy uŋyæ programu nice np.:
$ nice -n +5 mc |
Dziaģającym procesom moŋna zmieniaæ priorytet. Aby to zrobiæ uŋywamy polecenia renice:
$ renice +5 mc |
Jak sprawdziæ kto jest zalogowany oprócz nas?
Pierwszą komendą jest who. Podaje ona nam nazwę uŋytkownika, terminal na którym jest zalogowany oraz czas rozpoczęcia pracy.
$ who gozda tty1 Apr 18 10:52 gozda pts/1 Apr 18 16:21 gozda pts/4 Apr 18 11:06 gozda pts/6 Apr 18 14:46 gozda pts/8 Apr 18 16:25 gozda pts/9 Apr 18 18:25 gozda pts/10 Apr 18 18:29 |
Kolejna komenda w pokazuje nam kto jest zalogowany i co robi na poszczególnych sesjach.
$ w 6:56pm up 8:05, 7 users, load average: 1.94, 1.75, 1.61 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT gozda tty1 - 10:52am 8:03m 16.67s 0.02s sh /usr/X11R6/bin/startx gozda pts/1 - 4:21pm 6:45 5.37s 5.32s irssi gozda pts/4 - 11:06am 37:46 3.22s 3.17s ekg gozda pts/6 - 2:46pm 10:17 12.66s 1.08s mp3blaster gozda pts/9 - 6:25pm 0.00s 0.12s 0.03s w gozda pts/10 - 6:29pm 22:07 3:58 0.02s ./mozilla-bin |
Komenda users. Pokazuje ona pseudonimy uŋytkowników zalogowanych w systemie.
$ users gozda gozda gozda gozda gozda gozda gozda |
Poleceniem whoami dowiadujemy się, jak nazywa się uŋytkownik, na którym pracujemy.
$ whoami gozda |
IV. Podręcznik administratora
Zarządzanie pakietami
Ten rozdziaģ opisuje metody zarządzania pakietami w systemie PLD.
Informacje podstawowe
Wstęp
Instalowanie, deinstalowanie oraz aktualizowanie skģadników systemu operacyjnego to jedne z najwaŋniejszych zadaņ administratora. Zautomatyzowanie tych procesów pozwala na znaczne przyspieszenie i uģatwienie zarządzania systemem.
W ķwiecie Otwartego Oprogramowania pomiędzy programami istnieją liczne powiązania, które w efekcie wymuszają koniecznoķæ instalacji dodatkowych programów i/lub bibliotek. Pominięcie tych zaleŋnoķci spowoduje problemy z dziaģaniem programu lub caģkowity jego brak. Ķledzenie tych zaleŋnoķci moŋe przyprawiæ o ból gģowy większoķæ administratorów. Na szczęķcie istnieją mechanizmy i narzędzia, które pomagają znacznie zautomatyzowaæ ten proces.
Pakiety w PLD
Elementy systemu operacyjnego dostępne są w tzw. pakietach (pot. "paczkach"). W PLD zastosowano system pakietów RPM (RPM Packet Manager), który zostaģ stworzony przez twórców dystrybucji Red Hat Linux. Istnieje moŋliwoķæ instalacji pakietów RPM przygotowanych dla innych dystrybucji, jednak nie skorzystamy wtedy z dobrodziejstwa zaleŋnoķci dotyczących danego pakietu. Wymagane dodatkowe pakiety naleŋy wtedy zainstalowaæ samodzielnie.
Menadŋery pakietów
Do zarządzania pakietami (instalacja, deinstalacja, uzyskiwanie informacji) uŋywa się specjalnych programów zwanych menadŋerami pakietów:
Poldek
Poldek to domyķlny menadŋer pakietów dla PLD. Jest nakģadką na RPM-a o ogromnych moŋliwoķciach, pozwalającym na znaczną automatyzację procesu zarządzania duŋymi iloķciami pakietów. Jest "woģem roboczym" odciąŋającym administratora w jego ŋmudnym zajęciu. Konfigurację i opis Poldka przedstawiono w sekcja Poldek.
PackageKit
Prosty zarządca pakietów, dla ķrodowiska X-Window. Zostaģ stworzony pierwotnie dla Gnome, ma takŋe wersję dla Qt. Jest to wygodne narzędzie, dobrze sprawujące się przy zrządzaniu niewielkimi iloķciami pakietów. PackageKit wyķwietla na tacce systemowej dostępnoķæ aktualizacji. PackageKit jest ķwietnym wyborem dla zupeģnie niezaawansowanych uŋytkowników.
RPM
Niskopoziomowy zarzdca pakietów, uŋywany zwykle w nietypowych i awaryjnych sytuacjach. Opis posģugiwania się tym programem zamieszczono w sekcja RPM.
Pobieranie pakietów
Jedną z najczęķciej uŋywanych form instalacji jest instalacja z sieci, dlatego jeķli nie zostanie podane inaczej to wģaķnie taka instalacja jest traktowana jako domyķlna. Uŋywamy tej metody nawet jeķli system byģ instalowany z lokalnego žródģa (np. z dysku), choæby w celu aktualizacji systemu.
Menadŋery pakietów są wstępnie skonfigurowane, Aby jednak instalowaæ niestandardowe pakiety lub uŋyæ innego žródģa, musimy podaæ odpowiednie parametry. Konfiguracja w tym zakresie jest opisana w sekcja Serwery z pakietami w rozdziaģ Zasoby sieciowe PLD.
Cechy pakietów w PLD
Zaleŋnoķci między pakietami
Istotną cechą pakietów RPM jest mechanizm tzw. zaleŋnoķci, dzięki nim w trakcie instalacji pakietu instalowane są automatycznie dodatkowe wymagane pakiety. Niekiedy w ramach zaleŋnoķci wymagana jest funkcjonalnoķæ dostarczana przez więcej niŋ jeden pakiet. W takim wypadku zostaniemy zapytani o to który pakiet ma byæ zainstalowany. Wynika to z filozofii PLD, która dopuszcza bogaty wybór oprogramowania speģniającego tą samą rolę.
Istnieją zaleŋnoķci wymagające wzajemnego wykluczania się pakietów, tak aby w systemie byģa zainstalowany byģ tylko jeden program z poķród kilku dostępnych. Jako przykģad moŋna wskazaæ serwery usģug tego samego rodzaju lub pakiety zawierające w nazwie sģowa "inetd" oraz "standalone".
Dodatkowo system pakietów pilnuje, aby nie moŋna byģo mieæ zainstalowanych dwóch wersji tego samego pakietu. Próba instalacji pakietu starszego niŋ ten, który mamy w systemie zakoņczy się niepowodzeniem, zaķ przy instalacji nowszego nastąpi jego aktualizacja.
Menadŋery pakietów pozwalają na ignorowanie powyŋszych zaleŋnoķci, jest to jednak operacja nie zalecana, gdyŋ powoduje póžniej trudny do ogarnięcia baģagan. Wyjątki od tej zasady powinny byæ robione jedynie w razie uzasadnionej koniecznoķci, takim przypadkiem jest np. aktualizacja kernela, operacja ta zostaģa opisana w sekcja Jądro systemu w rozdziaģ Kernel i urządzenia.
Dawniej zaleŋnoķci byģy budowane na podstawie nazw pakietów, w tej chwili stopniowo wprowadzane są zaleŋnoķci na podstawie plików (programów, bibliotek itd.). Zyskujemy w ten sposób elastycznoķæ kosztem wygody w niektórych, rzadko spotykanych sytuacjach. W przypadku codziennej pracy z pakietami, nie odczujemy większych róŋnic i nie musimy się tym martwiæ.
Wymagania (requires) i wģasnoķci (provides)
Waŋnymi elementami mechanizmu zaleŋnoķci są tzw. wymagania i wģasnoķci. Pierwsza z cech wskazuje listę wymaganych dodatkowo elementów (pakietów, plików) do dziaģania instalowanej aplikacji, druga zaķ informuje, które z elementów są dostarczane wraz z pakietem. Aby poznaæ wymagania pakietu posģuŋymy się Poldkiem w trybie interaktywnym:
poldek:/all-avail> desc -r logrotate
Package: logrotate-3.7-2
PreReqs: /bin/sh, fileutils
Requires: /bin/mail, /bin/sh, config(logrotate) = 3.7-2, crondaemon,
glibc, libc.so.6, libc.so.6(GLIBC_2.0), libc.so.6(GLIBC_2.1),
libc.so.6(GLIBC_2.2), libc.so.6(GLIBC_2.3), libpopt.so.0, libselinux,
libselinux.so.1, popt
RPMReqs: rpmlib(CompressedFileNames) <= 3.0.4-1,
rpmlib(PayloadFilesHavePrefix) <= 4.0-1,
rpmlib(PayloadIsBzip2) <= 3.0.5-1 |
Sprawa nieco komplikuje się w przypadku wģasnoķci, poniewaŋ w PLD nierzadko mamy dostępnych wiele pakietów speģniających podobne wymagania. Aby sprawdziæ dostarczaną funkcjonalnoķæ ponownie uŋyjemy Poldka:
poldek:/all-avail> desc -p vixie-cron
Package: vixie-cron-4.1-7
Provides: config(vixie-cron) = 4.1-7, crondaemon, crontabs >= 1.7,
group(crontab) |
Wģasnoķæ crondaemon jest dostarczana przez większą iloķæ pakietów, moŋemy samodzielnie wybieraæ, który z pakietów ma byæ instalowany lub ustawiæ automatyczny wybór. O tym decyduje ustawienie opcji choose equivalents manually w konfiguracji Poldka. Jeķli ustawimy opcję na yes (zalecane) to instalacja programu moŋe wyglądaæ następująco:
poldek:/all-avail> install logrotate
Przetwarzanie zaleŋnoķci...
Więcej niŋ jeden pakiet udostępnia wģaķciwoķæ "crondaemon":
a) anacron-2.3-22
b) fcron-3.0.0-3
c) hc-cron-0.14-22
d) vixie-cron-4.1-7
Which one do you want to install ('Q' to abort)? [b] |
Zawartoķæ pakietów
Pakiety mogą zawieraæ wiele maģych programów i/lub bibliotek albo jeden duŋy program moŋe byæ podzielony na kilka pakietów. W PLD najczęķciej stosowane jest to drugie rozwiązanie: osobno przechowywane są pliki uruchomieniowe, osobno biblioteki, a jeszcze osobno moduģy, wtyczki i dodatki. Ponadto jeķli tylko moŋna to są umieszczane w pojedynczych pakietach, dzięki temu unikamy duŋych, zbiorczych paczek. Pozwala to instalowaæ tylko to co jest nam potrzebne. Przykģadowo jeķli program ABC wymaga bibliotek programu XYZ to instalujemy tylko pakiet z bibliotekami tego drugiego. Skraca to czas instalacji (zwģaszcza przy pobieraniu plików z Internetu) i pozwala oszczędzaæ miejsce na dysku.
Nierzadko do osobnych pakietów trafiają elementy aplikacji, które zostaģy przewidziane przez jej twórców jako kompletna instalacja. Nie naleŋy się tego obawiaæ, gdyŋ mechanizm zaleŋnoķci wymusi instalację wszystkich wymaganych dodatkowo pakietów.
Tak silne rozdrobnienie powoduje czasami, ŋe do przy instalacji mechanizm zaleŋnoķci zaznacza sporą iloķæ dodatkowych pakietów. Potrafi to wprowadziæ w konsternację, jednak nie naleŋy się tego obawiaæ, gdyŋ są to zazwyczaj maģe pakiety i po zainstalowaniu zajmują tyle samo lub mniej niŋ domyķlna instalacja.
Aby uģatwiæ poruszanie się w tym gąszczu, moŋemy posģuŋyæ się opisami pakietów:
poldek:/all-avail> desc proftpd-inetd |
poldek:/all-avail> desc -f proftpd-inetd |
poldek:/all-avail> search -f */sendmail |
Konwencja nazw pakietów w PLD
Nazwy pakietów mają następującą budowę: {$nazwa}-{$wersja}.{$arch}.rpm np.: 0verkill-0.16-3.i686.rpm. Tak wyglądają nazwy pakietów w systemie plików lub na serwerze FTP. W menedŋerach pakietów posģugujemy się jedynie nazwą lub nazwą i wersją (nie licząc instalacji za pomocą rpm-a).
Tabela 1. Opis zawartoķci pakietów w zaleŋnoķci od ich nazwy
| Nazwa pakietu | Zawartoķæ |
|---|---|
| program, program-core | gģówny pakiet programu, zawiera pliki wykonywalne, dokumentację, skrypty startowe w przypadku usģug, niekiedy biblioteki |
| program-common | podstawowe, wspólne pliki; zwykle samodzielny taki pakiet jest bezuŋyteczny i wymaga zainstalowania dodatkowych pakietów |
| program-libs | zestaw bibliotek stworzonych na potrzeby danego programu, są niekiedy wymagane przez inne programy |
| program-tools, program-utils, program-progs | dodatkowe narzędzia, zwykle nie są konieczne do podstawowej pracy programu |
| program-extras | dodatkowe, rzadziej uŋywane elementy |
| program-mod, program-plugin, program-applets, program-addon | róŋnej maķci moduģy, "wtyczki", applety i dodatki przewaŋnie nie są konieczne do podstawowej pracy programu |
| program-skin(s), program-theme(s) | "skórki" i "tematy" modyfikujące wygląd programu |
| program-driver | sterowniki |
| program-backend | specjalne interfejsy sģuŋące do rozszerzania moŋliwoķci programu, ģączenia z innymi programami, sprzętem itp. |
| program-i18n | dodatkowe wersje językowe |
| program-doc | dokumentacja programu |
| program-devel | pakiety potrzebne dla programistów i osób które zajmują się wģasnoręczną kompilacją programów, bądž budowaniem pakietów. |
| program-static | program skompilowany statycznie - nie wymaga bibliotek |
| program-debuginfo | informacje dla debuggera - pliki uŋyteczne tylko dla osób badających problemy z dziaģaniem programu |
| lib_nazwa_biblioteki | zestaw uniwersalnych bibliotek, nie związanych z ŋadnym konkretnym programem. |
| usģuga-inetd, usģuga-standalone | alternatywne pakiety sģuŋące do wyboru trybu pracy niektórych usģug. Naleŋy wybraæ jeden z nich: uruchamianie przez Inetd lub praca w tle (standalone). Pakiety te wzajemnie się wykluczają na poziomie mechanizmu zaleŋnoķci. |
| usģuga-init | skrypty startowe programu |
| metapackage-program | metapakiet |
| program-legacy | starsze wersje programów lub sterowniki do starszych urządzeņ |
| kernel | pakiety okoģokernelowe, zostaģy omówione w sekcja Jądro systemu w rozdziaģ Kernel i urządzenia |
Metapakiety
Wadą silnego rozdrobnienia pakietów jest pracochģonne zarządzanie, aby temu zaradziæ stworzono tzw. metapakiety, zwane równieŋ pakietami wirtualnymi. Są to pakiety zawierający jedynie wymagania (requires), nie zawierają ŋadnych plików, ani wģasnoķci (provides). Ich zadaniem jest zautomatyzowana instalacja większych grup pakietów oraz utrzymanie wstecznej zgodnoķci w nazwach.
Częķæ metapakietów ģatwo odnajdziemy dzięki nazwie,
która zawiera sģowo metapackage,
np. metapackage-gnome. Aby poznaæ
listę wymagaņ takiego pakietu, uŋyjemy opisanego nieco
wczeķniej polecenia desc -r trybu
interaktywnego Poldka.
Komunikaty
Prace przy zarządzaniu pakietami niekiedy koņczą się komunikatami skierowanymi do administratora, są to doķæ waŋne informacje, dlatego powinniķmy je uwaŋnie czytaæ. Zazwyczaj dotyczą plików konfiguracji, zarządzania uŋytkownikami/grupami, modyfikacji systemu rc-skryptów oraz zalecenia dalszego postępowania po instalacji pakietu. Dla przykģadu poniŋej przedstawiono komunikaty wyķwietlane po instalacji Exim-a:
Adding group exim GID=79. Adding user exim UID=79. Run "/etc/rc.d/init.d/exim start" to start exim daemon. |
Wpģyw pakietów na pracę systemu
Pakiety, oprócz plików programu, zawierają dokumentację, przykģadowe pliki konfiguracji, strony podręcznika systemowego (man, info) oraz automatykę. Owa automatyka jest uruchamiana w trakcie instalowania bądž odinstalowania pakietu i wykonuje konieczne prace w systemie, dzięki czemu zmniejsza się nakģad pracy administratora do absolutnego minimum. Jest tak skonstruowana, aby nie zaskakiwaæ administratora w najmniej oczekiwanych momentach oraz zapewniæ nieprzerwanie dziaģanie systemu, poniŋej przedstawiono kilka przykģadów jej dziaģania.
Jeķli instalujemy w systemie jakąķ usģugę to zostanie zapisana odpowiednia informacja do skryptów startowych i nowe oprogramowanie uruchomi się przy najbliŋszej zmianie trybu pracy lub restarcie systemu. Jeŋeli jakaķ usģuga jest wyģączona z dziaģania i nastąpi jej aktualizacja, to w dalszym ciągu nie będzie uruchamiana.
Jeķli dziaģa usģuga, a my ją zaktualizujemy lub doinstalujemy dodatkowy moduģ, to zostanie ona automatycznie zrestartowana lub taka operacja zostanie zasugerowana przez pakiet. Będzie to zaleŋaģo od ustawienia opcji RPM_SKIP_AUTO_RESTART w konfiguracji rc-skryptu lub globalnie w /etc/sysconfig/rpm - opcja przyjmuje wartoķæ yes/no. Konfigurację rc-skryptów dokģadniej omówiono w sekcja Zarządzanie podsystemami i usģugami w rozdziaģ Administracja.
Wpģyw pakietów na pliki konfiguracji
Po aktualizacji pakietu nie są naruszanie istniejące pliki konfiguracji, nowe wersje tych plików są zapisywane z rozszerzeniem ".rpmnew". Przykģadowo po zaktualizowaniu pakietu sudo obok pliku /etc/sudoers pojawi się nowy plik o nazwie /etc/sudoers.rpmnew, tak więc zaktualizowany program będzie uŋywaģ starego pliku konfiguracji. W większoķci wypadków nie będzie to stanowiæ problemu, jednak dla pewnoķci naleŋy skonfigurowaæ plik dostarczony z nowszym pakietem na wzór poprzedniej konfiguracji i zmieniæ mu nazwę poprzez usunięcie omawianego rozszerzenia. Jest to pierwsza rzecz, którą naleŋy sprawdziæ w razie problemów z dziaģaniem programu po aktualizacji.
Kiedy odnajdziemy plik *rpmnew to moŋemy ģatwo sprawdziæ czym róŋni się jego zawartoķæ w stosunku do obecnie uŋywanego pliku konfiguracji. Posģuŋymy się w tym celu programem diff z pakietu diffutils np.:
# diff jakis_plik.conf jakis_plik.conf.rpmnew |
W przypadku niektórych programów, po odinstalowaniu pakietu, pozostawiane są jego pliki konfiguracji, posiadają one rozszerzenie ".rpmsave", moŋemy je zachowaæ lub skasowaæ jeķli uznamy ŋe są nam zbędne.
Osoby chcące trzymaæ porządek w systemie powinny zajmowaæ się plikami .rpmnew i .rpmsave od razu po pracy z menadŋerem pakietów. Pliki ģatwo odnajdziemy, gdyŋ występują zwykle w katalogu /etc, odszukamy je następująco:
$ find /etc -name "*rpmnew" $ find /etc -name "*rpmsave" |
Architektury pakietów
W PLD programy są kompilowane dla wielu architektur sprzętowych, pozwala to na uŋywanie systemu na bardziej róŋnorodnym sprzęcie oraz na lepsze dopasowanie do uŋywanego procesora. Architekturę pakietu rozpoznamy po nazwie, jest to kilkuznakowe oznaczenie znajdujące się tuŋ przed rozszerzeniem pliku. W przypadku pakietu 0verkill-0.16-3.i686.rpm jego architektura to i686.
Aby sprawdziæ architekturę komputera, uŋywamy polecenia arch lub uname -m.
Wybór architektury
Pakiety zbudowane dla poszczególnych architektur są umieszczane w odpowiednich katalogach na serwerze. Ķcieŋka katalogów na serwerze wygląda następująco:
/dists/{$wersjaPLD}/PLD/{$architektura} |
Procesory
Tabela 2. Lista nazw kodowych architektur i odpowiadających im rodzin procesorów:
| Nazwa architektury | Obsģugiwana platforma | Dostępna wersja PLD |
|---|---|---|
| alpha | DEC/Compaq/HP Alpha AXP | Ra, Ac |
| amd64 / x86_64 | AMD K8: Opteron, Athlon 64, Sempron (socket: 754, 939), Intel EM64T | Ac, Th |
| athlon | AMD K7: Athlon, Duron, Sempron (socket A) | Ac |
| i386 | wszystkie procesory zgodne z i386 firmy Intel | Ra, Ac |
| i486 | Intel 486, AMD K5 (socket 3) i nowsze | Th |
| i586 | Intel 586 Pentium, Cyrix 5x86, Cyrix 6x86, AMD K5 (socket 7), AMD K6 i nowsze | Ra, Ac |
| i686 | Intel Pentrium II, Pentium PRO, AMD K7 i nowsze | Ra, Ac, Th |
| ppc | PowerPC | Ra, Ac |
| sparc | Sun SPARC 32bit | Ra, Ac |
| sparc64 | Sun SPARC 64bit | Ac |
| noarch | dowolna | - |
Naleŋy pamiętaæ by instalowaæ pakiety wyģącznie przeznaczone dla uŋywanej architektury. Wyjątkiem są pakiety z oznaczeniem noarch oraz pakiety przeznaczone dla procesorów Intel x86 i zgodnych: i386, i486, itd.
Architektury z rodziny x86 są bardziej lub mniej wyspecjalizowanymi grupami, najbardziej ogólna jest 386, zaķ kaŋda następna w kolejnoķci jest bardziej wyspecjalizowana. Im węŋsza specjalizacja grupy tym mniej modeli procesorów obsģuguje. Przykģadowo na maszynie z procesorem Pentium III (i686) moŋemy zainstalowaæ system w wersji i386, ale na procesorze 386 wersja i686 nie będzie dziaģaæ. Jeķli mamy nowszy procesor, to będziemy mogli uŋyæ bardziej wyspecjalizowanej architektury, a co za tym idzie lepiej wykorzystaæ jego potencjaģ.
Žródģa pakietów
W PLD jest kilka grup pakietów (žródeģ) w ramach tej samej wersji dystrybucji, róŋnią się one wersjami pakietów i zastosowaniem. Ich listę uzyskamy za pomocą Poldka:
$ poldek -l |
main (np. th): gģówne žródģo pakietów (domyķlne), zawiera stabilne wersje, od chwili wydania danej wersji dystrybucji, nie są tu dokonywane ŋadne zmiany
obsolete (np. th-obsolete): stare pakiety, usunięte z main w wyniku aktualizacji. Dzięki temu žródģu, moŋemy wróciæ do starszej wersji pakietu, jeķli zajdzie taka koniecznoķæ. Žródģo wprowadzone w Th.
test (np. th-test): trafiają tu pakiety prostu z builderów, bez sprawdzenia czy w ogóle dziaģają i czy są speģnione zaleŋnoķci. Uŋywanie pakietów z tego žródģa jest dosyæ ryzykownym krokiem, dlatego naleŋy go wykonywaæ wyģącznie w ostatecznoķci
ready (np. th-ready): następny krok w ŋyciu pakietu, jeķli pakiety dziaģają bez zarzutu, to są przenoszone razem z zaleŋnoķciami do main. Pakiety te są juŋ wstępnie przetestowane, nadal jednak powinniķmy zachowaæ ostroŋnoķæ instalując pakiety z tego katalogu
debuginfo (np. th-debuginfo, th-ready-debuginfo): pakiety zawierające wyģącznie symbole potrzebne przy debugowaniu. Pakiety te są pomocne dla programistów i deweloperów.
home: žródģo lokalne, pozwala ģatwo instalowaæ pakiety z katalogu ~/rpm/RPMS - miejsca domyķlnego umieszczania wģasnoręcznie zbudowanych pakietów.
Multilib
W ķrodowisku x86_64 moŋemy uŋywaæ takŋe aplikacji 32 bitowych, aby wygodnie instalowaæ pakiety zostaģy przygotowane žródģa multilib /etc/poldek/repos.d/pld-multilib.conf. Domyķlnie są przygotowane dla i686.
Žródģa uŋywane w starszych wersjach PLD:
updates (np. ac-updates) - aktualizacje, zaleca się regularne sprawdzanie czy nie pojawiają się tu nowe pakiety, žródģo staģo się zbędne w Th i nie jest uŋywane. W Th w roli updates uŋywa się žródģa ready. W Ra istniaģy dwa niezaleŋne žródģa pakietów z aktualizacjami: {$wersja}-updates-security i {$wersja}-updates-general. W Ac nastąpiģo ich poģączenie i od tej pory žródģo nazywa się {$wersja}-updates.
supported (np. ac-updates) - nietypowe pakiety, które nie powinny byæ trzymane w gģównym žródle. Są tu umieszczane pakiety rzadko uŋywane lub starsze wersje, podobnie jak updates przestaģo mieæ rację bytu w Th.
Aby wybraæ žródģo inne niŋ domyķlne naleŋy uŋyæ
parametru -n np.:
$ poldek -n th -n th-ready |
$ poldek -n debuginfo --up |
Ķcieŋki do podstawowych žródeģ w konfiguracji Poldka
Poldek jest dostarczany z wģaķciwie skonfigurowanymi etykietami, są one zdefiniowane w plikach /etc/poldek/source.conf i /etc/poldek/repos.d/pld.conf. Adresy oficjalnych serwerów i mirrorów znajdziemy w sekcja Serwery z pakietami w rozdziaģ Zasoby sieciowe PLD. Etykieta žródģa rozpoczyna się od przedrostka okreķlającego wersję dystrybucji, zapisaną maģymi literami, poniŋej przedstawiono ją jako ciąg {$wersja}, który moŋe mieæ wartoķæ np. ra, ac lub th. Ciąg {$arch} to architektura pakietów.
main: dists/{$wersja}/PLD/{$arch}/PLD/RPMS
obsolete: dists/{$wersja}/obsolete/{$arch}/RPMS
test: dists/{$wersja}/test/${arch}/
ready: dists/{$wersja}/ready/${arch}/
home: katalog lokalny: ~/rpm/RPMS
Cykl ŋycia pakietu
Zbudowany pakiet trafia do test gdzie oczekuje na zbudowanie zaleŋnoķci, następnie jest przenoszony przez RM-a do ready. kiedy wszytko jest w porządku trafia w koņcu do main/updates. W przypadku bardziej krytycznych pakietów kiedy pojawia się aktualizacja to starsza wersja trafia do obsolete. Proces ten zostaģ szerzej opisany w podręczniku dewelopera.
Budowanie pakietów
Wstęp
W większoķci wypadków będziemy korzystali z gotowych pakietów, zdarza się jednak, ŋe nie ma dostępnego jakiegoķ pakietu lub nie odpowiadają nam opcje z jakimi zostaģ skompilowany. Co więcej moŋe się zdarzyæ, ŋe będziemy potrzebowaæ starszej, niedostępnej juŋ wersji programu.
W takim wypadku nie powinniķmy pod ŋadnym pozorem kompilowaæ samodzielnie programów, jeķli nie upewnimy się, ŋe nie moŋna go zbudowaæ.
Budowanie
Budowanie jest operacją tworzenia pakietów na podstawie plików spec, do tego nie potrzeba umiejętnoķci tworzenia speców ani wiedzy dewelopera. Wystarczy odpowiednio przygotowaæ ķrodowisko, zainstalowaæ kilka pakietów i uŋyæ odpowiedniego narzędzia. Tak utworzymy nasz wģasny, prywatny builder, który moŋe nam wielokrotnie sģuŋyæ.
Opis budowania pakietów odnajdziemy w przewodniku dla deweloperów PLD, wszystkie potrzebne informacje odnajdziemy pod adresem pld-linux.org/DevelopingPLD oraz w sekcja Co jest potrzebne w rozdziaģ Moŋliwa droga do zostania szeregowym developerem PLD.
Zarządzanie
Jeķli utworzymy ķrodowisko wg. podanych wskazówek pakiety będą umieszczane w katalogu ~/rpm/RPMS. Uģatwi to ich instalację, gdyŋ Poldek ma ustawione lokalne žródģo dla tego katalogu. Zbudowany pakiet będziemy mogli instalowaæ dowolną iloķæ razy, warto więc przechowywaæ je uznamy ŋe mogą nam się jeszcze przydaæ.
Jeķli wymagamy od programu nietypowej funkcjonalnoķci i budujemy pakiet z niestandardowymi opcjami to moŋe się zdarzyæ, ŋe przy aktualizacji zastąpimy naszą wersję programu tą z pakietu dystrybucyjnego. Dlatego musimy byæ czujni przy operacji aktualizacji lub dopisaæ nazwę tego pakietu do opcji hold w pliku konfiguracji Poldka.
Poldek
Wstęp
Poldek jest nakģadką na program rpm, zapewniającą wygodny interfejs obsģugi oraz kilka dodatkowych funkcji. Poldek jest poķrednikiem w pobieraniu pakietów, indeksuje ich listy oraz uģatwia zarządzanie wieloma žródģami, moŋe pobieraæ pakiety lokalnie (dyski twarde, napędy optyczne) lub z sieci (FTP, HTTP, HTTPS, SMB, RSYNC). Obsģuguje ponadto zaleŋnoķci miedzy pakietami, wykrywa konflikty itp. Poldek nie obsģuguje jednak wszystkich operacji moŋliwych na pakietach RPM, dlatego nie moŋe caģkowicie zastąpiæ programu rpm.
Poldek do wielu operacji (pobieranie pakietów i indeksów, wyszukiwanie informacji itp.) nie wymaga praw administratora, wymagane są jednak do operacji zapisu w systemie, np. instalowanie, odinstalowanie, itp. Poldek w tym celu automatycznie uŋywa programu sudo, z tego względu konieczne jest posiadanie skonfigurowanego sudo, w przeciwnym razie pozostaje nam uruchamianie programu z konta roota.
Konfiguracja Poldka jest doķæ zģoŋona i wyjaķnienie wszystkich szczegóģów zajęģo by zbyt wiele miejsca, dlatego zajmiemy się jedynie najczęķciej uŋywanymi opcjami. Nie powinniķmy się jednak tym przejmowaæ, program jest gotowy do dziaģania od razu po zainstalowaniu i w większoķci wypadków nie ma potrzeby nic modyfikowaæ. Musimy jednak się upewniæ, ŋe mamy dobrze skonfigurowane adresy serwerów i architekturę pakietów, co zostaģo omówione w dalszej częķci rozdziaģu.
Więcej informacji o poldku i jego konfiguracji odnajdziemy w podręczniku systemowym (man,info) oraz na witrynie projektu pod adresem http://poldek.pld-linux.org.
Pliki konfiguracji
Konfiguracja Poldka jest przechowywana w kilku plikach wewnątrz katalogu /etc/poldek, to czy dany plik konfiguracji jest uŋywany okreķla opcja %include, umieszczona w gģównym pliku konfiguracji.
poldek.conf - gģówny plik konfiguracji, jeķli nie zostaģo zaznaczone inaczej to wģaķnie ten plik ma na myķli autor
aliases.conf - zawiera zdefiniowane aliasy poleceņ dla trybu interaktywnego
fetch.conf - zawiera konfigurację alternatywnych programów do pobierania pakietów, domyķlnie konfiguracja z tego pliku nie jest wczytywana.
repos.d/pld.conf - ustawienia žródeģ pakietów dla PLD
source.conf - plik przeznaczony dla lokalnych žródeģ pakietów
.poldekrc - plik konfiguracji uŋytkownika, który umieszczamy w katalogu domowym.
Konfiguracja pobierania pakietów
W pliku repos.d/pld.conf mamy dwie waŋne opcje wskazujące skąd mają byæ pobierane pakiety. Opcja _pld_arch wskazuje architekturę sprzętową pakietów, zaķ _pld_prefix mówi skąd mają byæ pobierane pakiety i dla jakiej wersji dystrybucji. Więcej o architekturach pakietów znajdziemy w sekcja Architektury pakietów, adresy serwerów i oficjalnych mirrorów zawarto w sekcja Serwery z pakietami w rozdziaģ Zasoby sieciowe PLD.
Poldek zacznie korzystaæ z proxy po ustawieniu wģaķciwych zmiennych ķrodowiskowych - zarówno w przypadku wbudowanego klienta jak i klientów zewnętrznych (np. wget). Moŋemy teŋ uŋyæ opcji proxy. Konfigurację proxy dla Linuksa szerzej opisano w sekcja Proxy w rozdziaģ Podstawy.
Inne opcje
Poldek przechowuje indeksy pakietów w katalogu zdefiniowanym w opcji cachedir, domyķlnie jest to $HOME/.poldek-cache. Jest to dobre rozwiązanie jeķli z Poldka korzysta jeden uŋytkownik, jeķli ma uŋywaæ go więcej osób to lepiej ustawiæ wspólny katalog np. /var/cache/poldek-cache, w ten sposób unikniemy wielokrotnego pobierania indeksów.
use sudo - uŋycie sudo przy uruchomieniu z konta zwykģego uŋytkownika.
hold - blokuje aktualizację pakietów które znalazģy się na jej liķcie.
ignore - opcja ukrywająca podane pakiety na liķcie dostępnych.
choose equivalents manually - pozwala wybieraæ uŋytkownikowi jeden z kilku pakietów oferujących tą samą funkcjonalnoķæ, domyķlnie wyģączona przez co wybór następuje automatycznie. Pozwala bardzo precyzyjnie wybieraæ pakiety do zainstalowania.
Tryby pracy
Kolejną waŋną jego cechą jest moŋliwoķæ pracy zarówno w trybie wsadowym jak i interaktywnym. Pierwszy z nich nadaje do wszelkiej maķci skryptów i automatyki, zaķ drugi jest wygodniejszy do bezpoķredniej obsģugi przez uŋytkownika. Komfort pracy w trybie interaktywnym sprawia, ŋe uŋytkownicy na co dzieņ korzystają niemal zawsze z niego. Stąd jeķli nie zostaģo to inaczej napisane to wģaķnie ten tryb autor ma na myķli.
Tryb interaktywny
Praca w trybie interaktywnym przypomina do zģudzenia uŋywanie powģoki systemowej (shella). Dostępne są: historia poleceņ, pomoc, dopeģnianie komend i nazw pakietów, aliasy, potoki itp. Na potrzeby tego rozdziaģu w przykģadach taki tryb będziemy sygnalizowaæ następującym znakiem zachęty:
poldek> |
Jedną z największych zalet trybu interaktywnego jest dopeģnianie nazw pakietów i poleceņ za pomocą tabulatora. Przykģadowo naciķnięcie klawisza tab po poleceniu:
poldek> upgrade |
W przypadku nazw pakietów moŋemy uŋywaæ "gwiazdki" jako znaku zastępczego (wildcard), który zastępuje dowolny ciąg znaków. Przedstawiono to na poniŋszym przykģadzie, który spowoduje zainstalowanie wszystkich pakietów o nazwach zaczynających się od "gnome-theme"
poldek> install gnome-theme* |
Zazwyczaj nie ma potrzeby podawania wersji programu, jednak w pewnych przypadkach moŋemy mieæ dostępnych kilka wersji tego samego pakietu (np. przy uŋywaniu wielu žródeģ na raz). Wtedy musimy podaæ jednoznacznie wersję pakietu.
Mamy do dyspozycji potoki:
poldek> ls perl* | grep curses |
Moŋemy równieŋ wywoģywaæ polecenia zewnętrzne:
poldek> ls perl* | !wc -l |
W obsģudze žródeģ i pakietów występuje wiele podobieņstw do systemu plików. Žródģa są traktowane jak katalogi zaķ pakiety jak pliki, do poruszania się w tym ķrodowisku uŋywamy poleceņ takich jak pwd, ls oraz cd.
Tryb wsadowy
Opis wszystkich parametrów trybu wsadowego uzyskamy dzięki poleceniu
$ poldek --help |
$ poldek --shcmd="desc apache" |
$ ipoldek desc apache |
Pierwsze kroki z Poldkiem
Poldek uruchomiony po raz pierwszy (bez podawania parametrów) sprawdza czy istnieją indeksy dla žródeģ, które ma automatycznie obsģugiwaæ. Jeķli ich nie ma, to zostaną automatycznie pobrane i zapisane w miejscu wskazanym przez omówioną powyŋej opcję cachedir. Po tej operacji zostanie uruchomiony Poldek trybie interaktywnym i będzie gotowy do pracy. Przed kaŋdą kolejną pracą z programem musimy uaktualniæ indeksy pakietów, na wypadek gdyby w žródģach nastąpiģy zmiany, w przeciwnym razie moŋemy otrzymywaæ komunikaty o braku pakietów. Aby uaktualniæ indeksy domyķlnych žródeģ wywoģujemy następująco program z powģoki systemowej:
$ poldek --up |
--upa,
dla pozostaģych žródeģ musimy podaæ ich nazwę po parametrze
-n,
žródģa pakietów zostaģy omówione w dalszej częķci rozdziaģu.
Po uruchomieniu programu mamy od razu moŋliwoķæ zarządzania pakietami, aby zobaczyæ listę dostępnych poleceņ wpisujemy help i naciskamy klawisz Enter. Większoķæ poleceņ ma skģadnię:
poldek> {$polecenie} {$pakiet} {$opcje} |
poldek> {$polecenie} -? |
Aby opuķciæ program wpisujemy polecenie quit lub wciskamy ctrl+d
Zarządzanie pakietami
Mamy dostępne następujące polecenia zarządzania pakietami:
operacje instalacji (install), aktualizacji
pakietów (upgrade), usuwania pakietów
(uninstall), pobierania pakietów bez
instalacji (get). Ponadto mamy polecenia do
zbierania danych o pakietach: wyķwietlanie listy dostępnych
(ls), wyķwietlenia informacji
(desc) oraz przeszukiwania bazy
(search).
W wielu przypadkach pomocna będzie opcja -t,
która przeprowadzi symulację caģej operacji, dzięki której
dowiemy się jak duŋe i jak istotne zmiany zostaną dokonane
w systemie po operacji. Najczęķciej jest uŋywana przy
aktualizacji i usuwaniu pakietów.
Poniŋej zamieszczono kilka przykģadów zarządzania pakietami, na początek przykģad wyķwietlenia listy pakietów (wszystkich zaczynających się od zsh):
poldek> ls zsh* |
poldek> desc zsh |
poldek> install zsh |
poldek> uninstall zsh |
To jedynie podstawowe polecenia, więcej informacji znajdziemy w pomocy Poldka.
Žródģa
Poldek ma kilka zdefiniowanych žródeģ pakietów w plikach source.conf i repos.d/pld.conf, pierwszy z plików jest gģównym plikiem konfiguracji žródeģ, drugi zaķ zawiera wpisy dla oficjalnych žródeģ PLD. Aby wyķwietliæ listę skonfigurowanych žródeģ, wraz uŋytymi opcjami uŋyjemy polecenia:
$ poldek -l ac ftp://ftp.ac.pld-linux.org/dists/ac/PLD/athlon/PLD/RPMS/ (type=pndir) ac-ready ftp://ftp.ac.pld-linux.org/dists/ac/ready/athlon/ (noauto,type=pndir) ac-supported ftp://ftp.ac.pld-linux.org/dists/ac/supported/athlon/ (noauto,type=pndir) ac-test ftp://ftp.ac.pld-linux.org/dists/ac/test/athlon/ (noauto,type=pndir) ac-updates-general ftp://ftp.ac.pld-linux.org/dists/ac/updates/general/athlon/ (noauto,type=pndir) ac-updates-security ftp://ftp.ac.pld-linux.org/dists/ac/updates/security/athlon/ (type=pndir) home /home/users/qwiat/rpm/RPMS/ (noauto,noautoup,type=dir) |
Nie wszystkie žródģa są obsģugiwane automatycznie,
zaleŋy to od ustawienia
opcji noauto w konfiguracji danego žródģa
(zauwaŋymy ją teŋ na powyŋszym zrzucie ekranu).
Aby tymczasowo uŋyæ innego zestawu žródeģ przy uruchomieniu
musimy podaæ ich listę poprzedzonych parametrem
-n np.:
$ poldek -n ac -n ac-ready |
Istnieje moŋliwoķæ instalacji pakietów Poldkiem z lokalnych
žródeģ, zamiast posģugiwania się programem rpm.
W pliku source.conf zdefiniowane
jest žródģo home, które sģuŋy do wygodnego
instalowania pakietów z katalogu
$HOME/rpm/RPMS, uŋywanego powszechnie
do umieszczania samodzielnie budowanych
pakietów. Nie ma jednak potrzeby kaŋdorazowego
umieszczania tam pakietów jeķli to uznamy za konieczne.
Moŋemy utworzyæ tymczasowe žródģo lokalne na podstawie
zawartoķci katalogu za pomocą
opcji -s:
poldek -s /jakis/katalog |
Poldek po uruchomieniu tworzy dla wygody dodatkowe žródģa wirtualne: all-avail i installed. Pierwsze zawiera sumę pakietów ze wszystkich wskazanych žródeģ, drugie to lista zainstalowanych pakietów.
Przy pracy z samodzielnie podawanymi žródģami naleŋy wskazywaæ teŋ gģówne žródģo pakietów (main), tak aby mogģy zostaæ pobrane pakiety wymagane w ramach zaleŋnoķci. W przeciwnym razie moŋemy otrzymaæ bģędy o nieistniejących pakietach.
Porady
Przy pracy z wieloma pakietami
moŋemy utraciæ moŋliwoķæ przewinięcia ekranu
w celu odczytania najstarszych komunikatów.
Aby temu zaradziæ uŋyjemy opcji --log,
dzięki której, wskaŋemy plik do którego trafią
wszystkie komunikaty.
RPM
Instalowanie pakietów
Uŋywając programu rpm posģugujemy się następującym schematem: rpm [opcje] pakiet.rpm
Instalacja pakietu jest dosyæ prosta. Zaģóŋmy ŋe pobraliķmy
z sieci plik
docbook-dtd31-sgml-1.0-12.noarch.rpm,
teraz jedyną rzeczą jaką musimy wykonaæ jest wydanie polecenia
rpm z opcją -i. Uŋywając
kombinacji -ivh dla procesu instalacji,
-Uvh uzyskamy pasek postępu instalacji dla
poszczególnych instalowanych pakietów.
# rpm -i docbook-dtd31-sgml-1.0-12.noarch.rpm |
Brak ostrzeŋeņ lub bģędów oznacza prawidģową instalację, teraz nieco skomplikujemy sytuację:
# rpm -i libghttp-devel-1.0.9-4.i686.rpm error: failed dependencies: libghttp = 1.0.9 is needed by libghttp-devel-1.0.9-4 |
Tym razem instalacja się nie powiodģa, poniewaŋ pakiet libghttp-devel wymaga zainstalowanego pakietu libghttp. Aby instalacja pakietu się powiodģa wykonujemy następujące polecenie:
# rpm -i libghttp-devel-1.0.9-4.i686.rpm libghttp-1.0.9-4.i686.rpm |
Teraz wszystko jest w porządku, oba pakiety są zainstalowane.
Moŋliwe jest instalowanie pakietu z opcją ignorowania
zaleŋnoķci: --nodeps,
opcję tą stosujemy jednak w ostatecznoķci.
Aktualizowanie pakietów
Aktualizacja przebiega podobnie jak instalacja, tyle ŋe uŋywamy
przeģącznika -U np.:
# rpm -U docbook-dtd31-sgml-1.0-13.noarch.rpm |
Naleŋy pamiętaæ o tym, ŋe aktualizacja nastąpi tylko wtedy gdy w systemie jest zainstalowana starsza wersja, w przeciwnym wypadku zostaniemy poinformowani, ŋe pakiet jest juŋ zainstalowany. Aby dokonaæ reinstalacji pakietu wykonujemy polecenie
# rpm -i docbook-dtd31-sgml-1.0-13.noarch.rpm --force |
Odinstalowywanie pakietów
Zainstalowaliķmy kilka pakietów, teraz moŋemy spróbowaæ je
odinstalowaæ - wykonujemy to przy uŋyciu opcji
-e.
# rpm -e libghttp-devel-1.0.9-4.i686.rpm libghttp-1.0.9-4.i686.rpm error: package libghttp-devel-1.0.9-4.i686.rpm is not installed error: package libghttp-1.0.9-4.i686.rpm is not installed |
Cóŋ tu się staģo? Podano nieprawidģową nazwę pakietu, naleŋy pamiętaæ o tym, ŋe przy odinstalowaniu pakietu nie podaje się rozszerzenia pakietu. Poprawne polecenie przedstawiono poniŋej:
# rpm -e libghttp-devel libghttp |
lub:
# rpm -e libghttp-devel-1.0.9-4 libghttp-1.0.9-4 |
Uwaga: pierwszy przykģad stosuje się w przypadku zainstalowania jednej wersji pakietu, drugi zaķ uŋywa się w przypadku kilku róŋnych (np. dwie róŋne wersje jądra).
Uwagi
Program rpm posiada o wiele bogatsze opcje, przedstawiono tu zaledwie kilka najwaŋniejszych, więcej moŋna znaležæ w podręczniku systemowym (man/info).
Bezpieczeņstwo
Uruchamianie Poldka
Dobrym zwyczajem jest uŋywanie Poldka z poziomu zwykģego uŋytkownika z wģączoną obsģugą sudo:
use sudo = yes |
Podpisy pakietów
W PLD mamy moŋliwoķæ kontrolowania podpisów pakietów, dzięki czemu zyskujemy pewnoķæ, ŋe instalujemy pakiety z zaufanego žródģa. Importując klucz klucz publiczny GPG unikamy równieŋ zasypywania następującymi komunikatami:
Nagģówek V3 sygnatura DSA: NOKEY, key ID 1bbd5459 |
Zaczynamy od zaimportowania klucza publicznego (dla Ac) z serwera FTP:
rpm --import ftp://ftp.pld-linux.org/dists/2.0/PLD-2.0-Ac-GPG-key.asc |
signed = yes |
[source]
type = %{_ac_idxtype}
name = ac
path = %{_pld_prefix}/PLD/%{_pld_arch}/PLD/RPMS/
signed = yes |
Teraz Poldek będzie ostrzegaģ przy instalacji niepodpisanego pakietu:
uwaga: rhythmbox-0.9.8-2.athlon.rpm: gpg/pgp nie znaleziono podpisu bģąd: rhythmbox-0.9.8-2: signature verification failed Wystąpiģy bģędy weryfikacji podpisu. Kontynuowaæ? [y/N] |
Więcej informacji w dokumentacji programu rpm i Poldka.
Zaawansowane operacje
Lista ostatnio instalowanych pakietów
Jeķli chcemy utworzyæ listę zainstalowanych pakietów w kolejnoķci wg. daty instalacji to posģuŋymy się poleceniem
# rpm -qa --last |
Odinstalowanie "opornych" pakietów
Bywa, ŋe pakiet w wyniku bģędów w skryptach
nie pozwala się odinstalowaæ, moŋemy go jednak
ģatwo usunąæ wydając polecenie deinstalacji z
parametrem --noscripts np.:
# rpm -e lockdev-1.0.2-1 --noscripts |
Repackage - bezpieczna aktualizacja
Jeķli obawiamy się aktualizacji jakichķ pakietów, moŋemy posģuŋyæ się operacją repackage - ponownego umieszczenia plików w pakiecie rpm. Jeķli program po aktualizacji odmawia posģuszeņstwa, wystarczy ponownie zainstalowaæ pakiet w starszej wersji. Aby wģączyæ repakietację wystarczy, ŋe ustawimy niezerową wartoķæ dla makra %_repackage_all_erasures w pliku /etc/rpm/macros:
%_repackage_all_erasures 1 |
poldek> upgrade geninitrd-10000.18-6.noarch --pmop=--repackage |
# rpm -U --repackage geninitrd-10000.18-6.noarch |
Aby cofnąæ wersję pakietu wykonujemy następującą operację:
rpm -U --oldpackage /var/spool/repackage/1189984560/geninitrd-10000.18-6.noarch |
Kontrola integralnoķci systemu
Zdarza się, ŋe potrzebujemy sprawdziæ czy nie nastąpiģy w systemie uszkodzenia jakichķ plików lub ich modyfikacje. Takie zdarzenia mogą się pojawiæ w wypadku uszkodzenia systemu plików, bģędu czģowieka lub ataku crackera. W obu przypadkach moŋemy posģuŋyæ się weryfikacją pakietów RPM. Kontrola przyniesie oczekiwany skutek tylko wtedy, gdy jesteķmy pewni, ŋe sama baza RPM nie zostaģa skompromitowana lub uszkodzona.
Aby uzyskaæ listę zmodyfikowanych plików uŋyjemy programu rpm:
# rpm --verify --all ......G. /etc/cups S.5....T /usr/lib/libsasl2.so.2.0.22 S....... c /etc/xml/catalog .M...UG. c /etc/samba/smb.conf |
Zaģóŋmy, ŋe poznaliķmy listę zmodyfikowanych plików i chcemy na jej podstawie stworzyæ listę pakietów do reinstalacji. Zaczynamy od odfiltrowania wszystkiego prócz nazw plików:
# rpm --verify --all | sed 's/.*\ //' > pliki.txt |
# cat pliki.txt | xargs rpm -qf --qf '%{NAME}\n' | sort -u > pakiety.txt |
# poldek --reinstall --pset pakiety.txt |
Naprawa bazy RPM
System pakietów RPM opiera się na bazie w postaci plików przechowywanych w katalogu /var/lib/rpm. Nagģe przerwanie pracy programu, który na niej operowaģ moŋe zaowocowaæ bģędami w jej strukturze. Na początek naleŋy się upewniæ, ŋe ŋaden z procesów nie operuje na bazie:
# lsof | grep /var/lib/rpm |
# rm -f /var/lib/rpm/__db* |
# tar -czf rpm.tar.gz /var/lib/rpm/ |
# rpm --rebuilddb |
# rpm -qa |
--justdb, powodującą jedynie
modyfikowanie bazy RPM.
Reinstalacja wszystkich pakietów - zmiana architektury
Zdarza się, ŋe potrzebujemy zainstalowaæ na nowo wszystkie pakiety, np. w wypadku zainstalowania pakietów w niewģaķciwej architekturze. Nie jest to pracochģonna operacja, wystarczy, ŋe z powģoki Poldka wydamy polecenie:
poldek> install -F * --reinstall --nodeps --nofollow |
Bootloader
Ten rozdziaģ zawiera dostępnych w PLD bootloaderów
Wstęp
Podczas startu naszego komputera z naszego dysku uruchamiany jest bootloader. To wģaķnie on odpowiada za zaģadowanie prawidģowego jądra systemu, czy teŋ przekazywanie do jądra specjalnych parametrów. Dla architektur x86 mamy do wyboru jeden z dwóch bootloaderów: LILO oraz Grub (brak wersji 64 bit).
Parametry jadra
Oba bootloadery pozwalają na przekazywanie do jądra specjalnych parametrów, dzięki którym moŋemy wpģywaæ na start lub pracę systemu jeszcze przed jego zaģadowaniem. Parametry przekazane przed startem systemu będą przesģaniaæ te uŋyte w konfiguracji bootloadera. W poniŋszej tabeli przedstawiono najczęķciej uŋywane opcje.
Przekazywanie parametrów jądra wygląda podobnie w obu wypadkach, po wģączeniu specjalnego trybu w bootloaderze otrzymujemy wiersz, na koņcu którego dopisujemy potrzebne nam parametry lub modyfikowaæ istniejące. Poniŋej przedstawiamy przykģadowe dodanie parametru init w bootloaderze Grub:
grub append> root=/dev/sda2 init=/bin/sh |
Tabela 1. Parametry jądra
| Parametr | Znaczenie | Przykģad |
|---|---|---|
| {$nr}/single |
Cyfra (1-5) wskazująca który poziom uruchomieniowy (run level), opcja single to tryb jednego uŋytkownika. Dzięki nim opcjom moŋna przesģoniæ ustawienie opcji initdefault z pliku /etc/inittab. Więcej o poziomach pracy w sekcja Zmiana poziomu pracy systemu w rozdziaģ Administracja, zaķ o pliku /etc/inittab przeczytamy w sekcja Kluczowe pliki w rozdziaģ Konfiguracja systemu. | single lub 1 |
| root={$urządzenie} |
Wskazanie urządzenia (partycji) na którym znajduje się gģówny system plików. Wartoķcią parametru moŋe byæ ķcieŋka do urządzenia w katalogu /dev (np. /dev/hda1) lub wartoķæ liczbowa powstaģa z poģączenia szesnastkowej wartoķci liczb major i minor urządzenia. Major podajemy w postaci jednej cyfry, natomiast minor powinien byæ juŋ rozwinięty do dwóch. Przykģadowo urządzenie o wartoķciach major 3 i minor 1 będzie przedstawiane jako 301, 0301 lub 0x301 (wartoķci 3 i 1 są takie same w systemie dziesiętnym i szesnastkowym). Urządzenia oraz liczby major i minor szerzej opisano w sekcja Urządzenia w rozdziaģ Kernel i urządzenia | root=/dev/hda1 lub root=0x301 |
| init={$program} | Wskazanie programu, który ma zostaæ uŋyty zamiast domyķlnego programu Init; opcja uŋywana w krytycznych sytuacjach, np. gdy system nie moŋe zostaæ uruchomiony nawet w trybie single. | init=/bin/bash |
| vga={$tryb} | Wskazanie trybu bufora ramki, więcej o buforze ramki w następnym rozdziale. | vga=0x303 |
Opis wybranych parametrów jądra zamieszczono na stronie http://www.jtz.org.pl/Html/BootPrompt-HOWTO.pl.html, zaķ peģną ich listę odnajdziemy w dokumentacji jądra, w pliku /usr/src/linux/Documentation/filesystems/devfs/boot-options
Są równieŋ specjalne parametry, które przekazuje się do jądra w trakcie pracy systemu, opisaliķmy je w sekcja Parametry jądra w rozdziaģ Kernel i urządzenia.
MBR czy bootsector?
Oba bootloadery mają moŋliwoķæ instalacji zarówno w obszarze MBR dysku, jak i bootsectorze partycji. Instalacja w MBR jest dosyæ wygodna i o wiele bardziej popularna, dlatego wģaķnie tam powinniķmy instalowaæ bootloader. Instalacja w bootsectorze w wypadku niektórych systemów plików (np. XFS) jest niemoŋliwa, gdyŋ ich superblok jest umieszczany na samym początku partycji - w miejscu które powinno byæ zarezerwowane dla bootloadera.
Frame buffer (bufor ramki)
Frame Buffer (bufor ramki) to m.in. mechanizm pozwalający na pracę konsoli w wyŋszych rozdzielczoķciach. Aby go wģączyæ przekazujemy parametr vga przy uruchomieniu bootloadera lub dodajemy go do pliku konfiguracji np.:
vga=0x303 |
Wartoķæ opcji vga to numer trybu graficznego dla danej rozdzielczoķci i gģębi koloru, listę dostępnych trybów przedstawiono w poniŋszej tabeli. Kodowe oznaczenia trybów bufora ramki moŋemy podawaæ zarówno szesnastkowo jak i dziesiętnie, dlatego teŋ w tabeli, obok wartoķci szesnastkowych umieszczono wartoķci w systemie dziesiętnym (w nawiasach).
Tabela 2. Tryby bufora ramki
| Gģębia koloru | 640x480 | 800x600 | 1024x768 | 1280x1024 |
|---|---|---|---|---|
| 256 (8 bit) | 0x301 (769) | 0x303 (771) | 0x305 (773) | 0x307 (775) |
| 32k (15 bit) | 0x310 (784) | 0x313 (787) | 0x316 (790) | 0x319 (793) |
| 65k (16 bit) | 0x311 (785) | 0x314 (788) | 0x317 (791) | 0x31A (794) |
| 16M (24 bit) | 0x312 (786) | 0x315 (789) | 0x318 (792) | 0x31B (795) |
Zamiast wskazywaæ konkretny tryb moŋemy opcji vga przypisaæ wartoķæ ask, dzięki temu jądro pozwoli wyķwietliæ listę trybów i wybraæ jeden z nich. Więcej o buforze ramki dowiemy się z dokumentacji kernela, jeķli zainstalowaliķmy pakiet z dokumentacją jądra to znajdziemy ją w katalogu /usr/src/linux/Documentation/fb.
LILO
LILO (LInux LOader) jest najbardziej popularnym linuksowym bootloaderem. Jego instalacja polega na utworzeniu pliku konfiguracyjnego (/etc/lilo.conf) a następnie na wydaniu polecenia lilo w celu instalacji w MBR lub bootsektorze. Kaŋda modyfikacja pliku konfiguracji, wygenerowanie nowego obrazu initrd lub instalacja nowego jądra pociąga za sobą koniecznoķæ ponownej instalacji obrazu.
O initrd poczytamy w sekcja Initrd w rozdziaģ Kernel i urządzenia.
Konfiguracja podstawowa
Poniŋej, dla przykģadu przedstawiony zostaģ bardzo prosty plik konfiguracji, ma on za zadanie umieķciæ lilo w MBR dysku twardego, umoŋliwiając w ten sposób uruchomienie naszej dystrybucji.
boot=/dev/hda read-only lba32 image=/boot/vmlinuz label=pld root=/dev/hda1 initrd=/boot/initrd |
Plik konfiguracji lilo dzieli się na dwie zasadnicze częķci: blok opcji gģównych oraz opcje obrazu. W powyŋszym przykģadzie opcje gģówne umieszczone są na samym początku (do pustego wiersza). Wartoķæ zmiennej boot mówi gdzie ma zostaæ zainstalowany bootloader (bootsector/MBR), w tym wypadku jest o MBR dysku. Opcja read-only wymusza start systemu w trybie tylko do odczytu (póžniej jest przemontowany na tryb do odczytu i zapisu), lba32 wģącza wykorzystanie 32-bitowego adresowania (jest rozwiązaniem limitu cylindra 1024).
Następna sekcja (ustawienia obrazu) to konfiguracja dla konkretnego systemu operacyjnego (tutaj Linuksa). Kaŋdy system, który mielibyķmy obsģugiwaæ z poziomu lilo, musi mieæ taką sekcję. Opcja image rozpoczyna sekcję i jednoczeķnie wskazuje ķciekę do jądra, label to wyķwietlana etykieta obrazu, root wskazuje urządzenie z gģównym systemem plików, initrd to ķcieŋka do obrazu initrd (initial ramdisk).
Opcję root szerzej opisano w sekcja Wstęp. Z nazewnictwem urządzeņ masowych zapoznamy się w sekcja Nazewnictwo urządzeņ masowych w rozdziaģ Pamięci masowe.
Dzięki powyŋszej konfiguracji bootloader bezzwģocznie uruchomi nasze PLD zainstalowane na pierwszej partycji dysku hda bez zadawania jakichkolwiek pytaņ. W wielu przypadkach będziemy chcieli przekazaæ do kernela specjalne parametry lub mieæ moŋliwoķæ wyboru innego systemu operacyjnego (o ile dodaliķmy do lilo taką moŋliwoķæ). Wtedy konieczne będzie zdefiniowanie dwóch dodatkowych opcji:
prompt timeout=100 |
Inne systemy operacyjne
Istnieje moŋliwoķæ uruchamiania wielu systemów operacyjnych z poziomu lilo, w tym celu do pliku konfiguracji musimy dodaæ odpowiednie obrazy i opisane wczeķniej opcje prompt i timeout. Poniŋej zostaģa umieszczona sekcja pozwalająca uruchomiæ system DOS/Windows umieszczony na dysku hda3.
other=/dev/hda3 label=windows |
Domyķlnym obrazem wybranym przez bootloader jest pierwszy w kolejnoķci z pliku konfiguracji. Moŋemy to ustawienie bardzo prosto modyfikowaæ za pomocą opcji default wskazującej etykietę domyķlnego obrazu, np.:
default=pld |
Frame Buffer
Frame Buffer (bufor ramki) to m.in. mechanizm pozwalający na pracę konsoli w wyŋszych rozdzielczoķciach. Aby go wģączyæ, do konfiguracji linuksowego obrazu lub do sekcji gģównej dodajemy parametr jądra vga np.:
vga=0x303 |
image=/boot/vmlinuz label=pld root=/dev/hda1 initrd=/boot/initrd vga=0x303 |
Graficzne menu
Jeķli zdecydowaliķmy się na wyķwietlanie menu początkowego (za pomocą opcji prompt) to moŋemy się pokusiæ o ustawienie graficznego menu. Z pakietem lilo dostajemy odpowiednio przygotowane bitmapy, musimy tylko dodaæ kilka opcji do gģównej sekcji pliku konfiguracji.
Wskazujemy interesujący nas obrazek:
bitmap = /boot/lilo-pldblue8.bmp |
bmp-table = 17,9;1,14,16,4 bmp-colors = 0,213,137;152,24,1 bmp-timer = 2,29;152,52,1 |
Zakoņczenie
Kiedy juŋ skonfigurujemy nasz bootloader wydajemy polecenie lilo:
# lilo Added pld * |
GRUB
GRUB (GRand Unified Bootloader) jest bootloaderem zdobywającym sporą popularnoķæ, ze względu na swoją elastycznoķæ i duŋe moŋliwoķci. Jest tak rozbudowany, ŋe musi trzymaæ częķæ swoich danych na dysku twardym, z tego teŋ względu obsģuguje kilka systemów plików i moŋe wykonywaæ proste operacje dyskowe. GRUB normalnie "widzi" pliki na dysku, a więc widzi wģasny plik konfiguracji, kernel i obraz initrd. Dzięki temu nie ma potrzeby robienia czegokolwiek po zmianie konfiguracji, wygenerowaniu initrd czy aktualizacji kernela. Jest za to czuģy niekiedy na aktualizacje "samego siebie" i wymaga niekiedy ponownej instalacji do MBR-u/bootsectora, nie ma tu jednak ŋadnej jasnej reguģy. GRUB na kaŋdym etapie konfiguracji (w trybie interaktywnym) wspiera nas wbudowaną pomocą oraz dopeģnianiem nazw plików, urządzeņ i partycji.
Do największych zalet GRUB-a moŋna zaliczyæ moŋliwoķæ zmiany konfiguracji startowej z poziomu dziaģającego bootloadera. Kiedy uruchomiony zostanie bootloader wybieramy obraz a następnie wciskamy klawisz e. Wyķwietlą nam się wiersze konfiguracji, moŋemy je modyfikowaæ za pomocą wbudowanego prostego edytora tekstów. Po skoņczonej edycji wciskamy klawisz b, aby uruchomiæ system z wprowadzonymi zmianami.
Kolejną waŋną jego cechą jest moŋliwoķæ uŋywania klawiatury USB, w przeciwieņstwie do LILO, jedyną rzeczą jaką musimy zrobiæ w tym wypadku to wģączyæ obsģugę klawiatury USB w BIOS-ie.
O initrd poczytamy w sekcja Initrd w rozdziaģ Kernel i urządzenia.
Nazewnictwo urządzeņ
Nie uŋywamy nazw dysków opierających się na urządzeniach widniejących w /dev (np. /dev/hda). GRUB przy pomocy BIOS-u sprawdza istniejące dyski i numeruje je począwszy od zera. Dla przykģadu, jeŋeli posiadamy dwa dyski twarde (np. hda i hdc), pierwszy z nich zostanie oznaczony jako hd0, drugi jako hd1. Sytuacja z partycjami wygląda podobnie, równieŋ numerowane są od zera, natomiast pierwsza partycja logiczna będzie oznaczona numerem 4.
Obszar MBR oznaczany jako /dev/hda będzie widziany jako (hd0), partycja /dev/hda1 będzie rozpoznawana jako (hd0,0). Podane nawiasy nie są przypadkowe, jest to cecha skģadni poleceņ GRUB-a.
Urządzenia masowe opisano szerzej w sekcja Nazewnictwo urządzeņ masowych w rozdziaģ Pamięci masowe.
Konfiguracja podstawowa
Konfiguracja polega na odpowiednim skonfigurowaniu pliku /boot/grub/menu.lst i instalacji bootloadera w MBR/bootsektorze dysku. W poniŋszych przykģadach zaģoŋyliķmy, ŋe zarówno / (rootfs) jak i /boot leŋą na tej samej partycji pierwszego dysku twardego. W przykģadowej konfiguracji będzie to /dev/hda1. Poniŋej przedstawiono przykģadową konfigurację:
timeout 15 title pld root (hd0,0) kernel /boot/vmlinuz root=/dev/hda1 initrd /boot/initrd |
Konfiguracja GRUB-a podzielona jest na sekcję gģówną i sekcje obrazów, sekcja gģówna są to ustawienia globalne, zaķ konfiguracja obrazów to opcje dla kaŋdego z obsģugiwanych systemów operacyjnych. Powyŋej mamy sekcję gģówną oraz sekcję obrazu oddzieloną pustym wierszem.
Opcja timeout w sekcji gģównej to czas w sekundach oczekiwania na reakcję uŋytkownika.
Opcja title w sekcji obrazu to jego etykieta, root(hd0,0) to partycja na której GRUB będzie szukaģ swoich plików (w PLD GRUB trzyma swoje pliki w /boot/grub). Parametry kernel i initrd to ķcieŋki do plików kernela i initrd, w powyŋszym przykģadzie będą szukane na urządzeniu (hd0,0) gdyŋ podane do nich ķcieŋki są względne. Parametr root= jest parametrem jądra wskazującym poģoŋenie gģównego systemu plików, opisanym szerzej w sekcja Wstęp. Moŋe mieæ zarówno postaæ liczbową jak i postaæ nazwy urządzenia z katalogu /dev np. /dev/hda1.
Kiedy plik konfiguracji jest gotowy moŋemy przejķæ do instalacji GRUB-a.
Instalacja
Przejdžmy teraz do instalacji GRUB-a w MBR, rozpoczynamy od uruchomienia programu grub, mamy teraz do dyspozycji interaktywną powģokę, oferującą liczne polecenia, dopeģnianie oraz pomoc. Rozpoczynamy od polecenia root z parametrem wskazującym miejsce gdzie znajdują się pliki GRUB-a, konieczne do jego instalacji.
grub> root (hd0,0) Filesystem type is xfs, partition type 0x83 |
grub> setup (hd0) Checking if "/boot/grub/stage1" exists... yes Checking if "/boot/grub/stage2" exists... yes Checking if "/boot/grub/xfs_stage1_5" exists... yes Running "embed /boot/grub/xfs_stage1_5 (hd0)"... 18 sectors are embedded. succeeded Running "install /boot/grub/stage1 (hd0) (hd0)1+18 p (hd0,0)/boot/grub/stage2 /boot/grub/menu.lst"... succeeded Done. |
grub> quit |
Inne systemy operacyjne
Zakģadam, ŋe chcemy dodaæ system Microsoftu zainstalowany na partycji /dev/hda2, oto sekcja jaką musimy dopisaæ do /boot/grub/menu.lst:
title Windows rootnoverify (hd0,1) chainloader +1 |
default 2 |
Frame Buffer
Frame Buffer (bufor ramki) to mechanizm pozwalający m.in. na pracę konsoli w wyŋszych rozdzielczoķciach. Aby go wģączyæ, do parametrów jądra w konfiguracji linuksowego obrazu dodajemy parametr vga np. vga=0x303. Przykģadowa konfiguracja obrazu będzie wyglądaģa następująco:
title pld root (hd0,0) kernel /boot/vmlinuz root=0301 vga=0x303 initrd /boot/initrd |
Graficzne menu
W pakiecie z GRUB-em dostępne są grafiki, co sugeruje
moŋliwoķæ wyķwietlenia ich w menu, jednak GRUB w PLD
domyķlnie ich nie obsģuguje. Aby wģączyæ taką moŋliwoķæ
musimy samemu zbudowaæ pakiet z opcją
--with splashimage.
Instalujemy zbudowany pakiet, a następnie do pliku konfiguracji, do sekcji gģównej dodajemy opcję wskazującą bitmapę, która ma byæ wyķwietlana np.:
splashimage=(hd0,0)/boot/grub/splash.xpm.gz |
foreground = ffffff background = 000000 |
Grafiki moŋemy tworzyæ samemu, GRUB wymaga indeksowanej bitmapy o 14 kolorach i rozdzielczoķci 640x480, typu .xpm, plik musi byæ dodatkowo skompresowany programem Gzip.
Bezpieczeņstwo bootloadera
Jak juŋ zostaģo wspomniane, GRUB trzyma częķæ swoich danych w systemie plików, co przy powaŋnym uszkodzeniu systemu plików moŋe uniemoŋliwiæ start systemu. Rozwiązaniem tego problemu, moŋe byæ umieszczenie gaģęzi /boot na osobnej partycji, tak jak to byģo dawniej robione dla ominięcia ograniczeņ starych wersji LILO. Więcej o podziale na partycje odnajdziemy w sekcja Podziaģ na partycje w rozdziaģ Pamięci masowe.
Dla większego bezpieczeņstwa partycję taką moŋna montowaæ w trybie tylko do odczytu, musimy jednak wtedy pamiętaæ o koniecznoķci przemontowania jej do trybu rw, przed kaŋdą aktualizacją jądra, lub bootloadera.
Uwagi
W przypadku nietypowych konfiguracji będziemy zmuszeni do podawania ķcieŋek bezwzględnych do plików. Podajemy je następująco: (hdX,Y)/katalog/plik np.: (hd0,0)/boot/vmlinuz
GRUB wymaga kompletnej listy urządzeņ w katalogu /dev, stąd mogą pojawiæ się problemy przy próbie instalacji go z chroota opartego o udev. Naleŋy w tym wypadku podmontowaæ z gģównego system katalog /dev z opcją
-bind. Pliki urządzeņ zostaģy dokģadniej opisane w sekcja Urządzenia w rozdziaģ Kernel i urządzenia.
rc-boot
Wstęp
Osoby nie przepadające za konfiguracją powyŋszych bootloaderów, mogą skorzystaæ z narzędzia o nazwie rc-boot. Jest to proste i wygodne w uŋyciu narzędzie, stworzone dla potrzeb PLD, które zapewnia uniwersalny interfejs do zarządzania bootloaderem. Zostaģ stworzony w celu automatycznego aktualizowania bootloadera po zaktualizowaniu jądra, jednak nie zdobyģ szerszej popularnoķci wķród uŋytkowników. Dzięki rc-boot moŋemy uŋywaæ dowolnego bootloadera (np. LiLo, Grub), nie znając zasad ich dziaģania czy skģadni plików konfiguracji.
W gruncie rzeczy korzystanie z rc-boot ma sens wyģącznie przy uŋywaniu LiLo. Bootloader GRUB nie wymaga przeģadowania po aktualizacji jądra, dlatego uŋytkownicy uŋywają wģaķnie jego zamiast rc-boot.
Aby utworzyæ bootloader omawianym narzędziem naleŋy się posģuŋyæ poleceniem rc-boot, to jaki bootloader zostanie uŋyty i jakie opcje będą ustawione, definiujemy w jednym uniwersalnym pliku konfiguracji: /etc/sysconfig/rc-boot/config. Dodatkowo wymagane są specjalne pliki "obrazów" odpowiadające kaŋdemu systemowi operacyjnemu, który chcemy obsģugiwaæ z poziomu bootloadera. Są to proste pliki konfiguracyjne umieszczane w katalogu /etc/sysconfig/rc-boot/images. Po zainstalowaniu systemu powinien tam byæ przynajmniej jeden taki plik.
Podstawowa konfiguracja
Po zainstalowaniu pakietu rc-boot wymagane są poprawki w konfiguracji pliku /etc/sysconfig/rc-boot/config. Na początek odblokujemy dziaģanie rc-boot:
DOIT=yes |
Kolejno wybieramy bootloader jaki chcemy uŋywaæ, mamy do wyboru lilo oraz grub:
LOADER=grub |
Następnie ustalamy gdzie ma byæ zainstalowany bootloader np.: /dev/hda, /dev/hdb2 lub mbr. Wartoķæ mbr oznacza ŋe rc-boot stara się automatycznie wykryæ gdzie jest twój MBR (Master Boot Record).
BOOT=mbr |
Jeķli posiadamy więcej niŋ jeden obraz, moŋemy wskazaæ domyķlny, poprzez podanie nazwy pliku obrazu z katalogu /etc/sysconfig/rc-boot/images. Definiowanie tej opcji nie jest konieczne, gdyŋ rc-boot próbuje samemu wykryæ domyķlny system operacyjny, jednak w naszym przykģadzie ustawimy to "na sztywno":
DEFAULT=pld |
Tworzenie "obrazów"
Teraz moŋemy przejķæ do utworzenia plików obrazów. Mają one bardzo prostą budowę - są to pliki tekstowe skģadające się z kilku wierszy. Poniŋsza treķæ pliku jest wystarczającą konfiguracją do uruchomienia Linuksa, plikowi temu nadamy nazwę "pld".
TYPE=Linux ROOT=/dev/hda3 KERNEL=/boot/vmlinuz INITRD=/boot/initrd |
Opcja TYPE okreķla rodzaj systemu operacyjnego dla danego obrazu, mamy do wyboru następujące pozycje: Linux, DOS (DOS/Windows), BSD. Opcja ROOT wskazuje partycję na której znajduje się system, wartoķæ podana powyŋej jest tylko przykģadem. Wartoķci KERNEL i INITRD są wskazaniami do pliku kernela i pliku initrd - muszą odnosiæ się do wģaķciwych pozycji w katalogu /boot
Dla kaŋdego kolejnego obsģugiwanego systemu operacyjnego naleŋy dodaæ kolejny plik obrazu. Jeķli chcemy uŋywaæ systemu firmy Microsoft, naleŋy utworzyæ pusty plik o nazwie np. "windows" i umieķciæ w nim przykģadową konfigurację:
TYPE=dos ROOT=/dev/hda1 |
Na koniec generujemy bootloader uŋywając polecenia rc-boot.
# rc-boot pld taken as defult image image: pld * is linux on /dev/hda3 image: windows is dos on /dev/hda1 |
Uwagi
Program rc-boot nadpisze plik konfiguracji wybranego bootloadera, zanim więc uŋyjemy tego narzędzia powinniķmy na wszelki wypadek zrobiæ kopię bezpieczeņstwa wģaķciwego pliku.
Więcej szczegóģów moŋna uzyskaæ z podręcznika systemowego.
Kernel i urządzenia
Jądro systemu
Koncepcja jądra w PLD
Jedną z silniejszych stron PLD są dobrze przygotowane jądra systemu, pozwala to szybko uruchomiæ system produkcyjny bez zbędnych przygotowaņ. Poniŋej zamieszczono listę najistotniejszych cech jąder PLD:
funkcjonalnoķæ - nakģadanych jest wiele ģat rozszerzających moŋliwoķci domyķlnego kernela.
modularnoķæ - jądro jest tak maģe, jak to tylko moŋliwe; jeķli czegoķ potrzebujemy to wystarczy zaģadowaæ odpowiedni moduģ. Konsekwencją takiego rozwiązania jest koniecznoķæ uŋywania obrazu initrd, co zostaģo drobiazgowo omówione w sekcja Initrd.
elastycznoķæ - mamy wybór kilku jąder, przygotowanych w postaci binarnych pakietów dla kilku najczęstszych zastosowaņ; dzięki temu unikamy czasochģonnej kompilacji. Dostępne jądra zostaģy opisane w dalszej częķci rozdziaģu.
bezpieczeņstwo - domyķlny kernel ma nakģadaną ģatę grsecurity (www.grsecurity.net), ponadto moŋemy mieæ jądro z obsģugą Linux VServers (linux-vserver.org).
Podsumowując moŋna stwierdziæ, ŋe dla większoķci zastosowaņ jądra dystrybucyjne speģnią wszystkie stawiane przed nimi wymagania, bez koniecznoķci rekompilacji.
Informacje o uŋywanym jądrze
Uŋywaną wersję jądra sprawdzimy za pomocą programu uname:
# uname -r 2.6.14.7-5 |
# zcat /proc/config.gz |
# cat /usr/src/linux-2.6.27.13/config-dist |
Rodzaje jąder systemowych
Z PLD dostarczanych jest kilka kerneli, przygotowanych do róŋnych zastosowaņ, jedyną rzeczą jaka nam pozostaje to wybór wģaķciwego jądra dla naszej maszyny. W poniŋszej tabeli zamieszczono przykģadowe zestawienie dostępnych kerneli. Nie wszystkie z wymienionych poniŋej pakietów bezpoķrednio dostępne na liķcie pakietów, jeķli tak nie jest to trzeba je zbudowaæ samodzielnie ze speca.
Powyŋsze zestawienie naleŋy traktowaæ orientacyjnie, gdyŋ kernel ciągle się zmienia. Aby poznaæ szczegóģy, najlepiej jest sprawdziæ plik spec dla konkretnego kernela. Uģatwieniem w poszukiwaniu wģaķciwej rewizji, mogą byæ tagi zaczynające się od auto-, np.: auto-th-kernel-2_6_27_12-1. Tagi te są nadawane dla kaŋdej wersji pakietu trafiającego na serwery FTP/HTTP.
W wersjach Ra i Ac istniaģ podziaģ na kernel jednoprocesorowy (tzw. up) oraz wieloprocesorowy - SMP (symmetric multiprocessing). Dla odróŋnienia te z obsģugą wielu procesorów miaģy w nazwie pakietu przyrostek -smp. W Th i pakietach z ac-updates zaniechano takiego podziaģu i wszystkie jądra obsģugują wiele procesorów i jednoczeķnie zrezygnowano z przyrostka -smp.
Naleŋy zwróciæ uwagę, na inne przyrostki po sģowie kernel w nazwach pakietów, nie mówią one o rodzaju kernela ale o pakiecie z dodatkowymi moduģami: kernel-net, kernel-sound, kernel-video, dokumentacją: kernel-doc i inną zawartoķcią.
Aktualizacja
Kernel jest kluczową częķcią systemu, dlatego zaleca się inaczej podejķæ do jego aktualizacji niŋ do innych pakietów, dobrym zwyczajem jest instalacja nowej wersji, zamiast aktualizacji np.:
poldek> install -I kernel-2.6.14.7-5 |
Gdyby nowy kernel okazaģ się niestabilny, to zawsze moŋemy powróciæ do starej wersji. Aby uģatwiæ taką operację symlinki wskazujące na dotychczasowy kernel (/boot/vmlinuz) i initrd (/boot/initrd) automatycznie będą teraz dostępne pod nazwami /boot/vmlinuz.old i /boot/initrd.old. Dzięki temu, moŋemy w konfiguracji bootloadera mieæ "obraz" konfiguracji dla starego kernela i uŋyæ go w razie potrzeby.
Zaleŋnoķci
Istnieje kilka pakietów, bardziej lub mniej zaleŋnych od konkretnej wersji kernela. Ķcisģe zaleŋnoķci będą dotyczyģy pakietów z moduģami np. kernel-vanilla-sound-alsa oraz pakietów ķciķle wspóģpracujących z kernelem np. moduģ kernel-video-nvidia ze sterownikiem X.Org: xorg-driver-video-nvidia. Nieco mniej oczywisty jest związek kernela z pakietami iproute2 czy iptables, w ich przypadku mamy nieco swobody.
W wielu sytuacjach nie będziemy musieli się o to martwiæ, gdyŋ ten problem zaģatwiają nam zaleŋnoķci. Mimo to, ŋe mamy tu dostępną automatykę, przy tego rodzaju pakietach powinniķmy zachowaæ zdwojoną czujnoķæ. Dla waŋnych maszyn produkcyjnych warto dodaæ kernel i pakiety okoģokernelowe do opcji hold w Poldku, opcję tą omówiliķmy w sekcja Poldek w rozdziaģ Zarządzanie pakietami. Więcej o zaleŋnoķciach pomiędzy pakietami w sekcja Cechy pakietów w PLD w rozdziaģ Zarządzanie pakietami.
Uwagi
Czasami zdarza się, ŋe zaģamuje się praca systemu sygnalizowana za pomocą komunikatu Kernel Panic, jądro informuje nas, ŋe nie wie co ma dalej zrobiæ i przerywa pracę. Warto ustawiæ system tak, by po takim zdarzeniu automatycznie następowaģ restart, konfigurację takiego zachowania opisaliķmy w sekcja Podstawowe ustawienia w rozdziaģ Konfiguracja systemu.
Parametry jądra
Mamy moŋliwoķæ wpģywania na pracę systemu, dzięki modyfikowaniu specjalnych parametrów jądra, parametry te moŋna podzieliæ na dwie grupy: podawane przed startem kernela oraz podawane po wystartowaniu. Pierwszy rodzaj zostaģ opisany w sekcja Wstęp w rozdziaģ Bootloader, drugi to zestaw specjalnych wpisów do pseudo-systemu plików /proc/sys.
Czytaæ wartoķci moŋemy za pomocą programu cat np.:
# cat /proc/sys/net/ipv4/ip_forward |
# echo "1" > /proc/sys/net/ipv4/ip_forward |
# /sbin/sysctl net.ipv4.ip_forward |
# /sbin/sysctl net.ipv4.ip_forward=1 |
Wadą powyŋszego rozwiązania jest powrót do poprzednich ustawieņ po restarcie maszyny. Rozwiązaniem problemu jest korzystanie z pliku /etc/sysctl.conf, w nim przypisujemy wartoķci odpowiednim zmiennym. W celu wprowadzenia ustawieņ wywoģujemy polecenie:
# /sbin/sysctl -p |
Moduģy jądra
Czym są?
Sterowniki mogą byæ wkompilowane do wnętrza jądra lub wydzielone jako osobne obiekty - moduģy. Moduģy jądra zostaģy stworzone po to by kernel zajmowaģ maģo pamięci operacyjnej i byģ zarazem uniwersalny. Uģatwiają one takŋe prace ludziom zaangaŋowanym w rozwój jądra i dodatkowych moduģów (nie potrzeba kompilowaæ caģego kernela by sprawdziæ zmiany, wystarczy tylko sam moduģ) Wyobraž sobie sytuację, w której masz wkompilowane do niego wszystko, a twój system nie posiada urządzeņ, które kernel potrafi obsģuŋyæ. Jest to duŋe marnotrawstwo, poniewaŋ w pamięci znajdą się nie potrzebne nam funkcje. Dodaæ naleŋy fakt, ograniczenia wielkoķci jądra (moŋna to zmieniæ odpowiednimi przeróbkami žródeģ via Red Hat). Dlatego lubimy moduģy. Dają nam one moŋliwoķæ wyboru między tym co niezbędne, a brakiem wsparcia dla urządzeņ. Podsumowując. Nie potrzebujesz to nie uŋywasz.
By móc uŋywaæ moduģów potrzebujesz dwóch rzeczy. Kernela z
wkompilowaną opcją Loadable module support
oraz sterowników skompilowanych jako moduģy. Poniewaŋ
uŋywasz PLD to nie masz co się gģowiæ poniewaŋ wszystko
to masz u siebie w systemie.
Zaģadowanie wģaķciwego moduģu dla urządzenia
Istnieją dwie metody zaģadowania moduģów:
statyczna - metoda tradycyjna, polega na wskazaniu moduģów do zaģadowania przez administratora
dynamiczna - automatyczne ģadowanie moduģów, kiedy urządzenie zostaje wykryte
Konfiguracja moduģów
Plik /etc/modprobe.conf jest przeznaczony do ustawiania opcji dla ģadowanych moduģów. Warto dodaæ iŋ we wczeķniejszych wersjach kernela ( < 2.6.0) plik nazywaģ się /etc/modules.conf. W pliku mamy dostępnych wiele opcji, my omówimy tylko najczęķciej uŋywane: alias, option i blacklist.
Aliasy - są to dodatkowe nazwy dla moduģów, pozwalają na wczytanie go odwoģując się do aliasu. Z aliasów korzysta wiele programów, które nie mogą wiedzieæ z jakiego moduģu mają korzystaæ i uŋywają ustalonych nazw (aliasów) np.:
alias eth0 8139too |
alias parport_lowlevel parport_pc |
Opcje - często uŋywa się moŋliwoķci przesģania do moduģu ustawieņ. Przedstawię to na przykģadzie drukarki podpiętej do portu LPT:
options parport_pc io=0x378, irq=7 |
Czarna lista - moŋemy zabroniæ ģadowania jakiegoķ moduģu za pomocą sģowa kluczowego blacklist np.:
blacklist rivafb |
Statyczne zarządzanie moduģami
Okreķlenie moduģu dla urządzenia
W zaleŋnoķci od naszych wymagaņ oraz zastosowania systemu operacyjnego, będzie się zmieniaæ liczba wymaganych sterowników, w większoķci wypadków będzie to wartoķæ od kilku do kilkunastu moduģów. Jeķli tych moduģów jest maģo to samodzielne ģadowanie moŋe byæ lepszym rozwiązaniem.
Aby wskazaæ odpowiedni moduģ, musimy poznaæ dane urządzenia. Najbardziej interesującymi informacjami są: producent i model urządzenia lub uŋyty chipset. W większoķci wypadków te informacje znajdują się w dokumentacji urządzenia. Jeķli tak nie zdobędziemy szukanych informacji to moŋemy spróbowaæ uŋyæ którąķ z poniŋszych metod:
Organoleptycznie - jeķli mamy dostęp do sprzętu to moŋemy obejrzeæ urządzenie, opis moŋe byæ umieszczony na pģytce drukowanej lub na chipsecie (zwykle największy ukģad scalony).
lshw - zaawansowany program sģuŋący do wyķwietlania szczegóģowych danych o sprzęcie, jego zaletą jest duŋa iloķæ sprawdzanych podsystemów i wyķwietlanie nazw uŋywanych moduģów przez konkretne urządzenie.
lspci - program ten wyķwietla listę wykrytych urządzeņ PCI/AGP wraz z dodatkowymi informacjami. Warto uŋyæ tu dodatkowo opcji "-v" - "-vv" w celu zwiększenia iloķci danych. Program ten znajdziemy w pakiecie pciutils.
Komunikaty jądra - są to dosyæ cenne informacje, moŋemy je odczytaæ w dzienniku kernela: /var/log/kernel lub przejrzeæ to co zwraca program dmesg:
# dmesg | less
Kiedy uzyskaliķmy informacje o sprzęcie, pozostaje nam odnaležæ moduģ:
pcidev - program z pakietu pci-database - stara się wykryæ uŋywany przez nas sprzęt oraz podaje nazwę sugerowanego moduģu. Naleŋy wywoģaæ program z parametrem wskazującym o interesujące nas urządzenie np:
drugi zwrócony ģaņcuch jest nazwą szukanego moduģu. Aby otrzymaæ listę parametrów jakie przyjmuje program naleŋy uruchomiæ go bez parametru. Uwaga: w celu okreķlenia moduģu kontrolera dysku nie naleŋy uŋywaæ parametru 'ide', tylko 'sata', gdyŋ linia sterowników IDE jest przestarzaģa. Zamiast niej naleŋy uŋywaæ tych opartych na libata.# pcidev agp 10de01e0 nvidia-agp nVidia Corporation|nForce2 AGP (different version?)
Internet - moŋna zaģoŋyæ, ŋe ktoķ się juŋ spotkaģ z podobnym problemem. Mamy do dyspozycji sporą skarbnicę wiedzy: WWW, listy i grupy dyskusyjne.
Po nazwie moduģu: modprobe -l {$sģowo_kluczowe} - tak moŋemy próbowaæ odnaležæ moduģ wg. szukanego klucza np:
# modprobe -l *snd* /lib/modules/2.6.11.6-4/kernel/sound/pcmcia/pdaudiocf/snd-pdaudiocf.ko.gz /lib/modules/2.6.11.6-4/kernel/sound/pcmcia/vx/snd-vxp440.ko.gz /lib/modules/2.6.11.6-4/kernel/sound/pcmcia/vx/snd-vx-cs.ko.gz /lib/modules/2.6.11.6-4/kernel/sound/pcmcia/vx/snd-vxpocket.ko.gz /lib/modules/2.6.11.6-4/kernel/sound/drivers/snd-serial-u16550.ko.gz /lib/modules/2.6.11.6-4/kernel/sound/drivers/mpu401/snd-mpu401-uart.ko.gz /lib/modules/2.6.11.6-4/kernel/sound/drivers/mpu401/snd-mpu401.ko.gz
modinfo - program ten zwraca informacje o module, którego nazwę podajemy jako parametr. Program jest pomocny jeķli zawęziliķmy listę pasujących moduģów do kilku pozycji.
Zarządzanie moduģami
Moduģy są ze sobą powiązane i zaģadowanie danego moduģu zaģaduje moduģy od niego zaleŋne (jeķli takie są), podobnie jest z ich usuwaniem z pamięci. Do zarządzania moduģami zaleca się uŋywanie programu modprobe z odpowiednimi parametrami zamiast programów insmod i rmmod
Listę zaģadowanych moduģów i zaleŋnoķci między nimi otrzymamy po wydaniu polecenia lsmod np:
# lsmod Module Size Used by lp 8644 0 parport 29896 1 lp ext3 119304 1 amd74xx 11676 0 [permanent] psmouse 34840 0 ide_core 109560 2 ide_disk,amd74xx ide_disk 14336 9 |
Wczytanie moduģu do pamięci:
# modprobe ne2k-pci |
# modprobe -r ne2k-pci |
# modprobe --show-depends ne2k-pci insmod /lib/modules/2.6.11.6-4/kernel/drivers/net/8390.ko.gz insmod /lib/modules/2.6.11.6-4/kernel/drivers/net/ne2k-pci.ko.gz |
# modprobe -l |
Po "ręcznym" zaģadowaniu moduģu do pamięci będzie on dostępny do czasu ponownego uruchomienia komputera, aby moduģ byģ automatycznie ģadowany przy starcie systemu musimy uŋyæ opisanych dalej plików: /etc/modules lub /etc/modprobe.conf.
/etc/modules
Plik ten zawiera listę moduģów, które zostaną zaģadowane podczas startu systemu (przez rc-skrypty). Znając nazwę moduģu moŋemy dodaæ ją do tego pliku np:
echo "via82cxxx_audio" >> /etc/modules |
/etc/modprobe.conf
W sekcja Moduģy jądra powiedzieliķmy, ŋe plik /etc/modprobe.conf sģuŋy do konfiguracji moduģów, jednak za pomocą pewnej sztuczki będziemy mogli wskazywaæ moduģy do zaģadowania. Polega ona na utworzeniu aliasów o ustalonych nazwach i które będą ģadowane np. przez rc-skrypty. Przykģadowo utworzenie aliasu eth0 do odpowiedniego moduģu karty sieciowej spowoduje zaģadowanie danego moduģu przy próbie podniesienia interfejsu pierwszego interfejsu Ethernet. Przykģadowy alias:
alias eth0 8139too |
eth{$Nr} - opisany powyŋej alias dla karty sieciowej typu Ethernet.
ide_hostadapter, scsi_hostadapter - aliasy do moduģów kontrolerów pamięci masowych, uŋywane są m.in. przez skrypt geninitrd.
char-major-116, snd-card-{$Nr}, char-major-14, sound-* - aliasy dla moduģów kart muzycznych (ALSA).
alias eth0 8139too alias scsi_hostadapter sata_sil alias char-major-116 snd alias snd-card-0 snd-intel8x0 |
Udev - dynamiczna obsģuga sprzętu
Statyczne zarządzanie moduģami kernela i urządzeniami w /dev byģo skomplikowane, uciąŋliwe i wymagaģo praw administratora, stąd narodziģa się idea systemu, który zautomatyzuje te czynnoķci. Tak oto powstaģ udev, wspóģczesne wersje udeva (następcy DevFS) mają wbudowaną obsģugę hotpluga i coldpluga. Dzięki temu mogą automatycznie ģadowaæ potrzebne moduģy, ma to sens wyģącznie w przypadku modularnego kernela, jaki jest dostępny w PLD. Mimo wģączenia hotpluga do udeva w PLD ciągle dostępne są pakiety z hotplugiem, są przechowywane jedynie dla wstecznej zgodnoķci i nie będą nam juŋ potrzebne.
Poza nielicznymi wypadkami nie będzie juŋ konieczne dopisywanie nazw moduģów do pliku /etc/modules, ani ich ręczne ģadowanie za pomocą programu modprobe.
Więcej o plikach urządzeņ znajdziemy w sekcja Urządzenia.
Instalacja
W systemie domyķlnie instalowany jest pakiet dev, jeķli zechcemy przejķæ na udev to wystarczy, ŋe zainstalujemy pakiet udev a następnie odinstalujemy dev np.:
# poldek -i udev # poldek -e dev |
Konfiguracja
Udev w większoķci wypadków nie wymaga ŋadnych operacji konfiguracyjnych, czasami tylko konieczne jest poprawienie lub dodanie reguģki do katalogu /etc/udev/rules.d/. Zanim się tym zajmiemy powinniķmy zapoznaæ się z dokumentacją.
W Ac do wyboru są dwa tryby pracy: udevstart (domyķlny) i udevsynthesize. Ten drugi wykrywa większą liczbę urządzeņ, stąd warto się pokusiæ o wybór wģaķnie jego. Aby go uŋywaæ wystarczy, ŋe ustawimy odpowiednią opcję w pliku /etc/udev/udev.conf:
UDEV_STARTER="udevsynthesize" |
W Th powyŋsze opcje nie są juŋ dostępne, ich miejsce zająģ mechanizm udevtrigger.
Udev w praktyce
Liczba zaģadowanych moduģów przez udev moŋe przywróciæ o zawrót gģowy, udev ģaduje moduģy znalezionych urządzeņ bez względu czy w ogóle z niego korzystamy. Jedyną wadą takiego dziaģania jest większe zuŋycie pamięci przez nieuŋywane sterowniki. Nie powinno przekroczyæ 2MiB pamięci, więc dla ogromnej większoķci wspóģczesnych komputerów nie będzie to stanowiæ ŋadnego problemu.
Mamy wpģyw na listę ģadowanych moduģów, aby zablokowaæ ģadowanie jakiegoķ moduģu wystarczy dodaæ do pliku /etc/modprobe.conf nazwę moduģu poprzedzoną sģowem blacklist np.:
blacklist rivafb blacklist nvidiafb |
Powyŋsza metoda ma sens jedynie jeķli chcemy zablokowaæ pojedyncze moduģy, jeķli mamy komputer o bardzo maģej iloķci pamięci lepszym pomysģem będzie pozostanie przy statycznej metodzie ģadowania moduģów.
Uwagi
Jeķli mamy kilka kontrolerów urządzeņ masowych (IDE/SATA/SCSI) to mogą występowaæ problemy z wykrywaniem ich na czas, tak by byģy gotowe do zamontowania systemów plików okreķlonych w /etc/fstab. Jedynym pewnym sposobem poradzenia sobie z tym kģopotem jest dodanie moduģów kontrolerów do initrd.
Więcej o udev moŋemy poczytaæ w FAQ
Udev nie zajmuje się montowaniem przenoķnych noķników danych, musimy robiæ to ręcznie (co wymaga uprawnieņ administratora), lub uŋyæ HAL-a, D-Busa oraz np. gnome-volume-manager w przypadku ķrodowiska Gnome.
Initrd
Wstęp
W PLD wszystkie moŋliwe sterowniki są dostępne w postaci tzw. moduģów, przez co nie są one "widoczne" dla jądra w trakcie startu systemu. Aby system wystartowaģ wymaganych jest kilka moduģów i innych komponentów koniecznych do zamontowania gģównego systemu plików (root filesystem):
moduģy kontrolera urządzeņ masowych (IDE/SATA/SCSI) np.: sata_nv, sata_sil, sd_mod
systemu plików na gģównej partycji systemowej np.: xfs, reiserfs
elementy konieczne do zģoŋenia woluminów opartych o LVM lub programowy RAID
Jedynym sposobem dostarczenia tych sterowników jest umieszczenie ich w specjalnym "obrazie" zwanym initrd (initial ramdisk). Obraz ten jest plikiem wczytywanym przez bootloader, tak więc dodatkowo musimy wģaķciwie skonfigurowaæ bootloader - wskazaæ poģoŋenie obrazu. Obraz przechowywany jest w katalogu /boot i ma nazwę initrd-{$wersja_jądra}.gz, do niego zaķ prowadzi ģącze o nazwie initrd.
Initrd jest tworzony przy kaŋdej instalacji/aktualizacji kernela. Bywa jednak, ŋe nasz obraz nie jest wygenerowany prawidģowo i jesteķmy zmuszeni do utworzenia go samodzielnie. Žle utworzony uniemoŋliwi uruchomienie systemu, ujrzymy wtedy następujący komunikat:
Kernel panic: VFS: Unable to mount root fs... |
Systemu nie moŋna uruchomiæ więc musimy skorzystaæ z operacji chroot-a, moŋemy w tym celu uŋyæ dowolnej dystrybucji linuksa jednak chyba najwygodniejsze będzie uŋycie PLD-Live lub RescueCD.
Przygotowanie
Poniŋej przedstawiono trzy metody generowania initrd. W większoķci wypadków wystarczy nam pierwszy ze sposobów, pozostaģe są trudniejsze gdyŋ musimy znaæ nasz sprzęt i system plików partycji "/". Jeķli obraz nie jest tworzony prawidģowo przez pierwszą metodę musimy się zadowoliæ dwoma pozostaģymi. Druga i trzecia metoda mają jedną zasadniczą przewagę nad pierwszą - mogą byæ przeprowadzane na dowolnej maszynie.
W dwóch pierwszych metodach uŋyjemy skryptu /sbin/geninitrd z pakietu geninitrd. Jest to wygodny automat, który stara się wykryæ sprzęt, system plików i czy gģówny system plików jest stworzony na LVM/soft RAID. Skrypt geninitrd wymaga prawidģowych wpisów w /etc/fstab i podmontowanego /proc. Tak więc jeķli generujemy initrd w systemie typu chroot to wydajemy polecenie (z chroota):
# mount /proc |
Opis wykrywania sprzętu i dobierania wģaķciwych moduģów opisano w sekcja Statyczne zarządzanie moduģami.
Automatyczne generowanie initrd
W razie potrzeby edytujemy plik /etc/sysconfig/geninitrd i ustawiamy jaki rodzaj urządzenia (SCSI, IDE, RAID) ma byæ automatycznie wykrywany:
## Do install SCSI modules (if / is on SCSI partition)? PROBESCSI=yes ## Do install IDE modules (if / is on IDE partition)? PROBEIDE=yes ## Do install RAID modules (if RAID is used)? PROBERAID=yes |
geninitrd [opcje] {$initrd} {$wersja_jądra} np.:
# geninitrd -v -f /boot/initrd-2.6.16.35-1.gz 2.6.16.35-1 |
Parametr -v odpowiada za "gadatliwoķæ" programu,
zaķ -f wymusza nadpisanie istniejącego obrazu.
Ręczne generowanie initrd
Metoda ta wymaga precyzyjnej znajomoķci uŋywanego sprzętu i systemu plików, gdyŋ sami musimy wskazaæ odpowiednie moduģy. Jest jednak konieczna, w przypadku problemów z automatycznym wykryciem wymaganych sterowników lub jeķli chcemy operację wykonaæ na innej maszynie niŋ docelowa.
Moŋemy wpisaæ listę koniecznych moduģów do odpowiedniej sekcji w pliku /etc/sysconfig/geninitrd:
## Basic modules to be loaded BASICMODULES="" ## Modules that should be loaded before anything (i.e. jbd for ext3) PREMODS="" |
geninitrd [opcje] --with={$nazwa_moduģu} {$initrd} {$wersja_jądra}
Duŋym uģatwieniem zadania jest automatyczne doģączanie moduģów zaleŋnych od wskazanego (o ile takie są). Poniŋej zamieszczono przykģadowe wywoģanie geninitrd dla systemu plików ext3 i kontrolera IDE PDC20268 firmy Promise:
# geninitrd -v --with=ext3 --with=pdc202xx_new /boot/initrd-2.6.16.35-1.gz 2.6.16.35-1 |
Gdy zawiedzie geninitrd
Moŋemy zmodyfikowaæ zawartoķæ obrazu wygenerowanego przez geninitrd, aby to zrobiæ rozpoczynamy od skopiowania initrd w inne miejsce i rozpakowania go:
# gunzip initrd-2.6.16.35-1.gz |
mkdir /tmp/initrd-src # mount -o loop initrd-2.6.16.35-1 /tmp/initrd-src |
Tworzenie initrd rozpocznijmy od skopiowania zawartoķci katalogu w inne miejsce:
# cp -a /tmp/initrd-src initrd-moje cp: czytanie `initrd-src/bin/sh': Bģąd wejķcia/wyjķcia |
Aby dodaæ moduģ, musimy go skopiowaæ z naszego systemu do odpowiedniego katalogu w initrd-moje/lib/modules/*/, następnie do skryptu initrd-moje/linuxrc dodaæ wpis "insmod {$moduģ}" na wzór juŋ istniejących ({$moduģ} musi zawieraæ peģną ķcieŋkę do pliku).
Przyszedģ czas na wygenerowanie initrd:
# genromfs -d initrd-moje -f initrd-nowy |
# gzip -9 initrd-nowy |
Bootloader
Musimy się upewniæ czy ģącze symboliczne /boot/initrd wskazuje na prawidģowy obraz. Jeķli uŋywamy LiLo wydajemy polecenie:
# lilo |
W przypadku Grub-a nic nie musimy robiæ.
Na koniec restartujemy komputer i system powinien uruchomiæ się bez problemu. Konfigurację bootloaderów szerzej opisano w sekcja Wstęp w rozdziaģ Bootloader.
Uwagi
Częste zmiany uŋywanego obrazu initrd mogą byæ uciąŋliwe, moŋna to obejķæ ģącząc do jednego obrazu większą iloķæ moduģów. Aby to zrobiæ moŋemy dopisaæ nazwy moduģów do przedstawionych poniŋej opcji w pliku /etc/sysconfig/geninitrd:
## Basic modules to be loaded BASICMODULES="" ## Modules that should be loaded before anything (i.e. jbd for ext3) PREMODS="" |
Urządzenia
Podobnie jak w innych systemach uniksowych obowiązuje tutaj zasada "everything is a file", czyli wszystko jest plikiem. Dzięki takiemu podejķciu uproszczono sposób komunikacji z urządzeniami, poprzez odwoģywanie się do specjalnych plików, odpowiadających konkretnym urządzeniom. Pliki te są przechowywane w katalogu /dev, zwykģy uŋytkownik nie musi się martwiæ o jego zawartoķæ, wystarczy ŋe będzie znaģ powiązania między fizycznymi urządzeniami a nazwami tych plików.
Z nazw urządzeņ najczęķciej korzysta się w przypadku operacji dyskowych, warto zatem znaæ zasadę ich okreķlania, więcej szczegóģów na ten temat podano w sekcja Nazewnictwo urządzeņ masowych w rozdziaģ Pamięci masowe.
Podstawowe informacje o urządzeniu
Nazwy urządzeņ nadawane są tak, aby uģatwiaæ ŋycie uŋytkownikom, dla jądra są wģaķciwie obojętne. Jądro rozróŋnia urządzenia za pomocą pary liczb: major (gģównej) i minor (pobocznej). To jakie są wartoķci tych liczb odczytamy następująco:
ls -l /dev/hda2 brw-rw---- 1 root disk 3, 2 2005-11-11 15:08 /dev/hda2 |
Jeķli potrzebujemy samodzielnie utworzyæ plik urządzenia, to uŋyjemy do tego programu mknod np.:
# /bin/mknod /dev/zero c 1 5 |
Systemy plików-urządzeņ
Są dwa sposoby dostarczania plików urządzeņ dla systemu: dev - statyczny i udev - dynamiczny. Kaŋdy z nich ma wsparcie w PLD, jednak domyķlnie instalowany jest pakiet udev. Jeķli chcemy uŋyæ innego mechanizmu, wystarczy ŋe odinstalujemy udev a zainstalujemy dev w jego miejsce, dla pewnoķci tą operację lepiej przeprowadzaæ przy pomocy operacji chroot-a.
Najstarszym z rozwiązaņ jest pakiet dev, dzięki niemu w katalogu /dev zostanie utworzona spora iloķæ węzģów (nawet jeķli nie mamy danego rodzaju urządzenia), wystarczająca dla większoķci zastosowaņ. Jeķli jednak mamy jakieķ egzotyczne urządzenie to będziemy musieli samemu utworzyæ wymagane pliki. Pliki urządzeņ tworzymy za pomocą opisanego wczeķniej programu mknod.
W odróŋnieniu od statycznej bazy plików urządzeņ w ostatnim czasie popularnoķæ zdobywają systemy automatycznego tworzenia węzģów w katalogu /dev. W chwili podģączenia urządzenia lub startu systemu automatycznie tworzone są wymagane pliki. Jest to ogromne uģatwienie dla uŋytkowników, gdyŋ nie wymaga od nich wiedzy na ten temat.
UDEV
Udev automatycznie tworzy pliki urządzeņ, jednak sam potrzebuje kilku z nich, aby mógģ zacząæ dziaģaæ, są to: /dev/console, /dev/null, /dev/zero. Pliki te są dostarczane razem z pakietem, a więc nie musimy się to martwiæ.
System udev jest wart uwagi dlatego, ŋe nie tylko tworzy wymagane węzģy urządzeņ lecz dodatkowo ģaduje wymagane moduģy jądra dla danego urządzenia. Więcej informacji o udev znajdziemy w sekcja Udev - dynamiczna obsģuga sprzętu
Naleŋy pamiętaæ o tym, ŋe udev jest wywoģywany z rc-skryptów, i nie wystartuje przy uŋycia parametru jądra init lub przy próbie wykonania operacji chroota z innego systemu. Wtedy wymagane pliki nie zostaną utworzone, co moŋe spowodowaæ nieoczekiwane problemy z dziaģaniem programów. W przypadku wykonania operacji chroota problem ten rozwiązujemy poprzez wczeķniejsze podmontowanie katalogu /dev z systemu gģównego. W pozostaģych przypadkach uruchamiamy skrypt /etc/rc.d/rc.sysinit, w ostatecznoķci tworzymy wymagane urządzenia za pomocą programu mknod lub skądķ je kopiujemy. Operacja chroota zostaģa szerzej opisana w sekcja Ratowanie systemu w rozdziaģ Administracja. Parametr jądra init jak i wiele innych szerzej opisano w sekcja Wstęp w rozdziaģ Bootloader.
Jaki system wybraæ?
Na stacji roboczej bez zastanowienia moŋna poleciæ udev, gdyŋ pozwoli na znaczne podniesienie komfortu pracy. W przypadku serwerów będzie to gģównie zaleŋaģo od preferencji administratora i wybór nie będzie miaģ tu większego znaczenia.
Zupeģnie inaczej to wygląda w przypadku systemów zamkniętych typu chroot, zarówno plikami urządzeņ jak i moduģami zajmuje się system gospodarz, ponadto udev moŋe staæ się powaŋnym wyģomem w bezpieczeņstwie klatki. W takim wypadku powinniķmy uŋyæ statycznych plików (dev), których lista powinna zostaæ powaŋnie ograniczona do kilku niezbędnych.
Konfiguracja systemu
Ten rozdziaģ prezentuje metody konfiguracji parametrów systemu.
Podstawowe ustawienia
Plik /etc/sysconfig/system przechowuje zaawansowaną konfigurację systemu, w rozdziale tym opisano częķæ z zawartych w nim opcji.
Konfiguracja skryptów startowych
Zmienna okreķla czy skrypty startowe mają uŋywaæ kolorów:
COLOR_INIT=yes |
Numer kolumny wyķwietlania wyniku dziaģania skryptu startowego:
INIT_COL=75 |
Szybsze uruchomienie systemu z pominięciem niektórych skryptów, startowych - m.in. skryptu od obsģugi języków:
FASTRC=no |
Zezwolenie na interaktywny start rc-skryptów (pytanie o uruchomienie kaŋdego z podsystemów) po wciķnięciu klawisza I:
RC_PROMPT=yes |
Opcje związane z jądrem
"Gadatliwoķæ" kernela dla komunikatów wysyģanych na konsolę tekstową. Opcja jest jednoznaczna z wywoģaniem polecenia dmesg -n {$nr} (domyķlnie 1):
CONSOLE_LOGLEVEL=1 |
Czas w sekundach, po którym nastąpi restart maszyny jeķli wystąpiģ krytyczny bģąd jądra (kernel panic). Waŋna opcja w przypadku komputerów, do których nie mamy fizycznego dostępu:
PANIC_REBOOT_TIME=60 |
Opcje uruchamiania systemu
Uruchomienie programu sulogin (pytanie o hasģo root-a) zamiast powģoki jeķli wystąpią problemy w trakcie uruchomienia:
RUN_SULOGIN_ON_ERR=yes |
Wartoķæ "yes" poniŋszej zmiennej pozwala na zalogowanie się uŋytkowników dopiero po zakoņczeniu procesu ģadowania systemu. Dzięki unikniemy potencjalnych problemów wynikających z przedwczesnym uzyskaniem dostępu, z drugiej jednak strony tracimy moŋliwoķæ zalogowania się (np. przez SSH) jeķli pojawią się problemy przed koņcem ģadowania systemu. Moŋe to byæ istotne dla systemów obsģugiwanych na odlegģoķæ.
DELAY_LOGIN=yes |
Opcja okreķla czy w czasie startu ma byæ usuwana zawartoķæ katalogu /tmp:
CLEAN_TMP=yes |
Wskazuje czy ma byæ zamontowany podsystem devfs:
MOUNT_DEVFS=no |
Usģugi
Domyķlny priorytet (liczba nice) dla usģug, którym nie go zdefiniowano w zmiennej SERVICE_RUN_NICE_LEVEL umieszczanej w pliku podstawowej konfiguracji usģugi (/etc/sysconfig/{$usģuga}):
DEFAULT_SERVICE_RUN_NICE_LEVEL=0 |
Lista katalogów przechowujących systemy typu chroot, które mają byæ zarządzane przez skrypt /etc/init.d/sys-chroots:
SYSTEM_CHROOTS=/jakis_katalog |
Ustawienia konsoli
Dzięki plikowi /etc/sysconfig/console moŋemy ustawiæ takie parametry jak czcionka konsoli, mapa klawiatury, kodowanie fontów oraz zarządzanie energią.
Aby zmieniæ czcionkę, edytujemy parametr:
CONSOLEFONT=lat2u-16 |
Do wyboru mamy czcionki zamieszczone w katalogu /usr/share/consolefonts.
Aby zmieniæ kodowanie znaków, edytujemy parametr:
CONSOLEMAP=8859-2 |
Aby zmieniæ mapowanie klawiatury edytujemy parametr:
KEYTABLE=pl2 |
Aby ustawiæ numery konsol dla których aplikowane są parametry, zmieniamy:
SET_FONT_TERMINALS="1 2 3 4 5 6 7 8" |
Przedstawiony parametr deklaruje zmianę ustawieņ dla konsol tty1-tty8.
Aby zmieniæ opcje zarządzania energią, edytujemy parametry:
POWER_SAVE=on BLANK_TIME=10 POWERDOWN_TIME=60 |
Parametr BLANK_TIME okreķla liczbę minut nieaktywnoķci do wygaszenia ekranu,
POWERDOWN_TIME - do wyģączenia monitora.
Aby zmieniæ kolor czcionki lub tģa, edytujemy parametr:
FOREGROUND_COLOUR=red BACKGROUND_COLOUR=green |
Do wyboru posiadamy kolory black|red|green|yellow|blue|magenta|cyan|white|default.
Aby zmieniæ domyķlny tryb NUM Locka, edytujemy parametr:
NUM_LOCK=on |
Do wyboru posiadamy atrybut "on" lub "off".
Aby uaktywniæ zmiany wykonujemy:
/sbin/service console start |
Internacjonalizacja
Wstęp
Częstym problemem początkującego uŋytkownika Linuksa jest ustawienie wyķwietlania znaków diakrytycznych, walut oraz odpowiedniego języka. Poniewaŋ PLD jest dystrybucją dla zaawansowanych uŋytkowników, moŋemy w niej przystosowaæ ķrodowisko pracy do naszych indywidualnych potrzeb.
Internacjonalizacja konsoli i programów
Zanim przystąpimy do instalowania poszczególnych paczek, musimy w pliku /etc/sysconfig/i18n ustawiæ odpowiednie zmiennie ķrodowiskowe odpowiadające za język czcionkę systemową oraz kodowanie. W naszym przypadku wpis ten wygląda następująco:
SUPPORTED_LOCALES=pl_PL LANG=pl_PL LC_ALL=pl_PL LINGUAS=pl_PL SYSFONT=lat2u-16 UNIMAP=lat2u SYSFONTACM=iso02 |
Następnie instalujemy pakiety odpowiedzialne za ustawienia lokalne i klawiaturę:
# poldek -i localedb-src kbd |
Locale generujemy poleceniem localedb-gen, które domyķlne ustawienia pobiera ze
zmiennej SUPPORTED_LOCALES wiec jeķli chcielibyķmy mieæ
obsģugę równieŋ innego języka, to trzeba to zaznaczyæ wģaķnie przy tej zmiennej.
Przykģadowy zapis dla kilku języków w pliku /etc/sysconfig/i18n moŋe wyglądaæ tak:
LANG=pl_PL
# list of supported locales
SUPPORTED_LOCALES="pl_PL/ISO-8859-2 de_DE/ISO-8859-2 \
en_GB/ISO-8859-1 en_US/ISO-8859-1" |
Moŋna teŋ zainstalowaæ pakiet zawierający bazę danych locale dla wszystkich lokalizacji obsģugiwanych przez glibc.
# poldek -i glibc-localedb-all |
Aby sprawdziæ czy wszystko przebiegģo pomyķlnie wydajemy polecenie:
$ locale LANG=pl_PL LC_CTYPE="pl_PL" LC_NUMERIC="pl_PL" LC_TIME="pl_PL" LC_COLLATE="pl_PL" LC_MONETARY="pl_PL" LC_MESSAGES="pl_PL" LC_PAPER="pl_PL" LC_NAME="pl_PL" LC_ADDRESS="pl_PL" LC_TELEPHONE="pl_PL" LC_MEASUREMENT="pl_PL" LC_IDENTIFICATION="pl_PL" LC_ALL= |
Sprawdzamy czy wszystkie wpisy się zgadzają.
Jeķli chcemy aby ustawienia dopasowane byģy do naszych upodobaņ do dyspozycji mamy następujące zmienne LC_*:
Dostępne zmienne LC_*:
* LC_CTYPE: Konwersja czcionki i wielkoķci liter.
* LC_COLLATE: Porządek sortowania.
* LC_TIME: Format wyķwietlania daty i godziny.
* LC_NUMERIC: Wyķwietlanie liczb nie związanych z walutą
* LC_MONETARY: Formaty walutowe.
* LC_MESSAGES: Format wiadomoķci informacyjnych, diagnostycznych \
oraz okreķlających interakcje programu.
* LC_PAPER: Rozmiar papieru.
* LC_NAME: Format nazw.
* LC_ADDRESS: Format wyķwietlania adresu i lokalizacji.
* LC_TELEPHONE: Format wyķwietlania numeru telefonu.
* LC_MEASUREMENT: Jednostki miary (metryczna lub inna)
* LC_IDENTIFICATION: Metadata o ustawieniach locale. |
Przykģadowo jako domyķlnego języka, moŋemy uŋywaæ angielskiego jednak ze wsparciem dla polskich czcionek i polskich walut. Wszelkiego typu zmiany dokonujemy poprzez dodanie do pliku ~/.bash_profile odpowiednich wpisów:
LANG=en_EN export LANG LC_CTYPE=pl_PL export LC_CTYPE |
Myszka pod konsolą
Wstęp
Niniejszy rozdziaģ dotyczy uruchomienia obsģugi myszy dla terminala znakowego, konfigurację myszy dla ķrodowiska graficznego (X-Window) opisano w sekcja X-Server w rozdziaģ X-Window. Proces konfiguracji rozpoczynamy od instalacji demona gpm:
# poldek -i gpm |
Dalsza częķæ konfiguracji polega na zaģadowaniu wģaķciwego moduģu jądra i ustawieniu przynajmniej dwóch parametrów w pliku /etc/sysconfig/mouse: nazwy urządzenia (DEVICE) i typu myszy (MOUSETYPE).
Poniŋszy opis dotyczy kernela 2.6.x, w tej wersji jako urządzenia dla myszy PS2 i USB stosuje się /dev/input/mouse0, /dev/input/mouse1, ... lub urządzenie zbiorcze /dev/input/mice. Jednak dla wstecznej zgodnoķci dziaģa dalej /dev/psaux
Szeregowa
Obsģuga portu szeregowego RS-232 jest częķcią jądra PLD, więc nie ģadujemy ŋadnego moduģu - urządzenia dziaģają od razu po podģączeniu. W zaleŋnoķci od tego, na którym porcie mamy podpiętą mysz, ustawiamy odpowiednio parametr DEVICE, pamiętając, ŋe /dev/ttyS0 to COM1, /dev/ttyS1 to COM2 ...
Typ myszy będzie zaleŋaģ od modelu posiadanego urządzenia, w większoķci wypadków powinna zadziaģaæ dla wartoķci "ms", "msc", lub "ms3". Szczegóģowe informacje na ten temat znajdziemy w pomocy demona, którą wyķwietlimy w sposób opisany na koņcu rozdziaģu.
DEVICE=/dev/ttyS0 MOUSETYPE=ms3 |
PS/2, TouchPad, TrackPoint
W laptopach urządzenia wskazujące są zgodne z myszkami typu PS/2, stąd ich konfiguracja przebiega tak samo. Rozpoczynamy od zaģadowania moduģu jądra:
# modprobe psmouse |
Podajemy urządzenie myszy i jej typ, który dla większoķci urządzeņ ustawimy na "ps2" lub "imps2":
DEVICE=/dev/input/mice MOUSETYPE=ps2 |
USB
Ģadowanie moduģów dla tego rodzaju urządzeņ moŋe byæ wykonane automatycznie przez mechanizm udev lub ręcznie. W drugim wypadku wydajemy następujące polecenia (zakģadam ŋe są juŋ zaģadowane moduģy dla kontrolera USB):
# modprobe usbhid # modprobe usbmouse |
Podajemy urządzenie myszy i jej typ, który dla większoķci urządzeņ ustawimy na ps2 lub imps2:
DEVICE=/dev/input/mice MOUSETYPE=ps2 |
Zakoņczenie
Teraz wystarczy tylko uruchomiæ usģugę gpm:
# /etc/init.d/gpm start |
Wczeķniej zaģadowane moduģy moŋna jeszcze wpisaæ do /etc/modules, aby ģadowaģy się przy starcie systemu.
Porady
Większoķæ dostępnych na rynku myszek powinna zadziaģaæ z przedstawioną powyŋej konfiguracją. Moŋliwe jednak, ŋe nasza mysz uŋywa nietypowego protokoģu i naleŋy ustawiæ inny typ urządzenia (MOUSETYPE). W takim wypadku pomocna moŋe się okazaæ lista urządzeņ i odpowiadających im typów wyķwietlana w wyniku poniŋszego polecenia:
# gpm -m /dev/input/mice -t help
Poŋyteczną opcją jest BUTTON_COUNT, która definiuje liczbę przycisków myszy.
Zamiast wskazania pliku urządzenia, moŋemy uŋyæ ģącza symbolicznego o nazwie /dev/mouse wskazującego na wģaķciwe urządzenie.
Strefa czasowa
Strefy czasowe to specjalne ustawienia, pozwalające systemowi na ģatwe przeliczanie czasu uniwersalnego (UTC) na lokalny i na odwrót. Zaczynamy od instalacji koniecznego pakietu:
$ poldek -i tzdata |
W Ac ustawiamy zmienne ZONE_INFO_AREA i TIME_ZONE. Opcje wskazują na katalog i plik opisujący strefę, jak zapewne czytelnik zauwaŋy, częķæ z nich nie jest przechowywania w podkatalogach, wtedy tą zmienną naleŋy ustawiæ pustą. Dla Polski wybieramy podajemy następujące wartoķci:
ZONE_INFO_AREA="Europe" TIME_ZONE="Warsaw" |
W Th powyŋsze opcje zostaģy zastąpione przez TIMEZONE, tutaj wartoķci oddzielamy slashem:
TIMEZONE="Europe/Warsaw" |
Aby zmiany odniosģy skutek musimy zrestartowaæ odpowiedni skrypt startowy:
# service timezone restart |
Zegar
Standardowo BIOS powinien uŋywaæ czasu uniwersalnego (UTC), zegar systemowy powinien wtedy dziaģaæ zgodnie z czasem lokalnym, okreķlonym w pliku /etc/sysconfig/timezone. W ten sposób zmiany czasu letni/zimowy będą następowaģy automatycznie, bez modyfikowania ustawieņ zegara sprzętowego.
Wyjątkiem od tej reguģy jest uŋywanie na tym samym komputerze PLD i któregoķ z produktów Microsoftu. Te ostatnie uŋywają zgodnego czasu dla BIOS-u i systemu, co spowoduje róŋnice we wskazaniach zegarów. Jedynym rozwiązaniem tego problemu jest zmuszenie naszego PLD, by uŋywaģ czasu BIOS-u jako czasu lokalnego. W tym wypadku zmianą czasu letni/zimowy moŋe zająæ się system Microsoftu lub moŋemy wykonaæ to samodzielnie.
Aby skorzystaæ z pierwszego rozwiązania synchronizujemy zegar sprzętowy z czasem uniwersalnym, a w pliku /etc/sysconfig/clock ustawiamy:
UTC="true" |
UTC="false" |
Zmienne ķrodowiskowe
Przeglądanie
Zmienne ķrodowiskowe to prosty sposób modyfikowania konfiguracji ķrodowiska uŋytkownika. Listę zmiennych i przypisanych im wartoķci uzyskamy za pomocą polecenia powģoki set, na poniŋszym przykģadzie przedstawiono fragment wyniku polecenia:
$ set BASH=/bin/bash BASH_VERSINFO=([0]="2" [1]="05b" [2]="0" [3]="2" [4]="release" [5]="i686-pld-linux-gnu") BASH_VERSION='2.05b.0(2)-release' COLORTERM=gnome-terminal COLUMNS=125 |
Konfiguracja globalna
Administrator moŋe ustawiæ globalnie wszystkim uŋytkownikom zmienne ķrodowiskowe. Do tego wykorzystuje się mechanizm env.d. Jest to katalog umieszczony w /etc, zawierający pliki tekstowe o nazwach takich samych jak nazwy zmiennych, wewnątrz kaŋdego z nich podana nazwa zmiennej i jej wartoķæ. Przykģadowo zmienna EDITOR zostanie zainicjowana jeķli utworzymy plik /etc/env.d/EDITOR, jego treķæ moŋe wyglądaæ następująco:
EDITOR=vim |
Zmiany w /etc/env.d są aktualizowane po ponownym zalogowaniu danego uŋytkownika.
Konfiguracja lokalna
Kaŋdy uŋytkownik moŋe zarówno tworzyæ takie zmienne jak i nadpisywaæ te ustawione globalnie.
Zmienne moŋemy powoģywaæ na czas sesji, dokonujemy tego przy pomocy powģoki (shell). W większoķci z nich (sh, zsh, bash, ksh) istnieje polecenie export które pozwala ustawiæ dowolna zmienną np.:
# export EDITOR=mcedit |
Tak ustawiona zmienna będzie funkcjonowaæ do czasu wylogowania uŋytkownika
Aby ustawiæ na staģe zmienną uŋyjemy pliku konfiguracyjnego powģoki. Musimy jedynie wstawiæ do takiego pliku podane wyŋej polecenie export. Kaŋda z powģok posiada swoje wģasne pliki startowe, przykģadowo powģoka BASH uŋywa pliku ~/.bash_profile i ~/.bashrc, zaķ ZSH ~/.zshenv. Więcej informacji na ten temat zawarto w manualu kaŋdej z powģok.
Jeķli chcemy ustawiæ zmienną ķrodowiskową tylko dla jednego uruchamianego programu, to podajemy jej definicję przed nazwą programu np.:
$ http_proxy=62.87.244.34:8080 wget http://foobar.com/plik.foo |
PLDconf - Narzędzie do konfiguracji systemu
Pldconf jest narzędziem tworzonym z myķlą o początkujących uŋytkownikach. Wiele opcji jest konfigurowanych automatycznie. Pldconf ma maģe wymagania i jest niewielkim pakietem (ok. 150 kB) Jego instalacja sprowadza się do wydania polecenia:
# poldek -i pldconf |
Program zadaje minimalną iloķæ pytaņ i w podstawowej wersji (dla PLD RA 1.0) konfiguruje:
Serwer X: karta (auto), rozdzielczoķæ, kolory, itd;
Sieæ: bramka, DNS, karty sieciowe (auto), otoczenie sieciowe, SDI, NEO (ethernet);
Desktop: menedŋer okien, kolory, czcionki i więcej;
Menedŋer startu: menu z linuksem i windows, dyskietka startowa i więcej;
Dostęp do partycji windows;
tyle z podstawowych moŋliwoķci - pldconf potrafi więcej.
Obecnie pldconf rozwijany jest dla nadchodzącego PLD 2.0 (AC/DC/NEST). W nowej wersji dodano między innymi:
Konfiguracje karty džwiękowej (alsa);
Konfiguracje drukarki (cups);
Optymalizacje dysku twardego (hdparm);
Konfiguracje fetchmail;
Konfiguracje tunera telewizyjnego
Zarządzanie kontami uŋytkowników
Wersja pldconf dla PLD 2.0 nieznacznie róŋni się od wersji dla PLD 1.0. Róŋnice dotyczą przede wszystkim zmiany ķcieŋek (np. /usr/X11R6/bin/mozilla w PLD 2.0 zmieniono na /usr/bin/mozilla) gģównie w module do konfiguracji desktopu. W praktyce blisko 100% pldconf w najnowszej wersji (przeznaczonym dla PLD 2.0) dziaģa poprawnie równieŋ w systemie PLD 1.0. W szczególnoķci najnowszy pldconf potrafi przeprowadziæ sieciową instalację PLD 2.0 - moduģ instalacji zadziaģa poprawnie w systemie PLD 1.0. Innymi sģowy, aby zainstalowaæ PLD 2.0 spod uruchomionego PLD 1.0 naleŋy zainstalowaæ najnowszą wersję pldconf.
Uwaga: W przypadku instalacji nowego pldconf w systemie PLD 1.0 wymagana jest równieŋ instalacja pakietu perl-modules.
Strona domowa projektu
Kluczowe pliki
W tym rozdziale przedstawione są informacje o kluczowych plikach systemu operacyjnego. Zostaģy tu opisane jedynie podstawowe dane na ich temat, więcej moŋna znaležæ w podręczniku systemowym man, oraz info
/etc/inittab
Plik /etc/inittab przechowuje konfigurację programu init, uruchamianego w trakcie startu systemu i dziaģającego bez przerwy do chwili jego zamknięcia. Gģównym zadaniem procesu init jest kontrola zachowania systemu w zaleŋnoķci od osiągniętego poziomu pracy systemu oraz w wypadku wystąpienia specjalnych zdarzeņ. Poziomy pracy szczegóģowo opisano w sekcja Zmiana poziomu pracy systemu w rozdziaģ Administracja.
Oto najwaŋniejsze opcje zawarte w pliku /etc/inittab:
Domyķlny poziom uruchomienia - wskazuje programowi init jaki poziom uruchomienia ma byæ wybrany jeķli wywoģano go bez parametrów lub w trakcie startu systemu. Wiersz okreķlający tę opcję wygląda następująco: id:{$poziom}:initdefault: ($poziom to cyfra odpowiadająca poprawnemu poziomowi uruchomienia), ustawienie domyķlnie trzeciego poziomu uruchomienia przedstawiono na poniŋszym przykģadzie:
id:3:initdefault:
Instrukcje uruchomienia programu mingetty na pierwszym terminalu wirtualnym (/dev/tty1), wywoģania dla kolejnych będą bardzo podobne:
1:12345:respawn:/sbin/mingetty --noclear tty1
Poniŋszy wiersz uruchomi program agetty, ģączący się z portem szeregowym /dev/ttyS0, w celu podģączenia terminala szeregowego:
Jeķli nie uŋywamy tego rodzaju urządzeņ to powyŋsze wywoģania są dla nas zbyteczne.0:12345:respawn:/sbin/agetty 9600 ttyS0 vt100
Wywoģania skryptów startowych - opcje te bardzo rzadko wymagają ingerencji uŋytkownika:
si::sysinit:/etc/rc.d/rc.sysinit l0:0:wait:/etc/rc.d/rc 0
Obsģuga specjalnych zdarzeņ np. wciķnięcia kombinacji klawiszy ctrl+alt+del:
ca::ctrlaltdel:/sbin/shutdown -t3 -r now
Mamy sporą dowolnoķæ w zarządzaniu tym zdarzeniem, w powyŋszym przykģadzie po naciķnięciu kombinacji ctrl+alt+del nastąpi przeģadowanie systemu, aby nastąpiģo zamkniecie powinniķmy uŋyæ polecenia shutdown -h.
/etc/fstab
Plik ten przechowuje szczegóģowe informacje o systemach plików, które mają byæ montowane do odpowiednich katalogów. Informacje w nim zawarte są odczytywane w trakcie startu systemu, dzięki temu automatycznie są montowane wszystkie woluminy (partycje) nie oznaczone opcją "noauto". Plik ten jest zazwyczaj tworzony przez instalator, jednak administrator ma moŋliwoķæ, a nawet obowiązek dokonywaæ w nim zmian. Dla lepszego zrozumienia tematu przyjrzyjmy się przykģadowemu plikowi i przeanalizujmy funkcje jakie speģniają poszczególne wpisy.
#(fs_spec) (fs_file)(fs_vfstype) (fs_mntops) (fs_freq) (fs_passno) /dev/hda2 / ext3 defaults 0 0 /dev/hda3 swap swap defaults 0 0 proc /proc proc defaults 0 0 pts /dev/pts devpts gid=5,mode=600 0 0 /dev/fd0 /media/floppy vfat noauto 0 0 /dev/cdrom /media/cdrom iso9660 noauto,ro,user,unhide 0 0 |
Jak widzimy plik jest podzielony na wiersze, z których kaŋdy odpowiada jednemu obsģugiwanemu woluminowi. Poszczególne pola oddzielone są od siebie spacją lub tabulatorem. Dane odpowiedniego rekordu wczytywane są przez skrypty startowe oraz programy takie jak: fsck, mount czy umount przez co muszą one byæ zapisane w uporządkowany sposób.
Pole (fs_spec) - okreķla urządzenie blokowe lub zasób sieciowy przeznaczony do zamontowania, na przykģad partycję dysku, CDROM czy udziaģ NFS. Opis urządzeņ masowych przedstawiono w sekcja Nazewnictwo urządzeņ masowych w rozdziaģ Pamięci masowe, montowanie udziaģów NFS przedstawiono w sekcja NFS - Network File System w rozdziaģ Usģugi dostępne w PLD.
Pole (fs_file) - wskazuje na miejsce, w którym ma byæ zamontowany dany system plików, na przykģad dla partycji wymiany (ang. "swap partition") to pole powinno zawieraæ wartoķæ "none", a dla CDROM-u "/media/cdrom".
Pole (fs_vfstype) - okreķla typ systemu plików jaki znajduje się na danym urządzeniu. Najbardziej powszechne obecnie i obsģugiwane systemy plików to:
ext2 - podstawowy system plików w Linuksie
ext3 - j.w. tyle ŋe z księgowaniem
reiserfs - zaawansowany system plików z księgowaniem
xfs - zaawansowany system plików z księgowaniem
vfat - uŋywany w starszych systemach Microsoftu, znany równieŋ jako FAT32
ntfs - system plików wspóģczesnych wersji systemów Microsoftu
iso9660 - uŋywany na pģytach CD-ROM
nfs - sieciowe udziaģy dyskowe NFS
swap - obszar wymiany
Pole (fs_mntops) udostępnia szereg znaczników systemowych, które mogą mieæ kluczowe znaczenie dla bezpieczeņstwa i wydajnoķci naszego systemu. Przykģadowo następujące znaczniki oznaczają:
defaults - domyķlny zestaw opcji, uŋyteczny w większoķci wypadków.
nodev - zapobiega rozpoznawaniu przez jądro dowolnych plików urządzeņ, znajdujących się w systemie plików
noexec - zapobiega wykonywaniu plików wykonywalnych w danym systemie plików
nosuid - zapobiega uwzględnianiu bitów set-UID oraz set-GID w przypadku dowolnego pliku wykonywalnego
ro - powoduje zamontowanie systemu plików w trybie tylko do odczytu, powstrzymując wszelkie modyfikacje informacji dotyczących plików, wģączając w to na przykģad czas dostępu do pliku
Pole (fs_freq) jest uŋywane przez program dump do wykrywania, który system plików ma mieæ wykonywaną kopię bezpieczeņstwa. Jeŋeli nie ma informacji o tym polu, zwracana jest wartoķæ 0 i dump przyjmuje, ŋe dany system plików nie musi byæ mieæ robionych kopii danych. Jeķli nie korzystamy z tego programu moŋemy wszędzie ustawiæ wartoķæ 0.
Pole (fs_passno) jest uŋywane przez program fsck aby zadecydowaæ, jaka powinna byæ kolejnoķæ sprawdzania systemów plików podczas ģadowania systemu. Gģówny system plików powinien mieæ (fs_passno) równą 1, zaķ inne systemy plików powinny mieæ (fs_passno) równe 2. Jeŋeli to pole nie posiada ŋadnej wartoķci lub jest ona równa 0 to wtedy dany system plików nie jest sprawdzany. Sprawdzania nie wymagają wģaķciwie systemy plików z księgowaniem, gdyŋ są bardzo odporne na awarie.
Uwaga! Najwaŋniejszym woluminem w systemie jest ten przypisywany do korzenia drzewa katalogów (katalog "/"), dlatego naleŋy bardzo ostroŋnie dokonywaæ zmian jego konfiguracji. Bģąd moŋe spowodowaæ problemy z uruchomieniem systemu operacyjnego.
/etc/passwd
Jeden z najwaŋniejszych plików w systemie - przechowuje informacje o kontach wszystkich uŋytkowników. Jeden wiersz w tym pliku zawiera informacje o jednym uŋytkowniku. Kaŋdy skģada się z pól rozdzielonych dwukropkiem:
login:haslo:UID:GID:komentarz:katalog_domowy:powģoka np.: marek:x:502:1000:Marek Kowalski:/home/users/marek:/bin/bash |
Uwagi: Znak "x" w miejscu hasģa oznacza ŋe jest przechowywane w osobnym pliku (/etc/shadow). UID to unikalny identyfikator uŋytkownika, zaķ GID to unikalny numer grupy gģównej uŋytkownika - zdefiniowany w pliku /etc/group. Powģoka (shell) musi byæ zdefiniowana w pliku /etc/shells. Oznaczenie powģoki jako /bin/false oznacza ŋe jest to konto uŋytkownika systemowego. Jest to specjalny rodzaj kont na które zwykli uŋytkownicy nie mogą się zalogowaæ
Plik ten jak i opisany poniŋej /etc/shadow mają kluczowe znaczenie dla systemu, dlatego nie naleŋy ich edytowaæ ręcznie. Narzędzia, sģuŋce do tego, opisano w sekcja Konta uŋytkowników w rozdziaģ Administracja.
/etc/shadow
Plik zawierający zakodowane hasģa i dodatkowe informacje dla systemu uwierzytelniania uŋytkowników np.:
marek:$1$qb/waABk$F3Y6dKw/6ekZPfcoTpzks/:12575:0:99999:5::: |
/etc/group
Plik zawierający nazwy utworzonych grup i przypisanych do nich uŋytkowników wedģug schematu:
nazwa_grupy::GID:login1,login2,login3,... np.: audio::23:kasia,marek |
Uwagi: Pierwsze pole to unikalna nazwa grupy, drugie nie ma we wspóģczesnych systemach uniksowych juŋ zastosowania, GID to niepowtarzalny identyfikator grupy, trzecie pole zawiera listę identyfikatorów uŋytkowników zapisanych do tej grupy.
Podobnie jak dwa powyŋsze, ten plik teŋ powinien byæ modyfikowany przez przeznaczone do tego programy, ich opis zawarto w sekcja Grupy w rozdziaģ Administracja
/etc/shells
Zawiera listę dostępnych dla uŋytkowników powģok np.:
/bin/ksh /bin/sh /bin/bash |
Aby uŋytkownik miaģ moŋliwoķæ korzystania z danej powģoki musi byæ ona zdefiniowana w tym pliku
/etc/motd
Wiadomoķæ dnia (ang. Message of the day) - Powitanie uŋytkownika: treķæ tego pliku wyķwietlana po uwierzytelnieniu się w systemie.
/etc/nologin
Plik tworzony przez administratora - blokuje moŋliwoķæ logowania się uŋytkowników do systemu. Przy próbie logowania wyķwietlana jest jego treķæ.
Pamięci masowe
Ten rozdziaģ opisuje operacje dyskowe takie jak podziaģ na partycje, tworzenie systemów plików i inne zaawansowane zagadnienia
Wstęp
Uwaga! Wszelkie operacje dyskowe naraŋają nas na nieodwracalną utratę danych, dlatego zaleca się stworzenie kopii zapasowej danych i zachowanie szczególnej ostroŋnoķci.
Nazewnictwo urządzeņ masowych
Numerowanie partycji
W Linuksie mogą byæ obsģuŋone cztery partycje podstawowe lub trzy podstawowe i jedna rozszerzona. Takie partycje są numerowane od 1 do 4, zaķ dyski logiczne kolejnymi numerami począwszy od 5. Podawanie numeru partycji ma sens wyģącznie w wypadku dysków twardych, nie podajemy ich dla urządzeņ takich jak napędy optyczne (CD/DVD), dyskietki czy teŋ woluminy logiczne. Nie podajemy go równieŋ w przypadku odwoģania do urządzenia fizycznego np. uŋywając programu fdisk lub hdparm.
Aby zorientowaæ się w ukģadzie partycji urządzenia moŋemy uŋyæ programu fdisk np.:
# fdisk -l /dev/hda |
Urządenia ATA (IDE)
Urządzenia ATA nazywane są wg. schematu: /dev/hd{$x}{$Nr} np. /dev/hda1.
Parametr {$x} jest maģą literą identyfikującą fizyczne urządzenie, zaķ {$Nr} to omówiony powyŋej numer partycji dyskowej. W odróŋnieniu od urządzeņ SATA i SCSI w interfejsie IDE litery te mają swoje specjalne znaczenie - wskazują sposób podģączenia urządzenia:
"a" -dysk nadrzędny (primary) podģączony do pierwszego kanaģu IDE
"b" -dysk podrzędny (slave) podģączony do pierwszego kanaģu IDE
"c" -dysk nadrzędny (primary) podģączony do drugiego kanaģu IDE
"d" -dysk podrzędny (slave) podģączony do drugiego kanaģu IDE
Urządenia SCSI/SATA/USB Storage
Dyski twarde i pamięci flash mają oznaczenia /dev/sd{$x}{$Nr} np. /dev/sda1. Symbol {$x} to oznaczenie fizycznego urządzenia, którym przypisywane są kolejne litery zaczynając od "a", zaķ {$Nr} to opisany na początku numer partycji. Napędy optyczne (CD/DVD) są oznaczane jako /dev/sr{$Nr} np.: /dev/sr0.
LVM
Woluminy logiczne mają dowolne nazwy - nadawane przez administratora w trakcie ich zakģadania. Jeķli pliki urządzeņ nie są utworzone statycznie, to mogą byæ wykrywane automatycznie (przy starcie systemu) i wtedy nadawane są im nazwy w konwencji /dev/mapper/$VG-$LV np. /dev/mapper/sys-home.
RAID programowy
Urządzenia mają nazwy wg. schematu: /dev/md{$nr}, np. /dev/md0, które z kolei jest symlinkiem do /dev/md/0.
Urządzenia w GRUB-ie
GRUB ze względu na swoja wieloplatformowoķæ uŋywa wģasnego schematu nazewnictwa. Dyski fizyczne są widoczne jako (hd{$NR}), np. (hd1) zaķ partycje jako (hd{$NR1},{$NR2}) np. (hd1,2). Urządzenia te nie są bezpoķrednio powiązane z plikami urządzeņ w katalogu katalogu /dev i programy poza GRUB-em nie mogą z nich korzystaæ. Więcej w opisie bootloadera, w sekcja GRUB w rozdziaģ Bootloader.
Podziaģ na partycje
Partycje
Na dysku twardym moŋemy utworzyæ do czterech partycji podstawowych (primary partition) lub do trzech partycji podstawowych i jednej rozszerzonej (extended partition). Partycję rozszerzoną moŋemy podzieliæ na liczne dyski logiczne (logical partitions).
Partycje szerzej opisano m.in. w Wikipedii, zaķ sposób ich oznaczania przedstawiono w sekcja Nazewnictwo urządzeņ masowych. Opis systemu plików-urządzeņ z katalogu /dev odnajdziemy w sekcja Urządzenia w rozdziaģ Kernel i urządzenia.
Zanim zaczniemy
Operacje na partycjach mogą skoņczyæ się utratą danych, dlatego warto najpierw zrobiæ zrzut tablicy partycji do pliku:
# sfdisk -d /dev/hda > hda.out |
# sfdisk /dev/hda < hda.out |
Wymagane miejsce na system
Wymagania dyskowe w PLD (nie licząc danych, logów i obszaru wymiany):
instalacja minimalna - poniŋej 150MB
serwer - duŋo zaleŋy od zainstalowanych usģug, naleŋy zaģoŋyæ, ŋe zajmie co najmniej 250MB; dla większej elastycznoķci i stabilnoķci warto przeznaczyæ większy zapas miejsca, niŋ w przypadku maszyn domowych.
stacja robocza z XWindow - naleŋy przeznaczyæ przynajmniej 1GB miejsca
Osobnym zagadnieniem jest wielkoķæ obszaru wymiany, stara zasada mówiąca, aby swap byģ dwukrotnie większy niŋ pamięæ operacyjna, sprawdza się większoķci wypadków. Naleŋy jednak podejķæ do tego elastycznie i dobraæ objętoķæ obszaru wymiany odpowiednio do charakterystyki pracy maszyny.
Plan podziaģu dysku
Dla stacji roboczych zazwyczaj wystarczy podziaģ na dwie partycje, które będą uŋyte dla: "/" (gģównego drzewa) i obszaru wymiany (swap). W przypadku serwerów duŋo będzie zaleŋaģo od zastosowania maszyny i preferencji administratora, lecz jako minimum naleŋy dodatkowo przydzieliæ partycję dla gaģęzi /var.
W obu zastosowaniach dla wygody i bezpieczeņstwa nierzadko tworzy się dodatkową partycję dla katalogu /home, pozwala to na ģatwiejsze zarządzanie uprawnieniami i uģatwia wiele operacji. Partycję na katalogi domowe naleŋy traktowaæ jako obowiązkową jeķli na maszynie będą dostępne konta z dostępem do powģoki (shella). Jej wielkoķæ bezpoķrednio zaleŋy od planowanej iloķci przechowywanych danych.
Jeķli od maszyny wymagamy zwiększonej niezawodnoķci moŋna utworzyæ maģą partycję dla katalogu /boot, w którym są trzymane waŋne pliki systemowe. Dane w katalogu /boot zaraz po zainstalowaniu nie powinny przekroczyæ ok. 7MB, aby więc mieæ moŋliwoķæ instalacji kilku kerneli, musimy przeznaczyæ na taką partycję co najmniej 25MB miejsca. Dzięki temu zwiększymy szanse na uruchomienie systemu z uszkodzonym gģównym systemem plików. Jest to szczególnie zalecane w przypadku uŋycia bootloadera GRUB, ze względu na jego specyficzną konstrukcję, więcej na temat GRUB-a znajdziemy w sekcja GRUB w rozdziaģ Bootloader.
Programy do zarządzania partycjami
fdisk - interaktywny program do zarządzania partycjami, wydane polecenia zostaną wykonane na samym koņcu - po operacji zapisu zmian. Wģaķnie ten program zostanie uŋyty w naszych przykģadach, wywoģujemy go z parametrem okreķlającym urządzenie z katalogu /dev.
cfdisk - wygodne narzędzie, wyposaŋone w semigraficzny interfejs uŋytkownika. Twórcy uģatwili ŋycie początkującym, poprzez ukrywanie partycji rozszerzonych, tworzeniem i ich usuwaniem zajmuje się program bez naszego udziaģu. Podobnie jak fdisk zapisuje zmiany do tablicy partycji na samym koņcu. Wywoģujemy go z parametrem okreķlającym urządzenie z katalogu /dev.
parted - jest potęŋnym narzędziem, umoŋliwiającym wiele operacji niedostępnych dla obu poprzednich programów. Oprócz podstawowych operacji na partycjach umoŋliwia takie operacje jak zmianę wielkoķci partycji, tworzenie obrazów partycji i inne. Istotną róŋnicą w dziaģaniu w porównaniu dla powyŋszych narzędzi jest natychmiastowe wprowadzanie zmian, stąd zaleca się zachowanie duŋej ostroŋnoķci przy korzystaniu z niego.
GParted/QtParted - programy dla X-Window oparte o parted. Mają interfejs wzorowany na programie Partion Magic z systemu MS Windows.
sfdisk - program obsģugiwany za pomocą argumentów i danych przesyģanych na wejķcie standardowe. Jest dosyæ trudny w obsģudze ale za to moŋe byæ uŋywany w skryptach.
Podziaģ
Poniŋsze przykģady będą dotyczyæ programu fdisk, cfdisk jest bardzo prosty w obsģudze i nikt nie powinien mieæ nim problemów, zaķ opis parted wykracza poza ramy tego rozdziaģu.
Aby sprawdziæ czy na dysku /dev/sda są jakieķ partycje uŋyjemy następującego polecenia:
# fdisk -l /dev/sda |
# fdisk /dev/sda Command (m for help): |
Command action e extended p primary partition (1-4) |
Dla kolejnych partycji powtarzamy caģy proces, aŋ uzyskamy to co zaplanowaliķmy. Opcją p) wyķwietlamy planowany ukģad partycji. Po zakoņczeniu podziaģu przypisujemy typy partycji opcją t) podając kolejno: numer partycji, Jeķli wybrany podziaģ nam odpowiada to zapisujemy zmiany na dysk (do tablicy partycji) przez wybór opcji w.
Zakoņczenie
Jeķli ŋadna z partycji nie byģa uŋywana w trakcie podziaģu na partycje (np. zamontowana) to tablica partycji jest ponownie odczytywana i od razu moŋemy wykonywaæ dalsze prace. W przeciwnym wypadku musimy jeszcze przeģadowaæ system. Po zakoņczeniu dzielenia dysku pozostaģo nam utworzenie systemów plików, które zostaģo opisane w sekcja Systemy plików.
Systemy plików
W tym rozdziale omówimy tworzenie jednej z dwóch moŋliwych struktur na partycji lub urządzeniu - systemu plików lub obszaru wymiany (swap).
Wybór systemu plików
Rodzaj uŋytego systemu plików zaleŋy od planowanego zastosowania. W Linuksie najbardziej uniwersalnym i popularnym systemem plików jest ext2. Swoją pozycję uzyskaģ dzięki temu, ŋe jest prostym i stosunkowo wydajnym systemem plików. Ponadto jako jeden z niewielu systemów plików nadaje się do uŋytku na dyskietkach i bardzo maģych partycjach.
W pozostaģych zastosowaniach moŋemy ķmiaģo uŋyæ systemów plików z tzw. księgowaniem (journaling) np.: ext3, ReiserFS, XFS, JFS ze względu na duŋe bezpieczeņstwo przechowywania danych. Dla zastosowaņ wymagających wysokiej niezawodnoķci najlepszy będzie ext3, pozostaģe z wymienionych moŋna poleciæ w systemach wymagających duŋej wydajnoķci i wszędzie tam gdzie występują duŋe iloķci plików.
Aby z partycji mogģy równieŋ korzystaæ systemy Microsoftu musimy utworzyæ na niej system plików vfat. Utracimy jednak wtedy wszystkie zalety uniksowych systemów plików.
Tworzenie systemu plików
Programy do tworzenia konkretnych systemów plików róŋnią się nazwami, ģatwo je rozpoznamy gdyŋ ich nazwy zaczynają się od "mkfs." np.:
/sbin/mkfs.ext2 /sbin/mkfs.ext3 /sbin/mkfs.reiserfs /sbin/mkfs.msdos /sbin/mkfs.vfat /sbin/mkfs.xfs |
Aby utworzyæ system plików wywoģujemy odpowiedni program z nazwą urządzenia jako parametrem, na poniŋszym przykģadzie przedstawiono tworzenie systemu plików ext2 na drugiej partycji podstawowej:
# /sbin/mkfs.ext2 /dev/sda2 |
Powyŋej przedstawiono jedynie skróconą listę wszystkich dostępnych programów, programy te są dostępne w odpowiednich pakietach, przykģadowo narzędzia dla systemu plików xfs odnajdziemy w pakiecie xfsprogs.
Tworzenie obszaru wymiany
Do tworzenia obszaru wymiany uŋywamy programu mkswap np.:
# mkswap /dev/hda5 |
Podmontowanie partycji / aktywacja swapu
Partycje i obszary wymiany są montowane/wģączane przez rc-skrypty w trakcie uruchamiania systemu wg. opcji zawartych w pliku /etc/fstab (o ile tam zostaģy dodane). W pozostaģych wypadkach systemy plików montujemy poleceniem mount z odpowiednimi opcjami np.:
# mount /dev/sda2 /katalog_docelowy |
Obszary wymiany aktywujemy następująco:
# /sbin/swapon /dev/hda5 |
Szczegóģowy opis pliku /etc/fstab oraz rc-skryptów przedstawiono w sekcja Kluczowe pliki w rozdziaģ Konfiguracja systemu.
Poznanie typu systemu plików
Aby dowiedzieæ się jaki typ systemu plików jest na
danej partycji, uŋyjemy programu
file z opcją -s:
# file -s /dev/hda2 /dev/hda1: SGI XFS filesystem data (blksz 4096, inosz 256, v2 dirs) |
# blkid /dev/md/0: UUID="4f6fc9cc-9a3a-42bd-9e47-50ecfbeb090b" TYPE="xfs" /dev/hda1: UUID="6d7abd95-9731-4406-b154-78ee66fc6c7f" TYPE="ext2" /dev/sda: UUID="4f6fc9cc-9a3a-42bd-9e47-50ecfbeb090b" TYPE="xfs" /dev/sdb: UUID="4f6fc9cc-9a3a-42bd-9e47-50ecfbeb090b" TYPE="xfs" |
/dev/hda1 on /boot type ext2 (rw,sync) /dev/md/0 on /vservers type xfs (rw,noatime,usrquota) |
Formatowanie
Obecnie nie formatuje się dysków twardych, moŋna to robiæ jedynie z dyskietkami elastycznymi za pomocą narzędzia fdformat. Robi się to wyģącznie dla uzyskania jakiejķ nietypowej pojemnoķci noķnika, w pozostaģych wypadkach operacja ta jest zbędna, gdyŋ dyskietki podobnie jak dyski twarde są formatowane fabrycznie. Takie formatowanie nazywane jest takŋe tzw. formatowaniem niskopoziomowym.
To co obecnie potocznie okreķla się jako "formatowanie" jest zģoŋeniem dwóch operacji: podziaģu na partycje a następnie utworzeniem systemów plików.
RAID programowy
W systemie Linux istnieje moŋliwoķæ tworzenia na dyskach programowych macierzy RAID poziomów 0, 1, 4, 5, 6, 10, 01. Sģuŋy do tego celu usģuga mdadm. W przeciwieņstwie do macierzy RAID sprzętowych które wymagają specjalnego kontrolera dysków (doķæ drogiego), macierze RAID programowe zakģada się na dyskach podģączonych do zwykģego kontrolera IDE, SATA lub SCSI i caģą obsģugę przekazuje do odpowiedniego oprogramowania (np: mdadm).
Macierze moŋemy zakģadaæ zarówno na caģych dyskach, jak i na odpowiednio przygotowanych partycjach, przy czym zakģadanie na partycjach daje więcej moŋliwoķci konfiguracji. Zarówno korzystając z caģych dysków jak i partycji naleŋy pamiętaæ o tym ŋe najmniejsza partycja lub dysk decyduje o wielkoķci zakģadanej macierzy (miejsce ponad jest tracone), dlatego teŋ naleŋy raczej korzystaæ z takich samych rozmiarów dysków lub partycji.
Poniŋej zamieszczono listę i opis dostępnych rodzajów macierzy dla mdadm, w nawiasach podano nazwy parametrów programu:
RAID 0 (raid0, 0, stripe) - striping czyli poģączenie dwóch dysków (partycji) z przeplotem danych, zwiększa się wydajnoķæ w porównaniu z pojedynczym dyskiem, obniŋa odpornoķæ na awarie dysków - awaria jednego dysku to utrata wszystkich danych.
RAID 1 (raid1, 1, mirror) - kopie lustrzane, dyski są w dwóch jednakowych kopiach, w przypadku awarii jednego drugi przejmuje role pierwszego. Wydajnoķæ tak jak pojedynczy dysk, duŋe bezpieczeņstwo, wadą jest duŋa strata pojemnoķci (n/2 - n-liczba dysków w macierzy)
RAID 4 (raid4, 4) - dane są rozpraszane na kolejnych dyskach a na ostatnim zapisywane są dane parzystoķci, zwiększone bezpieczeņstwo danych przy zachowaniu duŋej pojemnoķci (n-1). Wymaga przynajmniej trzech dysków, wydajnoķæ ograniczona przez dysk parzystoķci
RAID 5 (raid5, 5) - rozpraszane są zarówno dane jak i informacje o parzystoķci na wszystkich dyskach, dzięki czemu wydajnoķæ jest wyŋsza niŋ w RAID 4; pojemnoķæ n-1, wymaga przynajmniej trzech dysków.
RAID 6 (raid6, 6) - jest to rzadko stosowana, rozbudowana macierz typu 5. Jedyną róŋnicą jest dwukrotne zapisanie sum kontrolnych. Dzięki temu macierz moŋe bez utraty danych przetrwaæ awarię dwóch dysków. Wymaga minimum czterech dysków, jej pojemnoķæ to n-2.
Tryb liniowy (linear) - czyli poģączenie dwóch dysków w jeden w ten sposób ŋe koniec pierwszego jest początkiem drugiego, nie zapewnia absolutnie ŋadnego bezpieczeņstwa a wręcz obniŋa odpornoķæ na awarie dysków.
Instalacja
Instalujemy następujące pakiety:
# poldek -i mdadm |
# poldek -i mdadm-initrd |
# poldek -i dmraid |
Planowanie macierzy
Dosyæ popularnym rozwiązaniem jest utworzenie identycznego zestawu partycji na kaŋdym z dysków, a następnie spięcie odpowiednich partycji w macierze. Aby uģatwiæ sobie zadanie moŋemy najpierw podzieliæ jeden z dysków, a na następne urządzenia skopiowaæ ukģad tablicy partycji np.:
# sfdisk -d /dev/sdc | sfdisk /dev/sdd |
Garķæ porad:
Kernel moŋe byæ ģadowany wyģącznie z macierzy RAID 1, jeķli więc będziemy chcieli uŋywaæ np. RAID5 na gģównym systemie plików to musimy umieķciæ gaģąž /boot na osobnej, niewielkiej macierzy RAID1. Opis konfiguracji bootloadera do obsģugi macierzy znajduje się w dalszej częķci artykuģu.
Naleŋy oprzeæ się pokusie umieszczenia obszaru wymiany (swap) na RAID0, gdyŋ awaria jednego z dysków moŋe doprowadziæ do zaģamania systemu.
Urządzenia, z których skģadamy macierz powinny byæ równej wielkoķci, w przeciwnym razie wielkoķæ macierzy będzie wyznaczana przez najmniejszą partycję.
Więcej informacji o podziale na partycje i planowaniu miejsca na dysku zdobędziemy w sekcja Podziaģ na partycje.
Tworzenie macierzy RAID
Przystępujemy do zakģadania macierzy na partycjach za pomocą polecenia mdadm:
mdadm -C {$dev_RAID} --level={$rodzaj} --raid-devices={$iloķæ_urzadzen} {$urzadzenia}
-C, --create- utwórz nową macierz.-l, --level- ustaw poziom RAID np: linear, raid0, 0, stripe, raid1, 1, mirror, raid4, 4, raid5, 5, raid6, 6; Jak moŋemy zauwaŋyæ niektóre opcje są synonimami. Przy opcji Building pierwsze mogą byæ uŋyte: raid0, raid1, raid4, raid5.-n, --raid-devices- liczba aktywnych urządzeņ (dysków) w macierzy-x, --spare-devices- liczba zapasowych (eXtra) urządzeņ w tworzonej macierzy. Zapasowe dyski moŋna dodawaæ i usuwaæ takŋe póžniej.-v --verbose- tryb "gadatliwy"--auto=yes- automatyczne tworzenie urządzeņ w /dev/ przez mdadm (stosowane zwykle przy uŋyciu UDEVa), więcej w Poradach na koņcu rozdziaģu.
Przykģady tworzenia macierzy róŋnego typu:
RAID0 na dwóch partycjach - /dev/sda1 i /dev/sdb1 jako /dev/md0
# mdadm -C -v /dev/md0 --level=0 -n 2 /dev/sda1 /dev/sdb1
RAID1 na dwóch partycjach - /dev/sdc1 i /dev/sdd1 jako /dev/md1
# mdadm -C -v /dev/md1 --level=1 -n 2 /dev/sdc1 /dev/sdd1
RAID5 na 4 partycjach w tym jedna jako zapasowa (hot spare), jeķli nie podasz ile ma byæ zapasowych partycji domyķlnie 1 zostanie zarezerwowana na zapasową
# mdadm -C -v /dev/md2 --level=5 -n 4 --spare-devices=1 \ /dev/sda3 /dev/sdb3 /dev/sdc3 /dev/sdd3
Konfiguracja
Po utworzeniu macierzy postępujemy z nią dalej jak z partycją, czyli zakģadamy system plików i odwoģujemy się do niej np: jako /dev/md0 np.:
# mkfs.xfs /dev/md0 |
Aby macierz byģa automatycznie skģadana przy starcie systemu musimy dodaæ odpowiednie wpisy do pliku /etc/mdadm.conf. Na początek dodajemy wiersz, w którym wymieniamy listę urządzeņ z których budowane są macierze (moŋna uŋywaæ wyraŋeņ regularnych):
DEVICE /dev/sd[abcd][123] |
# mdadm --detail --scan >> /etc/mdadm.conf: |
ARRAY /dev/md0 devices=/dev/sda1,/dev/sdb1 ARRAY /dev/md1 devices=/dev/sdc1,/dev/sdd1 ARRAY /dev/md2 devices=/dev/sda3,/dev/sdb3,/dev/sdc3,/dev/sdd3 |
Macierze (inne niŋ rootfs) są skģadane przez rc-skrypt /etc/rc.d/rc.sysinit, na podstawie powyŋszych wpisów konfiguracyjnych, zatem po restarcie maszyny będziemy juŋ z nich korzystaæ. Jeķli mamy macierz z gģównym systemem plików, to musimy jeszcze przygotowaæ initrd i bootloader (poniŋej).
Przy ręcznym skģadaniu macierzy przydane moŋe byæ polecenie skanujące urządzenia blokowe w poszukiwaniu istniejących macierzy:
# mdadm --examine --scan -v |
Initrd
Jeķli gģówny system plików ma byæ na macierzy to musimy wygenerowaæ obraz initrd z moduģami, które pozwolą na zģoŋenie macierzy. Na początek musimy mieæ zainstalowany pakiet mdadm-initrd. Generowanie takiego initrd przebiega dokģadnie tak samo jak dla zwykģego urządzenia blokowego, musimy się tylko upewniæ, ŋe do obrazu trafiģy dodatkowo moduģy: md-mod, odpowiednio raid0, raid1... i ewentualnie xor. Generowanie obrazu initrd szczegóģowo zostaģo opisane w sekcja Initrd w rozdziaģ Kernel i urządzenia.
Bootloader
Jeķli na raidzie ma się znaležæ gģówny system plików (bez /boot), to konfiguracja jest identyczna jak w przypadku klasycznych urządzeņ blokowych.
Jeķli gaģąž /boot ma się znaležæ na macierzy (wyģącznie RAID1) to powinniķmy zainstalowaæ bootloader na kaŋdym z dysków wchodzących w skģad macierzy, dzięki czemu będziemy mogli uruchomiæ system mimo awarii jednego z dysków. RAID0 i RAID2-5 nie są obsģugiwane przez LILO\GRUB
W LILO w pliku /etc/lilo.conf
naleŋy podaæ odpowiednie
urządzenie dla opcji root i boot:
boot=/dev/md0
raid-extra-boot=mbr-only
image=/boot/vmlinuz
label=pld
root=/dev/md0
initrd=/boot/initrd |
raid-extra-boot wskazuje urządzenia
na których ma zostaæ zainstalowany bootloader (urządzenia wchodzące
w skģad /dev/md0). Po zmodyfikowaniu
konfiguracji musimy zaktualizowaæ bootloader
poleceniem lilo.
Jeķli uŋywamy Grub-a wywoģujemy z powģoki:
# grub grub> |
grub>find /boot/grub/stage1 |
(hd0,0) (hd1,0) Now you want to make sure that grub gets installed into the master boot record of your additional raid drives so that if id0 is gone then the next drive has a mbr loaded with grub ready to go. Systems will automatically go in drive order for both ide and scsi and use the first mbr and active partitions it finds so you can have multiple drives that have mbr's as well as active partitions and it won't affect your system booting at all. So using what was shown with the find above and already knowing that hd0 already has grub in mbr, we then run: Grub>device (hd0)/dev/sda (/dev/hda for ide) Grub>root (hd0,0) Grub>setup (hd0) |
Grub>device (hd1) /dev/sdb (/dev/hdb for ide) Grub>root (hd1,0) Grub>setup (hd1) Grub will then spit out all the commands it runs in the background of setup and will end with a successful embed command and then install command and end with .. succeeded on both of these commands and then Done returning to the grub> prompt. Notice that we made the second drive device 0. Why is that you ask? Because device 0 is going to be the one with mbr on the drive so passing these commands to grub temporarily puts the 2nd mirror drive as 0 and will put a bootable mbr on the drive and when you quit grub you still have the original mbr on sda and will still boot to it till it is missing from the system. You have then just succeeded in installing grub to the mbr of your other mirrored drive and marked the boot partition on it active as well. This will insure that if id0 fails that you can still boot to the os with id0 pulled and not have to have an emergency boot floppy. |
Diagnostyka
Skrócone informacje o macierzy:
# mdadm --query /dev/md0 |
# mdadm --detail /dev/md0 |
# cat /proc/mdstat |
Porady
Mając dwie macierze RAID1 np: /dev/md0 i /dev/md1, moŋemy utworzyæ macierz RAID10 (strip dwóch mirrorów) jako /dev/md2
analogicznie RAID01 tworzymy mając dwie macierze RAID0.# mdadm -C -v /dev/md2 --level=1 -n 2 /dev/md0 /dev/md1
Aby samemu zģoŋyæ macierz (z np: PLD Live CD) wydajemy polecenie, które moŋe wyglądaæ następująco:
# mdadm -A /dev/md0 /dev/hda /dev/hdb
Jeķli macierz jest skģadana w trakcie startu systemu to automatycznie tworzony jest plik urządzenia /dev/mdX. W trakcie tworzenia macierzy, lub gdy macierz nie startuje wraz z systemem, moŋemy skorzystaæ z gotowych urządzeņ w /dev (pakiet dev) lub samemu je utworzyæ (pakiet udev). Udev nie tworzy urządzeņ /dev/md0, więc musimy w tym celu uŋyæ parametru
--auto=yesw wywoģaniach programu mdadm, lub utworzyæ je poleceniem mknod. Urządzeniu nadajemy major o wartoķci 9 i kolejny, niepowtarzalny numer minor. Nie musimy się martwiæ o moduģy, są on ģadowane automatycznie przez mdadm lub initrd. Więcej o UDEV w sekcja Udev - dynamiczna obsģuga sprzętu w rozdziaģ Kernel i urządzenia.Wraz z pakietem mdadm dostarczany jest rc-skrypt uruchamiający mdadm w trybie monitorowania (jako demona). Więcej szczegóģów w dokumentacji programu mdadm.
LVM
LVM (Logical Volume Management) to system zaawansowanego zarządzania przestrzenią dyskową, który jest o wiele bardziej elastyczny, niŋ klasyczne partycje dyskowe. To wiąŋe się z bardziej zģoŋoną konstrukcją, która skģada się z następujących struktur:
PV (physical volumes) - fizyczne woluminy: są bezpoķrednio związane z partycjami dyskowymi (np. /dev/hda1, /dev/sdb3).
VG (volume groups) - grupy woluminów: skģadają się z co najmniej jednego PV, ich wielkoķæ to suma objętoķci wszystkich PV naleŋących do danej grupy. Uzyskane miejsce dyskowe moŋe byæ dowolnie dysponowane pomiędzy kolejne LV.
LV (logical volumes) - woluminy logiczne: są obszarami uŋytecznymi dla systemu (podobnie jak partycje dyskowe). LV są obszarami wydzielonymi z VG, zatem suma wielkoķci woluminów nie moŋe zatem przekraczaæ objętoķci VG, do którego naleŋą.
PV1 PV2
\ /
VG
/ | \
LV1 LV2 LV3 |
Planowanie woluminów
Musimy wyznaczyæ urządzenia blokowe których chcemy uŋyæ do stworzenia struktur PV. Jeķli gģówny system plików ma byæ umieszczony na woluminie logicznym to musimy przeznaczyæ maģą partycję dla gaģęzi /boot, gdyŋ bootloadery lilo i grub nie potrafią czytaæ danych z woluminów. Szczegóģowy opis dzielenia dysków na partycje zamieķciliķmy w sekcja Podziaģ na partycje.
Zaģóŋmy, ŋe mamy dwa dyski twarde po 250GB (/dev/sda i /dev/sdb), których powierzchnię chcemy poģączyæ i rozdysponowaæ pod system operacyjny. Jako, ŋe rootfs takŋe będzie na woluminie to rozplanowanie miejsca moŋe wyglądaæ następująco:
/dev/sda1: maģa partycja na /boot o pojemnoķci 50MB
/dev/sda2: druga partycja dla woluminów (reszta dysku)
/dev/sdb: caģy dysk dla woluminów
swap: 5GB
/ (rootFS): 25GB
/home: 370GB
Instalacja
Omawiamy implementację LVM2, zatem instalujemy pakiet lvm2, jeķli LVM ma byæ uŋyty jako gģówny system plików to potrzebujemy jeszcze pakiet lvm2-initrd do wygenerowania odpowiedniego obrazu initrd.
Budowanie woluminów
Ģadujemy moduģ device mappera:
# modprobe dm-mod |
Dzielimy dysk /dev/sda na dwie opisane powyŋej partycje, a następnie wskazujemy urządzenia Physical Volumes:
# pvcreate /dev/sda2 /dev/sdb |
# vgcreate vgsys /dev/sda2 /dev/sdb |
# lvcreate -L 5GB -n swap vgsys # lvcreate -L 25GB -n rootfs vgsys # lvcreate -L 370GB -n home vgsys |
# mkswap /dev/vgsys/swap # mkfs.xfs /dev/vgsys/rootfs # mkfs.xfs /dev/vgsys/home |
# mkfs.ext2 /dev/sda1 |
Konfiguracja startowa
Woluminy są automatycznie aktywowane przez rc-skrypt /etc/rc.d/rc.sysinit lub initrd. Moduģ device mappera równieŋ jest ģadowany automatycznie. Jeķli chcemy umieķciæ gģówny system plików na LV, to musimy jeszcze wygenerowaæ nowy obraz initrd, z obsģugą LVM. Zostaģo to szczegóģowo przedstawione w sekcja Initrd w rozdziaģ Kernel i urządzenia. W konfiguracji bootloadera ustawiamy opcję 'root=' na /dev/vgsys/rootfs. Teraz instalujemy system, instalujemy bootloader i moŋemy zrestartowaæ maszynę.
Gdy zajdzie potrzeba "ręcznego" aktywowania woluminów (np. spod RescueCD), to na początek musimy się upewniæ, ŋe jest zaģadowany moduģ dm-mod. Kernel nie zgģasza komunikatów o odnalezieniu woluminów, tak jak ma to miejsce z partycjami, naleŋy je odszukaæ za pomocą odpowiednich narzędzi: lvmdiskscan i lvscan. Jeķli odnaležliķmy ŋądane struktury, to moŋemy je aktywowaæ:
# vgchange -a y |
Narzędzia diagnostyczne
Skrócone informacje o kaŋdym z rodzaju komponentów (PV/VG/LV) wyķwietlimy za pomocą programów pvs, vgs, lvs. Więcej informacji uzyskamy za pomocą programów: pvdisplay, vgdisplay, lvdisplay.
Do niektórych operacji z woluminami będziemy musieli je odmontowaæ i deaktywowaæ. Aby deaktywowaæ wszystkie woluminy uŋyjemy polecenia
# vgchange -a n |
# vgchange -a y |
Zarządzanie: powiększanie woluminu
Teraz przedstawimy potęgę LVM-a: pokaŋemy jak powiększyæ wolumin, gdy dochodzimy do wniosku, ŋe przeznaczonego miejsca jest za maģo. Zaģóŋmy, ŋe mamy woluminy utworzone zgodnie z wczeķniejszymi przykģadami i chcemy przeznaczyæ caģą dostępną wolną przestrzeņ na naszym VG (100GB) dla /dev/vgsys/homes:
# lvextend -l 100%VG /dev/vgsys/home |
# xfs_growfs /home |
Porady
Woluminy LVM powodują zwiększone ryzyko uszkodzenia danych, gdyŋ awaria jednego dysku moŋe spowodowaæ utratę wszystkich danych. Z tego powodu zaleca się tworzenie woluminów na macierzach RAID.
Naprawa
Awarie dysków często są bolesne, a nierzadko dosyæ kosztowne. Istnieje wiele narzędzi do odzyskiwania danych, jednak nigdy nie gwarantują sukcesu. Dlatego warto dokonywaæ regularnie kopie zapasowe danych.
Uszkodzenia fizyczne
Uszkodzenia fizyczne sprawdzamy programem badblocks z pakietu e2fsprogs, uruchamiamy go poleceniem:
# badblocks -s /dev/sda |
Naprawa systemu plików
Nazwy programów, podobnie jak programy do tworzenia systemów plików, są ujednolicone (poza XFS). Zaczynają się od "fsck.":
fsck.ext2 fsck.reiserfs fsck.vfat fsck.jfs |
# xfs_repair /dev/sda2 |
Programy te nie pozwolą na sprawdzanie na systemie plików podmontowanym w trybie do odczytu i zapisu. Powinniķmy w ogóle nie montowaæ takiego systemu plików, a przynajmniej podmontowaæ w trybie tylko do odczytu.
Nieco bardziej zģoŋone jest sprawdzanie gģównego systemu plików jeķli uruchomiliķmy system w trybie jednego uŋytkownika. Problemem jest koniecznoķæ przemontowania systemu plików w tryb ro. Niektóre programy mogą sprawdzaæ w pliku /etc/mtab czy system plików jest w trybie tylko do odczytu. Moŋe to daæ nieprawidģowe wyniki, gdyŋ zazwyczaj gaģąž /etc leŋy na gģównym systemie plików i w pliku tym nie nastąpią ŋadne zmiany po takim przemontowaniu. Moŋna to obejķæ wczeķniej modyfikując wpis w /etc/mtab, kiedy juŋ to zrobimy wykonujemy polecenie:
# mount / -o ro,remount |
Naprawienie systemu plików nie gwarantuje, ŋe nie zostaģy uszkodzone ŋadne pliki. Jeķli na naprawianym systemie plików byģy jakieķ dane systemowe, to powinniķmy wykonaæ kontrolę ich integralnoķci, opisaną dokģadnie w sekcja Zaawansowane operacje w rozdziaģ Zarządzanie pakietami.
Administracja
W tym rozdziale znajdziesz informacje dotyczące administracji systemem PLD
Ratowanie systemu
Wstęp
W tym rozdziale pokaŋemy co moŋna zrobiæ w wypadku, jeķli nastąpiģa awaria systemu, uniemoŋliwiająca normalne uruchomienie. Musimy uzyskaæ dostęp do urządzeņ lub plików na dysku twardym, moŋemy w tym celu spróbowaæ uruchomiæ system na niskim poziomie pracy, a jeķli to się nie powiedzie, to uŋyæ operacji chroota z innego systemu np. dystrybucji typu live.
Uruchomienie na niskim poziomie pracy
Moŋemy uruchomiæ system z pominięciem wielu czynnoķci wykonywanych przez skrypty startowe. Operacja polega na przekazaniu do kernela odpowiednich parametrów, które wymuszą uŋycie przez proces init specjalnie przygotowanego zestawu rc-skryptów.
Interesuje nas poziom 1 lub single (tryb jednego uŋytkownika), tak teŋ nazywają się parametry, które musimy przekazaæ do kernela. Parametry przekazujemy do jądra za poķrednictwem bootloadera, w trakcie uruchomienia systemu np.:
grub append> root=/dev/sda2 single |
Uruchomienie RescueCD
Jako dystrybucję Live najlepiej wybraæ RescueCD lub PLD Live. Oba projekty są dobrze przygotowane do pracy z naszą dystrybucją, gdyŋ zawierają program rpm i poldek.
Na początek musimy zadbaæ o to, aby system mógģ się uruchomiæ z pģyty CD, uzyskamy to modyfikując odpowiednią opcję BIOS-u komputera. Teraz uruchamiamy komputer z RescueCD umieszczonym w napędzie CD-ROM i czekamy aŋ system się uruchomi.
Aby dokonaæ napraw musi zostaæ zaģadowany moduģ kontrolera masowego. Większoķæ wspóģczesnych dystrybucji typu live sama wykrywa sprzęt, jeķli jednak to się nie powiedzie lub uŋywamy starej wersji RescueCD to musimy sami zaģadowaæ moduģ. Jeķli potrzebujemy obsģuŋyæ kontroler typu IDE musimy zaģadowaæ moduģ ide-disk
# modprobe ide-disk |
# mdadm -A --auto=yes /dev/md0 /dev/hda /dev/hdb |
Teraz kiedy mamy zaģadowane odpowiednie moduģy i dostęp do plików urządzeņ (w katalogu /dev) moŋemy wykonaæ liczne operacje diagnostyczne i naprawcze (opisane dalej).
Naprawa systemu plików
Do naprawy systemu plików konieczny jest tylko dostęp do plików urządzeņ z katalogu /dev. Aby sprawdziæ i naprawiæ system plików XFS wydajemy polecenie:
# xfs_repair /dev/sda2 |
Naprawa konfiguracji
W przypadku podniesienia systemu w trybie single mamy swobodny dostęp do plików konfiguracji, w przeciwnym wypadku musimy najpierw podmontowaæ odpowiednią partycję aby uzyskaæ dostęp do plików. W tym celu tworzymy nowy katalog, a następnie montujemy do niego wģaķciwe urządzenie np.:
# mkdir -p /mnt/rootfs # mount /dev/hda3 /mnt/rootfs |
# mount /dev/hda1 /mnt/rootfs/boot |
Operacja chroota
Jeķli uruchomiliķmy system z RescueCD i mamy podmontowane systemy plików to wielu wypadkach wygodniejsze, a czasami nawet konieczne będzie wykonanie tzw. chroot-a.. Polega to na podmianie gģównego systemu plików uŋywanego przez dany program na gģówny system plików ratowanego systemu operacyjnego. Będzie to konieczne przy problemach z jądrem, bootloaderem czy initrd. Aby wykonaæ tą operację naleŋy wykonaæ komendę:
# chroot /mnt/rootfs |
To polecenie uruchomi powģokę /bin/sh w taki sposób, ŋe wszystkie dziaģania z jej poziomu będą odbywaģy się przežroczyķcie na podmontowanym systemie plików. Zanim jednak zabierzemy się do pracy proszę o zapoznanie się z uwagami na koņcu rozdziaģu. Jeķli uŋywamy powģoki korzystającej z chroot-a, wystarczy ŋe zakoņczymy jej pracę wydając polecenie exit lub skrótem klawiszowym ctrl+d. Na koniec odmontowujemy systemy plików jeķli takie są i restartujemy komputer.
Uwagi
Niektóre operacje w ķrodowisku chroot wymagają (np. tworzenie initrd) podmontowania pseudo systemu plików /proc:
# mount /proc /mnt/rootfs/proc -o bind
Uŋytkownicy udeva powinni pamiętaæ, ŋe wiele operacji w podmontowanym ķrodowisku wymagają istnienia kompletu plików urządzeņ:
Udev dokģadniej opisano w sekcja Udev - dynamiczna obsģuga sprzętu w rozdziaģ Kernel i urządzenia.# mount /dev /mnt/rootfs/dev -o bind
Moŋe się zdarzyæ, ŋe poldek się nie uruchamia w chroocie. Sposobem na obejķcie tego jest uruchomienie go z flagą -r , np:
# poldek -r /mnt/rootfs
Duŋą zaletą RescueCD jest to, ŋe automatycznie "podnosi" interfejs sieciowy z obsģugą DHCP oraz serwer SSH. Pozwala to na zdalną naprawę, wystarczy, ŋe ktoķ umieķci pģytę z dystrybucją w napędzie i uruchomi komputer. My zalogujemy się na odpowiedni adres za poķrednictwem SSH; login: root, hasģo: pld.
Zarządzanie podsystemami i usģugami
W systemie dostępne są specjalne skrypty, napisane w języku powģoki, zwane "skryptami startowymi" lub "rc-skryptami". W PLD zastosowano skrypty startowe typu System-V, dzięki temu praca administratora jest znacząco zautomatyzowana.
Za pomocą rc-skryptów pomocą moŋemy uruchamiaæ lub zatrzymywaæ podsystemy i usģugi, kontrolowaæ ich dziaģanie oraz wiele innych. Moŋna je podzieliæ na dwie zasadnicze grupy:
Skrypty podsystemów - specjalnych zadaņ mających za zadanie dokonaæ konfiguracji systemu operacyjnego. Do tego typu zadaņ naleŋą: konfigurowanie sieci, ģadowanie moduģów, prace porządkowe i wiele innych. Te skrypty są integralną częķcią systemu (pakiet rc-scripts) i zapewne są juŋ u nas zainstalowane.
Skrypty zarządzania usģugami - zarządzają programami dziaģające w tle (demonami) np.: serwerem WWW, serwerem NFS. Skrypty te są instalowane automatycznie razem z pakietami usģug. Wyjątek stanowią usģugi z wydzielonymi w tym celu pakietami, rozpoznamy je po nazwie *-init i *-standalone. Więcej o nazewnictwie pakietów przedstawiono w sekcja Cechy pakietów w PLD w rozdziaģ Zarządzanie pakietami.
Budowa systemu rc-skryptów
Katalog /etc/rc.d przechowuje konfigurację uruchamiania usģug i podsystemów, poniŋej pokrótce omówiono skģadniki systemu rc-skryptów:
/etc/rc.d/init.d - katalog z skryptami startowymi usģug
/etc/rc.d/rc{$NR}.d - katalogi tak oznaczone zawierają ģącza symboliczne do skryptów zawartych w katalogu init.d. Wartoķæ {$NR} jest liczbą wskazującą poziom pracy (run level), dla którego uruchamiana jest zawartoķæ danego katalogu.
/etc/rc.d/rc - skrypt uruchamiający i zatrzymujący usģugi
/etc/rc.d/rc.init - skrypt ustawiający opcje narodowe (język, waluta) pobiera konfigurację z pliku /etc/sysconfig/i18n
/etc/rc.d/rc.local - uruchamiany na samym koņcu wszystkich skryptów, uŋytkownicy mogą dodawaæ tu swoje wpisy jeķli nie chcą uŋywaæ init.d i rc{$NR}.d
/etc/rc.d/rc.serial - konfiguracja portów szeregowych
rc.sysinit - gģówny skrypt startowy uruchamiany jednokrotnie (w trakcie startu)
/etc/rc.d/rc.modules - zaģadowanie moduģów z /etc/modules
/etc/rc.d/rc.shutdown - gģówny skrypt uruchamiany przy zatrzymaniu systemu lub restarcie.
/etc/profile - plik startowy przy pomocy którego są ustawiane gģównie zmienne systemowe
Zarzadzanie podsystememi/usģugami
Usģugami/podsystemami zarządzamy ręcznie, wykonujemy to za pomocą uruchomienia odpowiedniego skryptu z katalogu /etc/rc.d/init.d/. Dodatkowo podajemy odpowiednim parametr okreķlający akcję, którą skrypt ma wykonaæ. Uruchomienie bez parametru podaje listę moŋliwych dla niego akcji, dla przykģadu wyķwietlimy listę dostępnych parametrów podsystemu sieci:
# /etc/rc.d/init.d/network
Usage: /etc/rc.d/init.d/network {start|stop|restart|status} |
Poniŋej przedstawiono wyģączenie obsģugi sieci, oraz ponowne jej uruchomienie. W ten sposób zmusza się usģugę lub podsystem do ponownego odczytania swojej konfiguracji. W tym wypadku nastąpi skonfigurowanie na nowo interfejsów, zaktualizowanie ustawieņ, tablic routingu itd...
# /etc/rc.d/init.d/network stop Shutting down interface eth0.......................................[ DONE ] Shutting down interface eth1.......................................[ DONE ] # /etc/rc.d/init.d/network start Setting network parameters.........................................[ DONE ] Bringing up interface eth0.........................................[ DONE ] Bringing up interface eth1.........................................[ DONE ] |
Lista dostępnych parametrów będzie się zmieniaæ w zaleŋnoķci od usģugi, w poniŋszej tabeli przedstawiono znacznie tych najczęķciej spotykanych:
Tabela 1. Popularne akcje skryptów startowych
| Parametr | Akcja |
|---|---|
| start | Uruchamia podsystem/usģugę |
| stop | Zatrzymuje podsystem/usģugę |
| reload, force-reload | Przeģadowanie usģugi poprzez wysģanie sygnaģu (zwykle HUP) do demona, często oba podane parametry mają takie same dziaģanie. Operacja uŋywana do ponownego odczytania konfiguracji demona. |
| restart | Peģny restart usģugi (zazwyczaj jest to kolejne wywoģanie skryptu z parametrem start i stop). Operacja uŋywana do ponownego odczytania konfiguracji demona. |
| status | Wyķwietla stan podsystemu/usģugi, dzięki temu moŋemy ģatwo okreķliæ czy czy jest uruchomiony. W niektórych wypadkach podawane są dodatkowe informacje. |
Niektóre usģugi posiadają inne, uŋyteczne tylko dla nich parametry. Przykģadem moŋe byæ argument init, który zazwyczaj musi byæ uŋyty przed pierwszym uruchomieniem usģugi.
Nieco wygodniej zarządza się skryptami przy pomocy programu service. Aby wykonaæ za jego pomocą taki sam efekt jak powyŋej musimy go wywoģaæ z dwoma parametrami, pierwszy to nazwa skryptu, drugi zaķ to wybrana akcja:
# service network stop # service network start |
Domyķlnie po zainstalowaniu nowego podsystemu lub usģugi, dodawane są potrzebne skrypty startowe. Dzięki temu nowo zainstalowane oprogramowanie uruchamia się automatycznie w trakcie startu systemu lub przy zmianie poziomu pracy. Aby uruchomiæ dopiero co zainstalowany podsystem lub usģugę musimy wykonaæ to "ręcznie".
Zarządzanie skryptami startowymi w trakcie instalacji/aktualizacji pakietów opisano w sekcja Cechy pakietów w PLD w rozdziaģ Zarządzanie pakietami
Jeķli zechcemy utworzyæ wģasny rc-skrypt to z pomocą przyjdzie nam szablon z pliku /usr/share/doc/rc-scripts{$wersja}/template.init.gz
Konfiguracja rc-skryptów
Skryptów startowych typu System-V nie konfigurujemy bezpoķrednio, w PLD sģuŋy ku temu zestaw plików konfiguracyjnych umieszczony w katalogu /etc/sysconfig. Znajdziemy w nim zarówno pliki konfiguracji systemu jak i konfiguracji zainstalowanych usģug.
Większoķæ tych plików jest bezpoķrednio zaģączana do kodu rc-skryptów, zatem ich skģadnia musi odpowiadaæ skģadni powģoki wskazanej w skrypcie (w PLD jest to /bin/sh). Dotyczy to takŋe plików konfiguracji interfejsów sieciowych w katalogu /etc/sysconfig/interfaces. W plikach tych występują jedynie konstrukcje przypisania zamiennych oraz ewentualne komentarze. Moŋemy co prawda umieszczaæ tam dowolne komendy wiersza poleceņ, jednak naleŋy byæ przy tym niezwykle ostroŋnym i robiæ to tylko w uzasadnionych przypadkach. Jest jednak kilka plików konfiguracji, które są traktowane inaczej - mają wģasną skģadnię, przykģadem tego rozwiązania są np. pliki /etc/sysconfig/static-*, nimi jednak nie będziemy się zajmowaæ w tym rozdziale.
Opcje w plikach konfiguracji moŋna podzieliæ na dwie grupy: ogólnego stosowania i specyficzne dla rc-skryptu. Pierwsza z nich to uniwersalne opcje, z którymi moŋemy się zetknąæ w wielu w innych plikach konfiguracji np.:
SERVICE_RUN_NICE_LEVEL - priorytet procesów usģugi (liczba nice)
RPM_SKIP_AUTO_RESTART - mówi programowi rpm czy usģuga ma byæ automatycznie restartowana po aktualizacji, więcej o tej opcji w sekcja Cechy pakietów w PLD w rozdziaģ Zarządzanie pakietami
Zaleŋnoķci
Pomiędzy niektórymi demonami i podsystemami istnieją ķcisģe powiązania, jako przykģad moŋna wymieniæ usģugi sieciowe i podsystem sieci. Usģuga jest zaleŋna od dziaģania sieci i próba wyģączenia najpierw tej drugiej moŋe niekiedy zaowocowaæ problemami, gdyŋ PLD nie dba o to za nas. Musimy samemu się zatroszczyæ o wyģączanie usģug we wģaķciwej kolejnoķci.
Pewną wskazówką będą numery przy nazwach ģączy symbolicznych w katalogach /etc/rc.d/rc{$nr}.d (przy literze S). Numery te okreķlają kolejnoķæ ģadowania usģug w trakcie startu systemu.
Usģugi a poziomy pracy
W PLD zastosowano klasyczny, oparty na rc-skryptach typu System-V system poziomów pracy. Poziomami na których pracują usģugi moŋna zarządzaæ ręcznie, jest to jednak niezalecany sposób, lepszym pomysģem jest uŋycie programu chkconfig. Aby wyķwietliæ listę usģug uruchamianych przy w danych poziomach pracy wydajemy polecenie:
# chkconfig --list crond 0:wyģ. 1:wyģ. 2:wģ. 3:wģ. 4:wģ. 5:wģ. 6:wyģ. cups 0:wyģ. 1:wyģ. 2:wģ. 3:wģ. 4:wģ. 5:wģ. 6:wyģ. sshd 0:wyģ. 1:wyģ. 2:wyģ. 3:wģ. 4:wģ. 5:wģ. 6:wyģ. gdm 0:wyģ. 1:wyģ. 2:wyģ. 3:wyģ. 4:wyģ. 5:wģ. 6:wyģ. network 0:wyģ. 1:wyģ. 2:wģ. 3:wģ. 4:wģ. 5:wģ. 6:wyģ. sshd 0:nie 1:nie 2:nie 3:nie 4:tak 5:nie 6:nie |
W PLD najczęķciej korzysta się z trybów 3 i 5 rzadziej z: 1, 2 i 4, nigdy nie ustawiamy trybu 0 (restart) i 6 (wyģączenie). Na powyŋszym przykģadzie podsystem network jest uruchamiana dla poziomów: 2,3,4,5, zaķ gdm tylko dla trybu 5. Aby wģączyæ/wyģączyæ uruchamianie jakiejķ usģugi wywoģujemy program następująco: chkconfig {$usģuga} on/off. Wyģączenie usģugi sshd (domyķlnie jest wģączona):
# chkconfig sshd off |
# chkconfig sshd on |
$ grep chkconfig /etc/init.d/sshd # chkconfig: 345 55 45 |
# chkconfig --level 5 sshd off |
Dodawanie lub usuwanie usģug w poziomach pracy nie powoduje ich uruchomienia lub zatrzymywania, aby to zrobiæ musimy wykonaæ to ręcznie lub zmieniæ tryb pracy. Poziomy pracy zostaģy szerzej omówione w sekcja Zmiana poziomu pracy systemu.
Zmiana poziomu pracy systemu
PLD jest systemem uniksowym, a więc obsģuguje tzw. poziomy pracy (ang. run levels). Poziom pracy jest to specjalna konfiguracja systemu, która pozwala zaistnieæ tylko wytypowanym usģugom bądž podsystemom. Mamy sporo swobody w wyborze usģug pracujących bądž wyģączonych w danym poziomie pracy, opis jak nimi zarządzaæ znajdziemy w sekcja Zarządzanie podsystemami i usģugami.
Tabela 2. Dostępne poziomy pracy
| Poziom | Opis |
|---|---|
| 1 | Konfiguracja z minimalną iloķcią uruchamianych podsystemów. Nie ma obsģugi sieci i nie zezwala na logowanie się innym uŋytkownikom. |
| 2 | Rzadko uŋywany tryb wielu uŋytkowników. Uruchamiana jest obsģuga sieci i większoķci usģug oprócz NFS. |
| 3 | Popularny tryb prac z dostępem wielu uŋytkowników i uruchomieniem wszystkich usģug. Jest to typowy tryb dla maszyn obsģugiwanych z konsoli tekstowej - np.: serwerów. |
| 4 | Rzadko uŋywany tryb wielu uŋytkowników. - praca w konsoli tekstowej |
| 5 | Typowy tryb z dostępem wielu uŋytkowników uruchamiający system X-Window (uruchamia demon GDM lub KDM). Poziom uŋywany na stacjach roboczych z GUI. Więcej o sposobach uruchamiania X-Window w sekcja X-Server w rozdziaģ X-Window. |
| single | Tryb jednego uŋytkownika (ang. Single user mode) - uŋywany przez administratorów w sytuacjach awaryjnych. Uruchamia mniej skryptów startowych niŋ pierwszy poziom. Jego wģączanie ma sens tylko przez przekazanie do jądra parametru single z poziomu bootloadera. |
Są jeszcze dwa tryby: tryb 0 i 6. Pierwszy jest uŋywany w celu zatrzymania wszystkich usģug i podsystemów przed zamknięciem systemu, drugi zaķ przed ponownym uruchomieniem systemu. Z poķród wymienionych poziomów pracy najczęķciej uŋywa się poziomu 3 lub 5.
Poziomem pracy zarządza proces init. W celu okreķlenia domyķlnego poziomu pracy, init odczytuje swój plik konfiguracji (/etc/inittab) podczas uruchomienia systemu. Po uruchomieniu administrator moŋe wymusiæ zmianę poziomu za poķrednictwem programu telinit (link symboliczny do programu init). Naleŋy pamiętaæ o tym, ŋe telinit nie dokonuje zmian w pliku /etc/inittab, tak więc przy ponownym uruchomieniu systemu wybrany zostanie ustawiony w nim poziom pracy. Więcej informacji o pliku /etc/inittab znajdziemy w sekcja Kluczowe pliki w rozdziaģ Konfiguracja systemu.
Za domyķlny poziom pracy odpowiada opcja "initdefault", moŋe ona przyjąæ wartoķæ od 1 do 5 np.:
id:3:initdefault: |
Powyŋszy przykģad wģączy system na trzecim poziomie pracy, jest domyķlna wartoķæ w PLD.
W wyniku zmiany poziomu zostaną zatrzymane wszystkie wszystkie podsystemy wyģączone z pracy na tym poziomie, zaķ te które mają dziaģaæ zostaną uruchomione. Przykģadowo jeķli chcemy przejķæ do trybu 2 uŋyjemy polecenia:
# telinit 2 |
Jeķli system do tej pory pracowaģ w trybie 3 to wyģączona zostanie usģuga NFS.
Moŋemy równieŋ okreķliæ poziom uruchomienia przed startem systemu, dokonujemy tego za pomocą parametrów przekazywanych za poķrednictwem bootloadera. Więcej szczegóģów na ten temat znajdziemy w sekcja Wstęp w rozdziaģ Bootloader.
Konta uŋytkowników
W PLD zastosowano klasyczny dla systemów uniksowych system kont uŋytkowników, tak więc istnieje podziaģ na dwa rodzaje kont: konta systemowe i konta uŋytkowników. Zarządzanie kontami systemowymi następuje automatycznie w trakcie instalowania bądŋ usuwania programów, które ich wymagają. Z tego powodu nie musimy się nimi zajmowaæ, zajmiemy się więc tylko kontami zwykģych uŋytkowników.
W PLD domyķlnie instalowanym pakietem do zarządzania kontami jest pakiet shadow. Moŋemy do jednak zastąpiæ zbiorem pwdutils, który zawiera narzędzia o większych moŋliwoķciach. Dzięki nim nie będzie juŋ koniecznoķci "ręcznego" edytowania plików systemowych, z tego względu opisane zostaną wyģączne narzędzia pwdutils.
Dodanie
Konto uŋytkownika dodajemy poleceniem useradd -m {$nazwa_uŋytkownika} np.:
# useradd -m jkowalski |
GROUP - identyfikator grupy gģównej - domyķlnie: 1000 (users)
HOME - miejsce przechowywania katalogów domowych - domyķlnie: /home/users
SHELL - powģoka - domyķlnie: /bin/bash
Drugi okreķla bardziej zaawansowane opcje, najwaŋniejsze z nich to:
PASS_MAX_DAYS - liczba dni do wygaķnięcia hasģa -domyķlnie: 99999
PASS_MIN_DAYS - minimalna liczba dni do między zmianami hasģa -domyķlnie: 0
PASS_WARN_AGE - iloķæ dni przez które będzie pokazywane ostrzeŋenie o wygaķnięciu hasģa - domyķlnie: 7
Wiele opcji kont zawartych w tych plikach moŋna ģatwo modyfikowaæ, poprzez przekazanie odpowiednich parametrów do programu useradd oraz passwd, więcej informacji na ten temat uzyskamy w podręczniku systemowym. Jeķli chcemy utworzyæ większa iloķæ kont o zmodyfikowanych parametrach to wygodniejsze będzie ustawienie interesujących nas wartoķci w podanych powyŋej plikach.
Jeķli uŋytkownik ma konto na wielu maszynach dobrym zwyczajem jest nadawanie takiego samego numeru uŋytkownika (UID) dla kaŋdego z kont. W przypadku programu useradd naleŋy uŋyæ opcji "-u".
Na koniec administrator musi ustawiæ hasģo dla danego uŋytkownika.
Usunięcie
Aby usunąæ konto uŋyjemy programu userdel:
# userdel jkowalski |
Ze względów bezpieczeņstwa moŋna poleciæ blokowanie kont uŋytkowników w miejsce ich usuwania, w ten sposób moŋemy się ochroniæ przed sytuacją powrotu do uŋytku numeru UID usuniętego uŋytkownika.
Modyfikacja
Dane uŋytkownika modyfikujemy poleceniem usermod, dokģadny opis tego programu znajdziemy w manualu.
Hasģo
Pierwsze hasģo dla uŋytkownika jest nadawane przez administratora, kaŋdą następną jego modyfikację uŋytkownik moŋe wykonywaæ samodzielnie.
Ustawienie hasģa przez administratora: passwd {$nazwa_uŋytkownika}
# passwd jkowalski Changing password for jkowalski. New UNIX password: Retype new UNIX password: |
# passwd -e jkowalski |
Zarządzanie kontami
Hasģo blokujemy poleceniem: passwd -l {$nazwa_uŋytkownika} np.:
# passwd -l jkowalski |
# passwd -u jkowalski |
# usermod -s /bin/false jkowalski |
Grupy
W PLD zastosowano klasyczny dla systemów uniksowych system grup, tak więc istnieje podziaģ na dwa rodzaje grup: grupy systemowe i grupy uŋytkowników. Grupy te rozróŋniamy na podstawie identyfikatorów grupowych (GID), dla grup uŋytkowników przeznaczone są wartoķci 1000 i więcej. Ponadto grupy systemowe często przyjmują nazwy podobne jak nazwy usģug np: ftp, named, itp.
Zarządzanie grupami systemowymi następuje automatycznie w trakcie instalowania bądž usuwania pakietów, z tego powodu nie naleŋy w nie ingerowaæ. W naszej dystrybucji zarządzanie grupami zazwyczaj sprowadza się do dodawania/usuwania wģasnych grup oraz zarządzania uczestnictwem w istniejących grupach.
W PLD domyķlnie instalowanym pakietem do zarządzania grupami jest pakiet shadow. Moŋemy do jednak zastąpiæ zbiorem pwdutils, który zawiera narzędzia o większych moŋliwoķciach. Dzięki nim nie będzie juŋ koniecznoķci "ręcznego" edytowania plików systemowych, z tego względu opisane zostaną wyģączne narzędzia pwdutils.
Dodanie grupy
Uŋywamy polecenia groupadd {$nazwa_grupy} np.:
# groupadd kadry |
Jeķli tworzymy takie same grupy na wielu maszynach, to dobrym zwyczajem jest nadawanie takiego samego numeru grupy (GID) dla kaŋdej z grup. Dowolny GID narzucamy w trakcie tworzenia grupy programem groupadd z uŋyciem opcji "-g".
Zapisanie do grup
Dzięki poleceniu id {$nazwa_uŋytkownika} sprawdzimy do jakich grup zapisany jest uŋytkownik, jeķli nie podamy nazwy konta to zostanie wyķwietlona informacja o aktualnie uŋywanym koncie np.
$id jkowalski uid=500(jkowalski) gid=1000(users) grupy=1000(users),10(wheel),19(floppy),23(audio) |
Zapisanie do grupy następuje po wykonaniu polecenia groupmod -A {$konto_uŋytkownika} {$grupa} np.
groupmod -A jkowalski kadry |
Aby wyrejestrowaæ uŋytkownika z grupy musimy uŋyæ parametru "-R" np.
groupmod -R jkowalski kadry |
Uwagi
Po kaŋdej modyfikacji uczestnictwa w grupach, uŋytkownik musi się ponownie zalogowaæ, aby wprowadzone zmiany zaczęģy obowiązywaæ.
Zapisanie uŋytkownika do grupy sģuŋy podniesieniu jego uprawnieņ, listę przywilejów jakie uzyska zamieszczono w sekcja Zarządzanie uprawnieniami.
Zarządzanie uprawnieniami
W PLD zastosowano restrykcyjny poziom bezpieczeņstwa, zwykģy uŋytkownik domyķlnie ma minimalne moŋliwe uprawnienia. Aby je zwiększyæ administrator musi zapisaæ uŋytkownika do odpowiednich grup, poniŋej zostaģa przedstawiona skrócona ich lista i odpowiadające im "przywileje" lub funkcje.
Tabela 3.
| GID | Nazwa | Wģaķciciel/Uprawnienia |
|---|---|---|
| 0 | root | grupa administracyjna - wysokie uprawnienia w caģym systemie |
| 3 | sys | odczyt niektórych plików systemowych np. konfiguracji i logów systemu druku CUPS |
| 4 | adm | moŋliwoķæ korzystania z narzędzi takich jak: tarcerouote, ping, arping, clockdiff |
| 6 | disk | bezpoķredni dostęp do urządzeņ masowych np. naprawy i tworzenie systemów plików, odtwarzanie i nagrywanie CD |
| 7 | lp | dostęp do portu drukarki: równolegģego, USB |
| 9 | kmem | odczyt z urządzeņ /dev/mem, /dev/kmem |
| 10 | wheel | moŋliwoķæ korzystania z programu su |
| 17 | proc | dostęp do pseudosystemu plików /proc (np. wgląd do procesów innych uŋytkowników) |
| 19 | floppy | moŋliwoķæ niskopoziomowego formatowania dyskietek i tworzenia na nich systemu plików |
| 22 | utmp | zapis do plików /var/run/utmpx, /var/log/wtmp, /var/log/lastlog |
| 23 | audio | dostęp do karty džwiękowej |
| 27 | cdwrite | dostęp do narzędzi nagrywania pģyt CD |
| 28 | fsctrl | grupa której moŋna uŋywaæ do nadawania praw dla plików na montowanych urządzeniach |
| 50 | ftp | grupa systemowa serwera FTP: odczyt plików konfiguracji |
| 51 | http | grupa systemowa serwera WWW |
| 117 | crontab | odczytywanie konfiguracji demona CRON |
| 123 | stats | grupa uŋywana do potrzeb automatycznie generowanych statystyk (mrtg, calamaris, itd.) |
| 124 | logs | grupa odczytu niektórych logów |
| 138 | fileshare | moŋliwoķæ udostępniania zasobów NFS i SMB (zapis do /etc/exports, /etc/samba/smb.conf) |
| 1000 | users | domyķlna grupa gģówna dla zwykģych uŋytkowników |
Duŋo więcej informacji o grupach i uŋytkownikach znajdziemy w dokumencie uid_gid.db.txt trzymanym w CVS-ie. Zapisywanie do grup opisano w sekcja Grupy.
Bezpieczeņstwo
Bezpieczeņstwo systemów i danych to rozlegģy temat dlatego gģównie skupimy się na aspektach dotyczących PLD.
Dostępne narzędzia
PLD jako dystrybucja "robiona przez administratorów dla administratorów" ma duŋe zasoby programów uŋytecznych w zakresie bezpieczeņstwa, poczynając od NetCata (nc), a na wiresharku i nessusie koņcząc.
Dostęp do konta root
Nasza polityka bezpieczeņstwa wymaga, aby uŋytkownik naleŋaģ do grupy wheel, jeķli chce zwiększyæ swoje uprawnienia za pomocą su i sudo. W ten sposób atakujący musi zgadnąæ trzy parametry zamiast jednego (nazwa uŋytkownika, hasģo i hasģo administratora zamiast samego hasģa administratora). Nie ma teŋ moŋliwoķci zdalnego zalogowania się bezpoķrednio na konto roota (z tych samych powodów). Dodatkowo root nie moŋe zdalnie uŋywaæ innych usģug (ftp, imap, pop3, smtp) m.in z powodu niedostatecznie silnego szyfrowania transmisji.
SUID
Domyķlnie zwykli uŋytkownicy nie mają prawa wykonania programów z ustawionym bitem SUID. Aby takie prawo uzyskaæ muszą byæ zapisani do odpowiedniej grupy. Przykģadowo program ping wymaga zapisania do grupy adm. Poglądowe zestawienie grup zamieķciliķmy w sekcja Zarządzanie uprawnieniami.
/proc
Domyķlnie uŋytkownicy nie widzą ŋadnych procesów poza swoimi. Jest to nie tylko krok w stronę bezpieczeņstwa, ale i w wygody, uŋytkownik nie gģowi się nad dģugimi listami procesów generowanych przez program top czy ps. Podobnie jak z programami z bitem SUID jest to oparte o grupy, aby uŋytkownik widziaģ wszystkie procesy naleŋy go zapisaæ do grupy /proc.
chroot i vserver
PLD oferuje system sys-chroot, wbudowany w rc-skrypty, sģuŋący do wygodnego zarządzania ķrodowiskami typu chroot. Usģugi, które wspierają natywnie chrooty (np. Bind) dziaģają w izolowanym ķrodowisku od razu po instalacji.
PLD wspiera takŋe mechanizm Linux VServers, zwany potocznie "chrootem na sterydach". Wymaga on zainstalowania odpowiedniej wersji kernela i odpowiedniego zestawu narzędzi.
Statyczny VIM
Najwaŋniejszym narzędziem administracyjnym jest edytor tekstu, dlatego nie powinniķmy pozostaæ bez takiego programu, co moŋe mieæ miejsce np. przy uszkodzeniu systemu plików. Tu z pomocą przychodzi nam statycznie zlinkowany VIM z pakietu vim-static. Aby nie kolidowaģ ze "zwykģym" vimem, plik wykonywalny jest umieszczany w /bin/vim.
Pakiety
Zagadnienia związane z bezpieczeņstwem zostaģy omówione w sekcja Bezpieczeņstwo w rozdziaģ Zarządzanie pakietami.
Interfejsy sieciowe
W tym rozdziale znajdziesz informacje dotyczące konfiguracji sieci
Wstęp
Pierwszą rzeczą jaką musimy zrobiæ to ustaliæ wszystkie konieczne parametry poģączenia sieciowego. W razie wątpliwoķci naleŋy skontaktowaæ się z naszym dostawcą usģug internetowych. Ten rozdziaģ opisuje konfigurację interfejsów sieciowych, testowanie poģączenia oraz inne prace diagnostyczne przeprowadzimy za pomocą narzędzi opisanych w sekcja Narzędzia sieciowe w rozdziaģ Zastosowania sieciowe.
Zarządzanie caģym podsystemem sieci (wģączanie, wyģączanie, restart) dokonujemy za pomocą rc-skryptu network, więcej informacji o zarządzaniu rc-skryptami znajdziemy w sekcja Zarządzanie podsystemami i usģugami w rozdziaģ Administracja. Jest on integralną częķcią PLD i startuje automatycznie w trakcie uruchomienia systemu. Aby skonfigurowaæ sieæ potrzebujemy jedynie ustawiæ podstawowe parametry sieci (opisane w następnym rozdziale) oraz prawidģowo skonfigurowaæ interfejs(y).
Konfigurację proxy opisano szczegóģowo w sekcja Proxy w rozdziaģ Podstawy.
Jeķli mamy zamiar modyfikowaæ konfigurację sieci na zdalnej maszynie (np. przez ssh), to zalecane jest uŋycie programu screen, aby mieæ pewnoķæ, ŋe caģa procedura zakoņczy się poprawnie i nie utracimy kontaktu z hostem. Jeķli mamy program screen wystarczy ŋe wydamy polecenie:
# screen service network restart |
Podstawowa konfiguracja sieci
W większoķci wypadków konfiguracja sieci (oprócz ustawieņ interfejsu sieciowego) będzie się skģadaģa ze wskazania domyķlnej bramy i serwerów DNS dla resolvera. Wiele zaawansowanych opcji sieci (np. przekazywanie pakietów) ustawianych jest w pliku konfiguracji jądra: /etc/sysctl.conf, parametry te zostaģy omówione w sekcja Parametry jądra w rozdziaģ Kernel i urządzenia.
Brama domyķlna
Jeķli nie korzystamy z serwera DHCP ustawiamy statyczną trasę routingu do domyķlnej bramy, w tym celu edytujemy plik /etc/sysconfig/static-routes - wpis moŋe wyglądaæ następująco:
eth0 default via 192.168.0.1 |
Odwzorowanie nazw - serwery DNS
Wskazanie serwerów DNS jest obowiązkową pozycją konfiguracji resolvera nazw. Operacja ta następuje automatycznie, o ile korzystamy z serwera DHCP, w przeciwnym wypadku musimy podaæ ich adresy samodzielnie. Serwery nazw ustawiamy edytując plik /etc/resolv.conf. Jeķli go nie ma, to moŋemy go utworzyæ za pomocą dowolnego edytora lub poleceniem touch. Podajemy przynajmniej jeden (zazwyczaj nie więcej niŋ dwa) serwer nazw za pomocą sģowa kluczowego nameserver np.:
nameserver 192.168.0.12 |
Nazwa hosta
Moŋemy ustawiæ nazwę, za pomocą której nasza maszyna będzie się przedstawiaģa zalogowanym uŋytkownikom, i niektórym programom. W pliku /etc/sysconfig/network ustawiamy:
HOSTNAME=pldmachine |
Odwzorowanie nazw - konfiguracja zaawansowana
Plik /etc/host.conf zawiera podstawowe opcje resolvera nazw, w większoķci wypadków wystarczy domyķlna konfiguracja:
order hosts,bind multi on |
W pliku /etc/hosts moŋna dodawaæ odwzorowania hostów, które są uzupeģnieniem dla usģugi DNS, jedyny wymagany wpis to wskazanie adresu IP pętli zwrotnej dla nazwy localhost:
127.0.0.1 localhost |
127.0.0.1 localhost styx |
213.25.115.88 platinum.elsat.net.pl |
Jeķli często odwoģujemy się do maszyn w naszej domenie to moŋemy uģatwiæ sobie ŋycie i ustawiæ domenę domyķlną w pliku /etc/resolv.conf. Od tej pory podanie samej nazwy hosta (bez częķci domenowej), będzie uwaŋane za podanie peģnego adresu. Przykģadowe ustawienie domyķlnej domeny (np. jakasdomena.cos) podano poniŋej:
domain jakasdomena.cos |
Inne opcje
Edytujemy plik /etc/sysconfig/network, domyķlne wartoķci opcji z tego pliku w zupeģnoķci wystarczają do typowego korzystania z sieci i nie ma potrzeby nic modyfikowaæ w nim.
NETWORKING=yes |
Ustawiamy na "yes" jeŋeli w ogóle chcemy komunikowaæ się z siecią.
IPV4_NETWORKING=yes |
Ustawiamy na "yes" jeŋeli będziemy korzystaæ z protokoģu IPv4 (wymagany do korzystania z Internetu).
NISDOMAIN= |
Domena NIS, jeķli nie korzystasz z tej usģugi sieciowej, lub nie jesteķ pewien pozostaw to pole puste.
GATEWAY=192.168.0.254 GATEWAYDEV=eth0 |
Opcje za pomocą których moŋemy ustawiæ trasę routingu do domyķlnej bramy. Opcje te zostaģy uznane za przestarzaģe, obecnie naleŋy korzystaæ z pliku /etc/sysconfig/static-routes.
Ethernet
Urządzenie
Większoķæ dostępnych na rynku kart sieciowych jest oparta na ukģadach Realteka, 3Com bądž Intela, dzięki temu nie będzie problemów z uruchomieniem urządzenia. Karty sieciowe są automatycznie wykrywane przez jądro i nadawane są im nazwy kolejno: eth0, eth1, eth2, itd. Jedyną rzeczą jaka pozostaje to zaģadowanie odpowiedniego moduģu dla danego urządzenia, proces ten dokģadnie opisano tutaj: sekcja Moduģy jądra w rozdziaģ Kernel i urządzenia.
Pliki konfiguracyjne interfejsów są przechowywane w katalogu /etc/sysconfig/interfaces, nazwy tych plików będą miaģy kolejno nazwy ifcfg-eth0, ifcfg-eth1, ifcfg-eth2, itd. W tym rozdziale zaģoŋono, ŋe konfigurujemy pierwszy interfejs (eth0). Pliki te modyfikujemy za pomocą dowolnego edytora tekstu np.
# vim /etc/sysconfig/interfaces/ifcfg-eth0 |
Statyczna konfiguracja karty sieciowej
Zaczynamy od zmodyfikowania lub utworzenia pliku /etc/sysconfig/interfaces/ifcfg-eth0, aby karta dziaģaģa poprawnie powinieneķ mieæ tam podobne ustawienia:
DEVICE="eth0" |
Powyŋsza opcja ta okreķla nazwę urządzenia.
IPADDR="192.168.0.2/24" |
Ta opcja okreķla adres karty sieciowej oraz maskę podsieci. Maskę podsieci podajemy w notacji CIDR - "/24" odpowiada masce 255.255.255.0.
ONBOOT="yes" |
Ustaw na "yes" jeķli chcesz aby interfejs automatycznie podnosiģ się razem z podsystemem sieci.
BOOTPROTO="none" |
Ta opcja pozwala dokonaæ wyboru, w jaki sposób karta sieciowa ma otrzymywaæ konfigurację. Powyŋszy wpis sprawia, ŋe system pobiera wszystkie ustawienia z posiadanych plików konfiguracyjnych.
Na koņcu aktywujemy sieæ.
Dynamiczna konfiguracja karty sieciowej (DHCP)
Na początek wybieramy jeden z programów klienckich: dhcpcd lub pump:
# poldek -i dhcpcd |
Nasze zadanie ogranicza się do zmiany jednego parametru w pliku /etc/sysconfig/interfaces/ifcfg-eth0. Odszukujemy w nim opcję BOOTPROTO i wskazujemy klienta DHCP, który ma byæ uŋyty:
BOOTPROTO="dhcp" |
Na koniec dokonujemy aktywacji interfejsu.
Maģa uwaga: przy uŋyciu DHCP statyczne opcje sieciowe (adres IP, maska podsieci, brama) umieszczone w plikach konfiguracyjnych będą ignorowane, zaķ zawartoķæ pliku /etc/resolv.conf będzie nadpisywana informacjami przyznanymi przez serwer DHCP.
Aktywacja sieci
Ostatnią czynnoķcią jest uruchomienie lub restart podsystemu sieci:
# /etc/rc.d/init.d/network start Ustawianie parametrów sieci....................[ ZROBIONE ] Podnoszenie interfejsu eth0....................[ ZROBIONE ] |
WiFi
Wstęp
W przypadku laptopa dobrym pomysģem jest uŋycie jakiejķ aplikacji X-Window do konfiguracji WiFi, z moŋliwoķcią ģatwego przeģączania pomiędzy sieciami oraz automatycznym wykrywanie podģączenia kabla do karty Ethernet. Takie moŋliwoķci zapewnia np. NetworkManager (korzysta z aplikacji wpa_supplicant), przeznaczony dla ķrodowiska Gnome. W przypadku stacjonarnych maszyn konfiguracja rc-skryptów powinna byæ wystarczająca w większoķci wypadków.
W naszych przykģadach przedstawimy konfigurację dla sieci
bezprzewodowej dziaģającej w trybie trybie infrastruktury
(managed), o okreķlonym identyfikatorze SSID
i zabezpieczonej kluczem WEP oraz
WPA2-PSK (WPA2 Personal).
WEP zawiera zbyt duŋo sģabych punktów i jest
podatny na szybkie zģamanie, dlatego o ile nie jesteķmy ograniczeni
sprzętem to naleŋy uŋywaæ wģaķnie WPA2.
Niektóre karty sieciowe WiFi mają dedykowane sterowniki i ich konfiguracja nie sprawia większych kģopotów, w pozostaģych wypadkach posģuŋymy się sterownikami dla systemu Microsoft Windows, uruchomionymi dzięki aplikacji NdisWrapper. Jest to moŋliwe dzięki temu, ŋe większoķæ sterowników jest napisana zgodnie ze standardem NDIS. Po zaģadowaniu moduģów, dalsza konfiguracja interfejsu w obu przypadkach przebiega niemal identycznie.
Sterowniki dedykowane
Do kernela w wersji 2.6.24 trafiģo wiele moduģów obsģugujących sterowniki kart WLAN, sterowniki rozwijane niezaleŋnie są dostępne w osobnych pakietach kernel-net-* Przykģadowo zainstalujemy moduģ dla kart Atheros:
$ poldek -i kernel-net-madwifi-ng |
# modprobe ath_pci |
Sterowniki z NdisWrapperem
Instalujemy pakiety kernel-net-ndiswrapper oraz ndiswrapper:
$ poldek -i ndiswrapper kernel-net-ndiswrapper |
Potrzebne nam będą teraz sterowniki windowsowe naszej karty sieciowej. Konkretnie chodzi o pliki z rozszerzeniami *.inf oraz *.sys. Moŋesz je skopiowaæ z dostarczonej przez producenta pģytki ze sterownikami
# mkdir /lib/windrivers # cd /lib/windrivers # cp /media/cdrom/sciezka/do/sterownikow/sterownik.inf . # cp /media/cdrom/sciezka/do/sterownikow/sterownik.sys . |
Musimy teraz zainstalowaæ te sterowniki przy uŋyciu NdisWrappera.
# ndiswrapper -i /lib/windrivers/sterownik.inf |
Jeķli chcemy aby stworzyģ się alias w pliku /etc/modprobe.conf wykonujemy polecenie:
# ndiswrapper -m |
Sieæ WEP
Domyķlnie rc-skrypty do obsģugi WLAN uŋywają pakietu wireless-tools:
$ poldek -i wireless-tools |
DEVICE=wlan0 IPADDR=192.168.0.2/24 ONBOOT=yes BOOTPROTO=dhcp WLAN_ESSID=nasza_nazwa_sieci WLAN_KEY=A638FED41027EA086ECD6825B0 |
Jako urządzenie w opcji DEVICE wskazujemy nadaną przez kernel nazwę. Kartom nadawane są zwykle nazwy wlan0, wlan1, itd. Wyjątkiem od tej reguģy są niektóre sterowniki, rozwijane niezaleŋnie od kernela np. ath{$NR} dla kart z ukģadami Atheros Communications, czy ra{$NR} dla Ralink Technology (w kernelach do 2.6.24). To jaka nazwa zostaģa przydzielona naszemu urządzeniu moŋemy odczytaæ z komunikatów jądra.
Poniŋej przedstawione zostaną parametry sieci WLAN:
WLAN_ESSID=moja_siec |
WLAN_KEY=A638FED41027EA086ECD6825B0 |
Dodatkowo moŋemy ustawiæ szybkoķæ interfejsu:
WLAN_BITRATE=auto |
Sieæ WPA2-PSK
Opisane powyŋej wireless-tools nie potrafią uŋywaæ szyfrowania WPA/WPA2, dlatego konieczny nam będzie pakiet wpa_supplicant:
$ poldek -i wpa_supplicant |
Edytujemy plik /etc/wpa_supplicant.conf, w którym definiujemy opcje sieci WLAN:
ap_scan=1
network={
ssid="nasza_nazwa_sieci"
key_mgmt=WPA-PSK
proto=RSN
pairwise=CCMP TKIP
group=CCMP TKIP WEP104 WEP40
psk=anejdlf7323e64ekjlkbdsxhjsldjf3fda
} |
psk moŋe byæ jawne
lub kodowane za pomocą polecenia wpa_passphrase
Testujemy poģączenie z WiFi:
# ifconfig wlan0 up # wpa_supplicant -Dwext -iwlan0 -c/etc/wpa_supplicant.conf -dd |
-dd wģącza tryb debugowania i
jeŋeli nie otrzymamy jakichķ bģędów, to przerywamy
dziaģanie wpa_supplicant
skrótem ctr-c
Pozostaģa nam jeszcze edycja
/etc/sysconfig/interfaces/ifcfg-wlan0,
w celu wskazania, ŋe chcemy korzystaæ z wpa_supplicant:
DEVICE=wlan0 IPADDR=192.168.0.2/24 ONBOOT=yes BOOTPROTO=dhcp WLAN_WPA=yes WLAN_WPA_DRIVER=wext |
Restartujemy ponownie naszą sieæ:
# /etc/init.d/network restart |
Aktywacja i diagnostyka
Na wszelki wypadek powinniķmy się upewniæ, ŋe nasza maszyna jest w zasięgu sieci radiowej:
# iwlist wlan0 scan |
# /etc/rc.d/init.d/network start Ustawianie parametrów sieci....................[ ZROBIONE ] Podnoszenie interfejsu wlan0...................[ ZROBIONE ] |
# iwconfig
lo no wireless extensions.
eth0 no wireless extensions.
wlan0 IEEE 802.11g ESSID:"nasza_nazwa_sieci" Nickname:"foo.com"
Mode:Managed Frequency:2.412 GHz Access Point: 8A:1C:F0:6F:43:2D
Bit Rate=300 Mb/s Sensitivity=-200 dBm
RTS thr=2346 B Fragment thr=2346 B
Encryption key:ABFA-155B-E90F-1D1C-FC34-66ED Security mode:restricted
Power Management:off
Link Quality:100/100 Signal level:-30 dBm Noise level:-96 dBm
Rx invalid nwid:0 Rx invalid crypt:0
Rx invalid frag:0
Tx excessive retries:0 Invalid misc:0 Missed beacon:0 |
W przypadku uŋycia pakietu wpa_supplicant moŋemy uŋyæ programu wpa_cli:
wpa_cli status Selected interface 'wlan0' bssid=00:1e:e5:6d:62:5e ssid=nasza_nazwa_sieci id=0 pairwise_cipher=CCMP group_cipher=TKIP key_mgmt=WPA2-PSK wpa_state=COMPLETED ip_address=192.168.0.2 |
Jeŋeli mamy kartę obsģugującą tryb "n" moŋe nam się przydaæ polecenie iwpriv z pakietu wireless-tools. Moŋemy przeģączyæ wtedy kartę wifi w szybszy tryb, poniewaŋ często z automatu wģączony jest wolniejszy np. "g". Uruchamiamy więc:
# iwpriv wlan0 network_type n |
# iwlist bitrate
lo no bit-rate information.
eth0 no bit-rate information.
wlan0 8 available bit-rates :
6 Mb/s
9 Mb/s
12 Mb/s
18 Mb/s
24 Mb/s
36 Mb/s
48 Mb/s
54 Mb/s
Current Bit Rate=270 Mb/s |
Neostrada+ z modemem USB firmy Sagem
Wprowadzenie
Na samym początku musimy wģączyæ w biosie komputera port USB oraz zainstalowaæ takie pakiety jak eagle oraz kernel-usb-eagle. Dodatkowo musimy jeszcze zainstalowaæ pakiet ppp. Jeŋeli zainstalowaģeķ system z pģytki MINI-iso, powinieneķ je tam znaležæ. W przypadku, kiedy instalowaģeķ system z dyskietki, znajdziesz je na jednej lub kilku dyskietek "addons" czyli dyskietek zawierających dodatkowe pakiety.
Instalacja
Przystępujemy do instalacji. Naleŋy przejķæ do do lokalizacji w której znajdują się owe pakiety a następnie wydaæ następujące polecenie.
# rpm -Uvh kernel-usb-eagle* eagle-usb* ppp* |
Kiedy juŋ upewniliķmy się, ŋe mamy wģączony port USB w biosie, musimy go zainicjowaæ w systemie. Moŋemy to zrobiæ za pomocą pliku /etc/modules.conf w którym umieszczamy przykģadową linijkę
alias usb-controller usb-uhci |
Jeŋeli posiadasz zainstalowany kernel z serii 2.6.x powinieneķ umieķciæ następujący wpis w pliku /etc/modprobe.conf
alias usb-controller uhci-hcd |
Po ponownym uruchomieniu komputera powinniķmy posiadaæ w systemie obecny moduģ usb-uhci (uhci-hcd dla jądra 2.6.x). W przypadku, kiedy ten moduģ po prostu nie zadziaģa spróbuj zaģadowaæ usb-ohci (ohci-hcd dla jądra 2.6.x). Jeŋeli podģączyģeķ modem do portu USB 2.0 powinieneķ uŋyæ moduģu usb-ehci (ehci-hcd dla jądra 2.6.x).
Moŋemy teraz podģączyæ modem do komputera. Nasze urządzenie zostanie od razu wykryte i zainicjowane w systemie. Poprawna inicjalizacja powinna zakoņczyæ się zaģadowaniem do pamięci moduģu adiusbadsl. UWAGA! Jeŋeli posiadasz kernel 2.6.x powinieneķ zaģadowaæ moduģ eagle-usb.
Konfiguracja
Moŋemy zacząæ od pliku /etc/resolv.conf. Opis znajdziecie w rozdziale poķwięconym konfiguracji sieci. Przystępujemy teraz do konfiguracji pliku /etc/eagle-usb/eagle-usb.conf. Naleŋy w nim zmieniæ wartoķæ opcji VPI na taką jaką widzicie poniŋej.
VPI=00000000 |
Skonfigurujemy teraz demona PPP. Utworzonemu w wyniku instalacji plikowi /etc/ppp/options zmieniamy nazwę na options.old. Tworzymy nowy plik options z zawartoķcią taką jaka zostaģa przedstawiona na poniŋszym listingu. Najwaŋniejszą rzeczą jest podanie w nim nazwy uŋytkownika, która jest konieczna do ustanowienia poģączenia. Moŋemy równieŋ dopisaæ opcję debug, jeķli chcemy byæ informowani o tym co się dzieje.
# cat /etc/ppp/options user "user@neostrada.pl" mru 1492 mtu 1492 noipdefault defaultroute usepeerdns noauth #ipcp-accept-remote #ipcp-accept-loacal nobsdcomp nodeflate nopcomp novj novjccomp #novaccomp -am noaccomp -am #wģączam debug. debug |
Musimy jeszcze wpisaæ hasģo. Aby tego dokonaæ wyedytujmy plik /etc/ppp/chap-secrets. UWAGA! Jeŋeli się pomylisz i wpiszesz hasģo do /etc/ppp/pap-secrets, hasģo nie zadziaģa.
# cat /etc/ppp/chap-secrets user@neostrada.pl * haslo * |
Na tym zakoņczymy konfigurację poģączenia z Neostradą. Jesteķmy juŋ gotowi aby wszystko uruchomiæ.
Uruchomienie i post konfiguracja
Najbardziej wygodnym sposobem będzie wykorzystanie mechanizmu rc-scripts do uruchamiania usģugi. Do tego potrzebny będzie odpowiedni plik konfiguracji, przykģadowy taki plik umieszczono w katalogu /usr/share/doc/rc-scipts/ oraz na poniŋszym wydruku:
DEVICE=ppp0 ONBOOT=yes PPPOA_EAGLE=yes AUTH=no MTU=1452 PERSIST=yes DEFROUTE=yes USEPEERDNS=yes PAPNAME=XXX@neostrada.pl # put password in /etc/ppp/pap-secrets or install # ppp-plugin-ifcfg-password and uncommend following lines # PLUGIN_IFCFG_PASSWORD=yes # PASSWORD=YYYY |
Plik zapisujemy jako /etc/sysconfig/interfaces/ifcfg-ppp0 i wydajemy polecenie:
# ifup ppp0 |
Dzięki opcji ONBOOT=yes poģączenie będzie nawiązywane wraz z
uruchamianiem systemu.
Moŋemy sprawdziæ np. pingiem ģącznoķæ z jakimķ zewnętrznym serwerem, np. ping www.pld-linux.org. Jeŋeli posiadasz jakąķ sieæ LAN, lub kilka komputerów w mieszkaniu, powinieneķ przeczytaæ rozdziaģ poķwięcony maskaradzie.
Neostrada+ z modemem USB firmy Alcatel - Thompson
Przygotowanie do instalacji
Oto krótka lista tego, co będzie nam potrzebne do uruchomienia modemu.
Port USB w komputerze
Jądro z serii 2.4 lub 2.6
Programy: modem_run oraz pppoa3
Pakiet: ppp-plugin-pppoatm
Firmware do modemu.
Firmware dla modemu moŋna ķciągnąæ z stąd: http://speedtouch.sourceforge.net/files/firmware.bin.
Jeŋeli juŋ upewniģeķ się, ŋe masz wszystkie wymagane rzeczy, moŋemy przystąpiæ do instalacji.
Konfiguracja
W pierwszej kolejnoķci musimy zainicjowaæ w systemie USB, oraz kilka moduģów do obsģugi ppp. Moŋemy to zrobiæ wykonując następujące polecenie
# for i in usbcore uhci acm ppp_generic \
ppp_synctty;do modprobe $i;done |
Komentarza wymaga tutaj obsģuga USB. W przykģadzie zostaģ podany moduģ uhci. Jeŋeli nie zaģaduje się poprawnie (zostaniesz o tym poinformowany) powinieneķ wybraæ jeden z następujących: usb-uhci, usb-ohci lub dla USB 2.0 usb-ehci. Posiadacze jąder z serii 2.6 mają do wyboru następujący zestaw moduģów: uhci-hcd, ohci-hcd lub ehci-hcd. Ta róŋnorodnoķæ jest uwarunkowana sprzętowo, w zaleŋnoķci od rodzaju chipsetu obsģugującego porty USB. Waŋną rolę tutaj odgrywa moduģ acm, gdyŋ bez niego nie będzie moŋliwe zaģadowanie firmware do modemu. W kernelach z serii 2.6.x odpowiednikiem acm jest moduģ cdc-acm.
Posiadacze kernela z serii 2.6.x mogą uŋyæ poniŋszej pętli która zaģaduje wszystkie potrzebne moduģy. Oczywiķcie naleŋy zwróciæ uwagę aby zaģadowaæ odpowiedni dla Twojego sprzętu moduģ obsģugujący kontroler USB na pģycie gģównej.
# for i in usbcore uhci-hcd cdc-acm ppp_generic ppp_synctty;do modprobe $i;done |
Następnym krokiem jest podmontowanie systemu plików w proc.
# mount none /proc/bus/usb -t usbfs |
W tym momencie moŋemy sprawdziæ, czy SpeedTouch rzeczywiķcie jest widziany przez system. Aby tego dokonaæ wykonaj poniŋsze polecenie
# cat /proc/bus/usb/devices [...] S: Manufacturer=ALCATEL S: Product=Speed Touch 330 [...] |
Musisz teraz zainstalowaæ oprogramowanie do modemu. Robimy to wydając następujące polecenie:
# poldek -U speedtouch |
Podģącz modem do komputera. Będzie on potrzebowaģ do dziaģania specjalnego pliku, tak zwanego firmware. Program modem_run potrafi odczytywaæ firmware w formatach przygotowanych dla Linuksa, Windowsa oraz MacOS. Jakie są moŋliwoķci pobrania pliku firmware? Moŋemy pobraæ go z adresu podanego na początku rozdziaģu. Jest to firmware przygotowany dla systemu MacOS. Linuksowy firmware moŋemy pobraæ ze strony Alcatela: www.speedtouchdsl.com/dvrreg_lx.htm. Wymagana jest rejestracja. Moŋemy równieŋ go wziąæ z pģytki dostarczonej przez TPSA. Powinien on znajdowaæ się w archiwum Linux/ThomsonST330/pliki.tar.gz. Po jego rozpakowaniu powinniķmy mieæ coķ takiego jak: drivers/speedmgmt.tar.gz. Posiadając juŋ plik speedmgmt.tar.gz moŋemy sobie zbudowaæ pakiet rpm z firmwarem przy uŋyciu speedtouch-firmware.spec. Musimy tylko skopiowaæ archiwum do katalogu ~/rpm/SOURCES. Dalsze instrukcje dotyczące budowania pakietów znajdziesz w tej dokumentacji w rozdziale: Tworzenie PLD. Po zainstalowaniu zbudowanego pakietu z firmwarem, moŋemy go zaģadowaæ wydając poniŋsze polecenie:
# modem_run -v 1 -m -f /ķcieŋka/do/firmware |
Ģadowanie firmware do modemu moŋe trochę potrwaæ. Jeŋeli chcesz widzieæ co się dzieje wpisz następujące polecenie
# tail -f /var/log/messages |
W trakcie ģadowania pliku firmware, zaczną migaæ diody urządzenia. Będzie to oznaczaæ synchronizację linii. Po kilkunastu sekundach modem się ustabilizuje. Diody powrócą do zielonego koloru.
Jeŋeli masz zainstalowany kernel z serii 2.6 lub 2.4.22+ wykonaj poniŋsze polecenia:
# modprobe speedtch # modem_run -k -m -v 1 -f /usr/share/speedtouch/mgmt.o # modprobe pppoatm |
Moduģ speedtch jest potrzebny do uŋycia opcji -k (moŋe byæ ģadowany automatycznie przez hotplug. Z kolei pppoatm będzie potrzebny do uruchomienia pppd. Nie ģaduje się on automatycznie, dlatego naleŋy go dopisaæ np. do /etc/modules.
W porządku. Po zakoņczonej operacji ģadowania firmware jesteķmy gotowi aby skonfigurowaæ nasze ppp do neostrady. Zanim to zrobimy będziemy musieli zainstalowaæ pakiet ppp-plugin-pppoatm.
# poldek -U ppp-plugin-pppoatm |
W zaleŋnoķci od wersji zainstalowanego kernela (2.6 lub 2.4) konfiguracja demona pppd będzie się róŋniģa kilkoma szczegóģami. Poniŋej przedstawiam przykģady dla obu serii jąder.
Linux z serii 2.4
# cat /etc/ppp/peers/neostrada debug lock noipdefault defaultroute pty "/usr/sbin/pppoa3 -v 1 -e 1 -c -m 1 -vpi 0 -vci 35" asyncmap 0 lcp-echo-interval 2 lcp-echo-failure 7 sync user "user@neostrada.pl" noauth holdoff 3 persist maxfail 25 mru 1500 mtu 1500 |
Linux z serii 2.6 lub 2.4.22+
# cat /etc/ppp/peers/neostrada noauth usepeerdns noipdefault defaultroute pty "/usr/sbin/pppoa3 -e 1 -v 1 -m 1 -c -vpi 0 -vci 35" sync user nasz_login noaccomp nopcomp noccp holdoff 4 persist maxfail 25 |
Waŋną rolę odgrywa tu parametr -e 1, gdyŋ bez niego nie uzyskamy
poģączenia.
Oczywiķcie musimy jeszcze odpowiednio skonfigurowaæ pap-secrets oraz chap-secrets
# cat /etc/ppp/chap-secrets user@neostrada.pl * haslo * |
Uruchomienie i zakoņczenie
W celu nawiązania poģączenia, które uprzednio skonfigurowaliķmy, wydajemy takie oto polecenie
pppd call neostrada |
Jeŋeli nie chcemy, bądž z jakichķ powodów nie moŋemy korzystaæ z programu hotplug nie musimy tego robiæ. Nie jest on tak naprawdę niezbędny. W takim przypadku za kaŋdym razem będziemy musieli ģadowaæ firmware modemu programem modem_run.
xDSL z interfejsem Ethernet
Wprowadzenie
Coraz więcej dostawców usģug internetowych oferuje dzierŋawę linii xDSL z portem LAN typu Ethernet, takie usģugi oferują np. Telekomunikacja Polska (Internet DSL) oraz Dialog (DIALNET DSL).
Konfiguracja
W celu uruchomienia usģugi, wystarczy jedynie skonfigurowaæ interfejs sieciowy Ethernet w naszym komputerze, zgodnie z informacjami uzyskanymi od dostawcy ģącza (konfiguracja statyczna). Poniŋej przedstawiono skrócony opis konfiguracji tego typu interfejsu, szczegóģowy opis znajdziemy tutaj: sekcja Ethernet
Podniesienie interfejsu eth0 moŋemy osiągnąæ tworząc lub edytując (jeķli istnieje) plik /etc/sysconfig/interfaces/ifcfg-eth0 i wpisując dane otrzymane od dostawcy:
DEVICE="eth0" IPADDR="80.55.203.222/30" ONBOOT="yes" BOOTPROTO="none" |
Istotną kwestią jest przypisanie odpowiedniego prefiksu (maski podsieci) przy podaniu adresu IP zarezerwowanego dla abonenta. Prefiks wykorzystywane w usģudze InternetDSL, to: /30 Internet DSL 512 oraz Internet DSL 1 (przydzielone 4 adresy IP, co odpowiada masce podsieci 255.255.255.252), /29 Internet DSL 2 (przydzielone 8 adresów IP, co odpowiada masce podsieci 255.255.255.248). Naleŋy pamiętaæ ŋe 3 adresy IP są zarezerwowane do obsģugi poģączenia (adres sieci,brama,broadcast)
Ostatnią zmianą potrzebną do prawidģowego dziaģania sieci jest wyedytowanie pliku /etc/sysconfig/network. Naleŋy tam podaæ adres bramy (IP modemu DSL).
GATEWAY="80.55.203.221" GATEWAYDEV="eth0" |
Na koniec pozostaje nam uruchomienie podsystemu sieci:
# service network start |
Uwagi
Jeķli przy ģączu Internet DSL 1 zdarzają się przypadki zerwania poģączenia, naleŋy przywiązaæ wszystkie 5 adresów IP jako wirtualne interfejsy
IPADDR1="ip1/29" IPADDR2="ip2/29" IPADDR3="ip3/29" IPADDR4="ip4/29" IPADDR5="ip5/29" |
Zaawansowane opcje interfejsów
HotPlug
HotPlug jest mechanizmem pozwalającym na automatyczne konfigurwanie systemu po podģączeniu okreķlonego urządzenia. W przypadku urządzeņ sieciowych PCMCIA i USB moŋliwe jest automatyczne aktywowanie interfejsu od razu po podģączeniu urządzenia.
Aby uruchomiæ ten mechanizm musimy najpierw zainstalowaæ odpowiednie oprogramowanie:
# poldek -i hotplug* |
Kolejnym krokiem będzie umieszczenie odpowiedniego wpisu w pliku konfiguracji interfejsu sieciowego. Dodajemy opcję:
HOTPLUG=yes |
Narzędzia
Narzędzia do zarządzania i diagnostyki interfejsów sieciowych opisano w sekcja Narzędzia sieciowe w rozdziaģ Zastosowania sieciowe.
Inne opcje
Zaawansowane opcje sieciowe interfejsów nie są umieszczane w plikach generowanych w trakcie instalacji systemu. Ich opis znajdziemy w pliku /usr/share/doc/rc-scripts/ifcfg-description.gz.
Wzory konfiguracji
Wiele przykģadowych konfiguracji interfejsów sieciowych odnajdziemy w katalogu z dokumentacją do rc-skryptów: /usr/share/doc/rc-scripts. Są to pliki tekstowe zarchiwizowane programem Gzip.
Zastosowania sieciowe
W tym rozdziale znajdziesz informacje dotyczące konfiguracji sieci
Routing statyczny
Podstawowe trasy do podsieci są automatycznie tworzone przy konfiguracji interfejsów sieciowych na podstawie podanego adresu IP i maski podsieci. Trasa domyķlna jest konfigurowana na podstawie ustawieņ w pliku /etc/sysconfig/network. Operacje te zostaģy opisane w poprzednim rozdziale, w przypadku bardziej zaawansowanych zastosowaņ musimy samodzielnie skonfigurowaæ trasy pakietów.
Wstępna konfiguracja
Konfigurację routingu obowiązkowo rozpoczynamy od wģączenia przekazywania pakietów między interfejsami sieciowymi, opcję tą moŋemy ustawiæ tymczasowo wykonując polecenie
# echo "1" > /proc/sys/net/ipv4/ip_forward |
Moŋemy teŋ w pliku /etc/sysctl.conf ustawiæ następująca opcję:
net.ipv4.ip_forward = 1 |
# service network restart |
Tablica routingu
Aby wyķwietliæ tablicę routingu posģuŋymy się poleceniem ip route:
# ip route 10.0.0.4/32 dev eth0 proto kernel scope link src 10.0.0.4 10.0.0.0/24 dev eth1 proto kernel scope link src 10.0.0.1 default via 10.0.0.100 dev eth0 onlink |
Zarządzanie trasami
Zarządzenia routingiem na kilku przykģadach:
Dodanie trasy do hosta
# ip route add 10.0.0.4/32 dev eth0 |
Dodanie trasy do podsieci
# ip route add 10.0.0.0/24 dev eth1 |
Wskazanie bramy domyķlnej:
# ip route add 0/0 via 10.0.0.100 dev eth0 |
dodatkowe opcje:
src {$adres_IP} - adres žródģowy nowo tworzonych pakietów, opcja ma istotne znaczenie m.in. w przypadku przypisania kilku adresów IP do tego samego interfejsu.
protocol {$nazwa/$numer} - opcja waŋna w przypadku ģączenia trasowania statycznego z dynamicznym. Najczęķciej stykamy się z protokoģami: redirect, kernel, boot, ra. Ich peģną listę wraz z odpowiadającym im numerom znajdziemy w pliku /etc/iproute2/rt_protos. Dla samego statycznego routowania nie ma potrzeby jej definiowania.
Usuwanie reguģek jest bardzo podobne do dodawania, musimy uŋyæ opcji "del" zamiast "add".
Zakoņczenie
Dodane przez nas reguģki moŋemy zapisac na staģe, w ten sposób zostaną automatycznie wczytanie po "podniesieniu" podsystemu sieci. W tym celu modyfikujemy plik /etc/sysconfig/static-routes np.:
eth0 10.0.0.0/24 eth1 192.168.0.0/24 src 192.168.0.4
Jądro uŋywa specjalnego cache do wydajniejszego trasowania pakietów, ma to jednak pewną wadę: zmiany w nim nie następują od razu po zmodyfikowaniu tablicy routingu. Aby wymusiæ natychmiastowe wyczyszczenie cache naleŋy uŋyæ poniŋszego polecenia:
# ip route flush cache
NAT
NAT (Network Address Translation) w Linuksie moŋna zrobiæ na dwa sposoby:
wykorzystując infrastrukturę netfilter jądra 2.4 i 2.6.
korzystając z narzędzi do kontrolowania sieci z pakietu iproute2.
Oryginalna dokumentacja Netfilter w języku angielskim
Najlepszym sposobem jest wykorzystanie moŋliwoķci netfilter, gdyŋ wykonuje on nat przed (PREROUTING) lub po (POSTROUTING) routingu, co daje nam moŋliwoķæ tak skonfigurowania firewalla, jak by nie byģo wykonywane NAT. NAT w iptables tworzymy dodając reguģki do tabeli "nat". Ŋeby sprawdziæ jakie są dostępne "Chains" w tabeli nat, naleŋy wykonaæ takie polecenie:
# iptables -t nat -L |
W poniŋszych przykģadach zaģoŋyliķmy, ŋe 1.2.3.4 jest adresem IP podniesionym na interfejsie zewnętrznym ($if_wan) zaķ 192.168.1.0/16 to adresy na interfejsie sieci lokalnej ($if_lan).
DNAT
W PREROUTING są reguģki do wykonania DNAT (Destination NAT). Zamienia to adres hosta docelowego na nasz prywatny, w ten sposób moŋemy przekierowaæ ruch na dowolny host w sieci prywatnej:
# iptables -t nat -A PREROUTING -d 1.2.3.4 -j DNAT --to 192.168.1.2 |
Moŋna okreķliæ na jakim interfejsie będzie wykonany NAT poprzez opcję -i $inteface. Opcja -o w PREROUTING nie jest dostępna.
Moŋemy teŋ dokonaæ przekierowania ruchu kierowanego na konkretny port, zwanego potocznie przekierowaniem portu:
# iptables -t nat -A PREROUTING -i $if_wan -p TCP -d 1.2.3.4 --dport 8000 -j DNAT --to 192.168.1.11:80 |
SNAT i MASQUERADE
SNAT (Source NAT) zmienia to adres nadawcy np. z puli adresów prywatnych na adres z puli publicznej, co jest wykorzytywane zwykle do "dzielenia ģącza".
# iptables -t nat -A POSTROUTING -s 192.168.1.2 -j SNAT --to 1.2.3.4 |
Jeķli podamy maskę podsieci, zostanie wykorzystana większa iloķæ adresów.
MASQUERADE wykonuje to samo co SNAT z tym, ŋe na adres interfejsu jakim wychodzi pakiet. Uŋywaæ go naleŋy tylko kiedy nasz adres publiczny zmienia się. (np. w poģączeniach ze zmiennym IP publicznym)
Zakoņczenie.
Po ustawieniu DNAT na adres wewnętrzny zauwaŋymy, ŋe jest problem z dostępem do ip 1.2.3.4 z wewnątrz sieci. Dzieje się tak dlatego, ŋe adres source zostaje bez zmian, dlatego teŋ pakiet nie wraca do bramy. Musimy więc zmusiæ, aby host wysyģaģ odpowiedž do bramy. Moŋemy wykonaæ to w następujący sposób:
# iptables -t nat -A POSTROUTING -o $if_lan -s 192.168.0.0/16 \ -d 1.2.3.4 -j SNAT --to 192.168.0.1 |
Gdzie $if_lan to interfejs lokalnej sieci, a 192.168.0.1 to adres na tym interfejsie.
Podziaģ ģącza w zaleŋnoķci od serwisów
Wstęp
Administratorzy sieci osiedlowych często natrafiają na problemy z programami p2p. Potrafią one skutecznie zapychaæ ģącza. Jednym z moŋliwych rozwiązaņ jest zablokowanie takiego ruchu, a drugim opisanym w tym dokumencie, jest przekierowanie go na jedno z ģącz - odciąŋając tym samym drugie.
Jednym z moŋliwych problemów moŋe byæ "zatykanie" modemu, więc naleŋy się dowiedzieæ ile modem moŋe obsģuŋyæ aktywnych poģączeņ i ograniczyæ wyjķcie przez iptables do tej wartoķci.
Podstawy
Ograniczenie moŋna wykonaæ w ten sposób:
# iptables -t filter -A FORWARD -s 192.168.3.0/24 -o eth1 -p tcp -m mark \ --mark 0x0 -m connlimit --connlimit-above 300 --connlimit-mask 32 \ -j REJECT --reject-with tcp-reset |
Co powoduje ograniczenie uŋytkownikom do 300 wychodzących poģączeņ TCP. Wyeliminuje to problem, kiedy pakiety nie są w stanie wyjķæ w ķwiat gdyŋ za duŋo jest aktywnych poģączeņ i modem się zawiesza.
Drugim sposobem jest ograniczenie pasma wychodzącego w taki sposób, ŋeby router pilnowaģ, aby na modemie nie byģo zbyt duŋego ruchu sieciowego.
# tc qdisc del dev eth1 root
# tc qdisc add dev eth1 root handle 1 cbq bandwidth 256Kbit \
avpkt 1000 cell 8
# tc class change dev eth1 root cbq weight 32bit allot 1514
# tc class add dev eth1 parent 1: classid 1:2 cbq bandwidth 256Kbit \
rate 216Kbit weight 27Kbit prio 1 allot 1514 cell 8 maxburst 20 \
avpkt 1000 bounded
# tc qdisc add dev eth1 parent 1:2 handle 2 tbf rate 216Kbit \
buffer 10Kb/8 limit 15Kb mtu 1500
# tc filter add dev eth1 parent 1:0 protocol ip prio 100 u32 \
match ip src $ip_nat classid 1:2 |
Gdzie $ip_nat to adres ip serwera
Przekierowanie p2p i poģączeņ podobnych
Trzecim sposobem jest zakupienie drugiego, taniego ģącza i puszczenie nim niechcianego ruchu np tak:
Caģy niezidentyfikowany ruch przekierowywany jest na ģącze dodatkowe, a zidentyfikowany na ģącze drugie (szybsze).
Na początek ustawimy w tabeli mangle takie reguģki, sģuŋąc do oznaczania odpowiednich pakietów:
// przywrócenie wartoķci mark dla nawiązanych juŋ poģączeņ
# iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark
// jeķli się okaŋe, ŋe jakieķ p2p dziaģa na portach preferowanych to
// zaznaczy je i wtedy nie przepuķci
# iptables -t mangle -A PREROUTING -p tcp -m ipp2p --ipp2p \
-j MARK --set-mark 0x1214
# iptables -t mangle -A PREROUTING -p tcp -m ipp2p --ipp2p-data \
-j MARK --set-mark 0x1214
// zachowanie dla potomnoķci
# iptables -t mangle -A PREROUTING -p tcp -m mark --mark 0x1214 \
-j CONNMARK --save-mark
// jeķli jakiķ pakiet jest juŋ oznaczony to wychodzi
// z tabeli mangle i sprawdza kolejne reguģki iptables
# iptables -t mangle -A PREROUTING -m mark ! --mark 0x0 -j RETURN
// znakuje uprzywilejowane servisy
# iptables -t mangle -A PREROUTING -p icmp -s 192.168.0.0/16 \
-j MARK --set-mark 0x1
# iptables -t mangle -A PREROUTING -p udp -s 192.168.0.0/16 \
-j MARK --set-mark 0x1
// porty 1:1024
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
--dport 1:1024 -j MARK --set-mark 0x1
// mysql
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
--dport 3306 -j MARK --set-mark 0x1
// gg
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
--dport 8074 -j MARK --set-mark 0x1
// cache
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
--dport 8080 -j MARK --set-mark 0x1
// gra americans army
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
--dport 1716:1718 -j MARK --set-mark 0x1
// irc
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16
--dport 6665:6667 -j MARK --set-mark 0x1
// gra enemy terrytory
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
--dport 27960 -j MARK --set-mark 0x1
// gra MU Online
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
--dport 55201 -j MARK --set-mark 0x1
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
--dport 44405 -j MARK --set-mark 0x1
// wszystkie porty dobrze znanych serwerów
// www.wp.pl
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
-d 212.77.100.101 -j MARK --set-mark 0x1
// czat.wp.pl
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
-d 212.77.100.113 -j MARK --set-mark 0x1
// www.onet.pl
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
-d 213.180.130.200 -j MARK --set-mark 0x1
//strona z grami Online www.miniclip.com
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
-d 69.0.241.20 -j MARK --set-mark 0x1
// www.kurnik.pl
# iptables -t mangle -A PREROUTING -p tcp -s 192.168.0.0/16 \
-d 217.17.45.25 -j MARK --set-mark 0x1
// no i jeszcze zachowaæ dla potomnoķci
# iptables -t mangle -A PREROUTING -p tcp -m mark --mark 0x1 \
-j CONNMARK --save-mark |
Jeķli juŋ mamy oznaczone pakiety naleŋy je odpowiednio przekierowaæ. Moŋemy skorzystaæ z dobrodziejstwa iproute2 i dodaæ następujące reguģki:
# ip route add from 192.168.0.0/16 fwmark 0x1214 lookup TABLE_SMIECI # ip route add from 192.168.0.0/16 fwmark 0x1 lookup TABLE_PRIORYTET // ta reguģka kieruje caģy nieoznakowany ruch na ģącze ķmieci // potrzebne jeķli domyķlne jest inne ģącze # ip route add from 192.168.0.0/18 lookup TABLE_SMIECI |
Oczywiķcie trzeba dodaæ do tabeli odpowiednie wpisy default i informacje o sieciach obsģugiwanych przez ten router. Naleŋy jeszcze wykonaæ te polecenia dla interfejsu z wyjķciem w ķwiat:
# echo 0 > /proc/sys/net/ipv4/conf/eth1/rp_filter |
Po takich zabiegach uŋytkownicy powinni odczuæ znaczny wzrost wydajnoķci ģącza PRIORYTET
Niestety ģącze SMIECI jest maksymalnie zapchane, więc naleŋy przygotowaæ się na narzekania uŋytkowników którzy są przekierowani na to ģącze.
Przy takim rozwiązaniu naleŋy mieæ staģą kontrolę nad usģugami, które mają dziaģaæ na ģączu PRIORYTET i stale uaktualniaæ tabelę mangle o odpowiednie wpisy.
Nie udaģo się niestety przekierowaæ samego ruchu p2p gdyŋ podczas nawiązywania poģączenia nie wiemy jeszcze czy jest to pakiet naleŋący do p2p. Dzisiejsze programy p2p potrafią dziaģaæ na portach poniŋej 1024 np 80 (http) więc rozróŋnienie ich po portach nic nie da
Innym rozwiązaniem moŋe byæ wydzielenie portów dla programów p2p i ogģoszenie ich uŋytkownikom sieci. Naleŋy wtedy zablokowaæ ruch p2p na wszystkie porty oprócz tych wydzielonych i jeķli ktoķ się nie dostosuje to nie będzie miaģ transferu. To rozwiązanie ma jednak wadę: będzie generowaģo duŋo poģączeņ nawiązywanych (pakiety SYN) na obu ģączach, gdyŋ iptables nie pozwoli na transfer dopiero po nawiązaniu poģączenia i rozpoznaniu poģączania jako naleŋącego do p2p.
PPP over SSH - Tunel IPv4
Wstęp
Zaletą tego rodzaju tunelu jest to, ŋe jego dziaģanie opiera się na jednych z bardziej popularnych protokoģach PPP oraz SSH. Komunikacja odbywa się na porcie 22. Dzięki temu nie zachodzi potrzeba otwierania dodatkowych portów komunikacyjnych w konfiguracji zapory ogniowej. Interfejsy tunelu uruchamiane są przez demona pppd. Posģuŋą nam one do zestawienia trasy między dwoma hostami lub sieciami w zaleŋnoķci od potrzeb. Do naszych celów będzie potrzebny demon pppd będący implementacją protokoģu ppp oraz klient i serwer ssh implementujący protokóģ ssh.
Konfiguracja
Zanim przystąpimy do konfiguracji musimy zdecydowaæ który komputer będzie serwerem a który klientem. Klient będzie inicjowaģ poģączenie z serwerem uruchamiając demona pppd.
Serwer
Zanim przystąpimy do konfiguracji naleŋy sprawdziæ czy system wyposaŋony jest w demona ppp oraz serwer ssh. Pakiety które to udostępniają to odpowiednio ppp oraz openssh-server. Przydatnym moŋe się okazaæ pakiet openssh-clients zawierający jak sama nazwa wskazuje klienta ssh.
Po zainstalowaniu wyŋej wymienionych pakietów przechodzimy do konfiguracji systemu. W pierwszej kolejnoķci zakģadamy konto uŋytkownika oraz przydzielamy mu grupę.
# groupadd vpn-users # useradd -m -s /usr/sbin/pppd -g vpn-users vpn # passwd vpn New UNIX password: Retype new UNIX password: passwd: password updated successfully |
Efekt wykonanych poleceņ moŋesz zobaczyæ na listingu poniŋej
# grep vpn /etc/passwd vpn:x:506:1005::/home/users/vpn:/usr/sbin/pppd #grep vpn-users /etc/group vpn-users:x:1005: |
Wynik tych poleceņ powinien odpowiadaæ temu co tutaj widaæ. GID grupy vpn-users wynosi 1005 czyli odpowiada GID ustawionemu w pliku /etc/passwd. Poleceniem passwd ustawiamy hasģo dla tego konta, które zostaģo wpisane do /etc/shadow.
Istotnym dla konfiguracji elementem w katalogu uŋytkownika vpn jest katalog ~/.ssh. Moŋemy go stworzyæ (o ile wczeķniej zainstalowaliķmy) przy pomocy klienta ssh. Robimy to w dwóch krokach które obrazuje poniŋszy przykģad
# su - vpn -s /bin/bash
$ ssh domena.pl
Warning: Permanently added 'domena.pl,xxx.xxx.xx.x' \
(RSA) to the list of known hosts.
Password:
^C |
Moŋna teŋ ręcznie utworzyæ z poziomu konta vpn ten katalog poleceniem mkdir. Aby umoŋliwiæ uŋytkownikowi prawo do wykonania po zalogowaniu polecenia /usr/sbin/pppd naleŋy nadaæ temu plikowi suida.
# chmod 4755 /usr/sbin/pppd |
Konfigurację warstwy ssh mamy juŋ za sobą. Moŋemy teraz przystąpiæ do konfiguracji demona pppd. Demon
nie będzie wymagaģ autoryzacji, więc w pliku /etc/ppp/options wyszukujemy opcję
auth i zmieniamy ją na noauth. Musimy teraz skonfigurowaæ wierzchoģek
(tzw. peer) koņca tunelu. Tworzymy więc plik /etc/ppp/peers/tunel okreķlający
wszystkie niezbędne parametry poģączenia. Na listingu poniŋej przykģadowa konfiguracja
wierzchoģka.
# cat /etc/ppp/peers/tunel 192.168.1.100:192.168.1.101 noauth lcp-echo-interval 5 lcp-echo-failure 3 |
W pierwszej linijce oddzielone są dwukropkiem adresy IP wierzchoģków tunelu. Ten po lewej stronie zostanie ustawiony na interfejsie serwera, ten po prawej klienta. Przedstawioną konfigurację naleŋy potraktowaæ jako przykģad i dostosowaæ ją do rzeczywistej. Oczywiķcie, jeŋeli speģnia ona Twoje wymagania moŋesz ją zastosowaæ.
noauth- wyģączamy autoryzację ppplcp-echo-interval- wartoķæ przy tej opcji okreķla interwaģ w sekundach z jakim wysyģana będzie do peera ramka ŋądania o echo LCP. Demon sprawdza w ten sposób czy poģączenie nadal jest aktywne.lcp-echo-failure- wartoķæ podana przy tej opcji okreķla ile ŋądaņ o echo LCP ma zostaæ wysģanych jeŋeli peer nie daģ odpowiedzi. Po tylu próbach demon stwierdzi, ŋe poģączenie zostaģo utracone.
Klient
Konfiguracja po stronie klienta sprowadza się do wygenerowania kluczy rsa oraz odpowieniego ustawienia demona pppd. Klucze nam są potrzebne do autentykacji nie interaktywnej ssh. Inaczej nie uda nam się nawiązaæ poģączenia z serwerem. Do zestawienia poģączenia z serwerem po stronie klienta wymagana jest instalacja pakietów ppp oraz openssh-clients. Jeŋeli ich nie posiadasz musisz je niezwģocznie zainstalowaæ.
Przystępujemy do dalszej konfiguracji usģugi po stronie klienta. Zaczniemy od wspomnianego na wstępie generowania kluczy.
$ ssh-keygen -b 1024 -f ~/.ssh/klucz -t rsa -P "" Generating public/private rsa key pair. Your identification has been saved in /home/users/foo/.ssh/klucz. Your public key has been saved in /home/users/foo/.ssh/klucz.pub. The key fingerprint is: c9:d8:17:bd:ba:82:a0:f0:47:7c:32:c2:e8:7e:32:e8 foo@pldmachine |
Do generowania kluczy sģuŋy znajdujące się w pakiecie openssh-clients polecenie ssh-keygen. Uŋyliķmy go z następującymi parametrami:
-b- dģugoķæ klucza w bitach. Wartoķæ podana na listingu jest minimalną dģugoķcią klucza która jest akceptowana przez demona sshd.-f- nazwa pliku (moŋna podaæ ķcieŋkę do niego) zawierającego klucz prywatny.-t- typ klucza. Na listingu jest to RSA. RSA jest algorytmem sģuŋącym do generowania kluczy.-P- hasģo klucza. Na potrzeby tunelu hasģo musi pozostaæ puste. Inaczej tunel nie zadziaģa. Demon sshd będzie czekaģ na potwierdzenie hasģem klucza co nigdy nie nastąpi, gdyŋ sesja ssh będzie inicjowana poprzez demona pppd uniemoŋliwiając nam w sposób interaktywny jej przejęcie.
Kolejnym krokiem jest skopiowanie zawartoķci pliku klucz.pub do pliku ~vpn/.ssh/authorized_keys na serwerze. Moŋemy tego dokonaæ w następujący sposób.
$ scp ~/.ssh/klucz.pub vpn@domena.pl:~/.ssh/authorized_keys |
Polecenie to zadziaģa tylko wtedy, kiedy na koncie vpn znajdującym się na serwerze zmienimy tymczasowo powģokę z /usr/sbin/pppd na standardową /bin/bash. Na tym etapie koņczy się caģa konfiguracja dotycząca ssh po obu stronach. Moŋemy więc przywróciæ na serwerze w pliku /etc/passwd dla uŋytkownika vpn powģokę na /usr/sbin/pppd. Przystępujemy teraz do skonfigurowania demona pppd, który będzie wywoģywaģ podczas ustanawiania poģączenia klienta ssh.
Podobnie jak po stronie serwera w pliku
/etc/ppp/options musimy opcję
auth zmieniæ na noauth. Kiedy juŋ
to zrobimy, przystąpimy do konfiguracji wierzchoģka (tzw. peera) dla
klienta, który będzie inicjowaģ poģączenie. Nazwa pliku moŋe byæ taka
sama jak na serwerze. Poniŋej na listingu znajduje się przykģadowa
konfiguracja wierzchoģka dla klienta.
# cat /etc/ppp/peers/tunel 192.168.1.101:192.168.1.100 debug noauth pty "ssh -i ~/.ssh/klucz vpn@domena.pl" connect-delay 5000 |
Pierwsza linijka w pliku to dwa adresy IP oddzielone znakiem dwukropka. Adres po lewej stronie jest adresem tego koņca tunelu, który wģaķnie konfigurujemy. Pamiętamy, ŋe adres 192.168.1.100 zostaģ juŋ przydzielony jako adres wierzchoģka serwera. Pozostaģe opcje zostaģy objaķnione poniŋej.
debug- wģączamy raportowanie szczegóģów poģączenia ppp.noauth- wyģączamy autoryzację.pty- dzięki tej opcji moŋemy wykorzystaæ zewnętrzny skrypt jako oķrodek komunikacji zamiast konkretnego urządzenia terminalowego. Wykorzystujemy tutaj ssh.connect-delay- okreķlony w milisekundach czas oczekiwanie na prawidģowy pakiet PPP od peera. Jeŋeli taki w tym czasie nadejdzie pppd rozpocznie negocjację wysyģając pierwszy pakiet LCP.
W przypadku problemów z poģączeniem moŋemy zwiększyæ wartoķæ connect-delay
nawet dziesięciokrotnie jeŋeli ģącza pomiędzy którymi zestawiamy tunel będą sporo
obciąŋone. Równieŋ po stronie klienta musimy nadaæ bit suid plikowi
/usr/sbin/pppd.
# chmod 4755 /usr/sbin/pppd |
Na tym koņczymy konfigurację tunelu. Moŋemy przejķæ do fazy jego uruchomienia.
Uruchomienie
Skonfigurowane poģączenie naleŋy teraz zainicjowaæ wykonując polecenie:
$ /usr/sbin/pppd call tunel |
Udana próba poģączenia poģączenia powinna zaowocowaæ zapisami w logach takimi jak poniŋej na listingu.
Sep 2 12:35:34 pldmachine pppd[6623]: pppd 2.4.2b3 started by foo, uid 501
Sep 2 12:35:34 pldmachine pppd[6623]: Using interface ppp0
Sep 2 12:35:34 pldmachine pppd[6623]: Connect: ppp0 <--> /dev/pts/0
Sep 2 12:35:37 pldmachine pppd[6623]: Deflate (15) compression enabled
Sep 2 12:35:37 pldmachine pppd[6623]: Cannot determine ethernet \
address for proxy ARP
Sep 2 12:35:37 pldmachine pppd[6623]: local IP address 192.168.1.101
Sep 2 12:35:37 pldmachine pppd[6623]: remote IP address 192.168.1.100 |
Wykonując po obu stronach polecenie ifconfig zauwaŋysz, ŋe utworzone zostaģy interfejsy ppp sģuŋące do komunikacji. Wykorzystamy je do zestawienia prostej trasy pomiędzy dwoma sieciami.
Zakģadając, ŋe jedna sieæ po stronie serwera ma adresację 192.168.0.0/24 a po stronie klienta 192.168.2.0/24 routing będzie wyglądaģ w sposób następujący.
Po stronie serwera:
# route add -net 192.168.2.0/24 gw 192.168.1.100 |
Po stronie klienta:
# route add -net 192.168.0.0/24 gw 192.168.1.101 |
W ten sposób oba komputery będą przechowywaģy w swoich tablicach routingu informacje o sieciach poģączonych dzięki interfejsom tunelu.
VTun - Tunel IPv4
Wstęp
VTun umoŋliwia tworzenie tuneli poprzez sieci TCP/IP wraz z przydzielaniem pasma, kompresją, szyfrowaniem danych w tunelach. Wspierane typy tuneli to: PPP, IP, Ethernet i większoķæ pozostaģych protokoģów szeregowych. VTun jest ģatwy i elastyczny w konfiguracji. Moŋe zostaæ wykorzystany do takich sieciowych zastosowaņ jak VPN, Mobil IP, ģącza o okreķlonym paķmie oraz innych. Dziaģa w warstwie user space.
Opis procesu konfiguracji tunelu podzielony zostaģ na częķæ klient oraz serwer. Adresacja uŋyta na listingach moŋe zostaæ uŋyta o ile nie będzie się ona kģóciģa z bieŋącą konfiguracją Twojej sieci. Zaczynamy od instalacji pakietu vtun na obu maszynach będących koņcami tunelu. Dodatkowo ģadujemy moduģ tun do pamięci.
# modprobe tun |
Na tym koņczy się wstępne przygotowanie systemu do konfiguracji tunelu.
Konfiguracja
Serwer
Po zainstalowaniu pakietu, opcja VTUND_MODE w pliku
/etc/sysconfig/vtun powinna
byæ ustawiona tak jak na listingu poniŋej
# grep VTUND_MODE /etc/sysconfig/vtun VTUND_MODE="server" |
Plikiem konfiguracyjnym dla VTuna jest /etc/vtund.conf. Po instalacji pakietu jest on wypeģniony przykģadami konfiguracji róŋnego rodzaju tuneli po obu stronach (klient - serwer). Warto je sobie zostawiæ. W tym celu wystarczy jedynie zmieniæ nazwę pliku.
# mv /etc/vtund.conf /etc/vtund.conf.orig |
Przy uŋyciu ulubionego edytora stwórzmy nowy plik
/etc/vtund.conf. Moŋemy w nim wyodrębniæ kilka
sekcji: options, default,
nazwa, up oraz
down. Sekcje up oraz down są podsekcjami sekcji
nazwa.
options - opcje dotyczące dziaģania demona oraz
wykorzystywanych przez niego programów.
options {
port 5000;
syslog daemon;
ppp /usr/sbin/pppd;
ifconfig /sbin/ifconfig;
route /sbin/route;
firewall /sbin/iptables;
ip /sbin/ip;
} |
port- port na którym ma nasģuchiwaæ demon.syslog- sposób logowania zdarzeņ na interfejsie tunelu.ppp ifconfig route firewall ip- zmienne, które zawierają ķcieŋki do wykorzystywanych przez VTun programów.
default - domyķlne ustawienia transmisji danych.
default {
compress yes;
speed 0;
} |
compress- kompresja pakietów w trakcie transmisji.speed- prędkoķæ transmisji. Wartoķæ0oznacza brak ograniczeņ.
vpn1 - wymieniona wczeķniej nazwa tunelu. W tym miejscu
znajduje się wģaķciwa konfiguracja parametrów poģączenia.
vpn1 {
passwd tajne.haslo;
type tun;
proto tcp;
compress zlib:9;
encrypt yes;
keepalive yes;
up {
...
};
down {
...
};
} |
passwd- hasģo, które posģuŋy do szyfrowania poģączenia.type- typ tunelu (w przykģadzie tunel IP)proto- protokóģ warstwy transmisyjnej tunelu.compress- metoda oraz stopieņ kompresji.encrypt- wģączenie szyfrowania transmisji.keepalive- utrzymywanie poģączeniaup, down- co ma się wykonaæ po nawiązaniu poģączenia oraz jego zakoņczeniu. Szerzej o tym poniŋej.
up - akcje wykonywane po nawiązaniu poģączenia.
up {
ifconfig "%% 192.168.2.10 pointopoint 192.168.2.11 mtu 1450";
route "add -host 192.168.2.11 gw 192.168.2.10";
}; |
Po nawiązaniu poģączenia naleŋy uruchomiæ odpowiedni interfejs. Jego nazwa zostanie rozwiązana dzięki zmiennej %%. Okreķlamy oczywiķcie typ interfejsu oraz jego MTU. Kolejną czynnoķcią jest podanie trasy do drugiego koņca tunelu. Adres IP po prawej stronie jest oczywiķcie adresem naszego (czyli serwera) koņca i przez niego prowadzi droga na drugą stronę.
down - czynnoķci następujące po wyģączeniu tunelu.
down {
ifconfig "%% down";
ifconfig "%% delete";
route "delete -host 192.168.2.11"
};
|
Po zakoņczeniu dziaģania poģączenia powinniķmy wyģączyæ oraz skasowaæ interfejs który nam do
niego sģuŋyģ. Usuwamy równieŋ zbędną trasę do drugiego koņca tunelu z tablicy routingu. Zwróæ
uwagę na konstrukcję tych dwóch podsekcji. polecenie "argument". Polecenie
zostaģo okreķlone w sekcji options, natomiast argumentami są odpowiednie
parametry danego polecenia.
Na tym koņczy się konfiguracja serwera. Moŋemy przystąpiæ teraz do konfiguracji klienta.
Klient
Konfigurację klienta zaczniemy od edycji pliku /etc/sysconfig/vtun. Opcje w nim zawarte powinieneķ ustawiæ zgodnie z tym co jest przedstawione na listingu.
VTUND_MODE="client" VTUND_SESSION="vpn1" VTUND_SERVER_ADDR="123.45.67.89" VTUND_SERVER_PORT="5000" |
VTUND_MODE- tryb pracy demona.VTUND_SESSION- nazwa sesji, którą ustawimy w pliku konfiguracyjnymVTUND_SERVER_ADDR- publiczny adres IP serwera.VTUND_SERVER_PORT- port na którym nasģuchuje serwer.
Równieŋ po stronie klienta musimy wyedytowaæ plik /etc/vtund.conf. Takŋe i tutaj moŋemy mu zmieniæ nazwę na vtund.conf.orig, aby zachowaæ przykģady konfiguracji. Krok po kroku omówię sekcje vtund.conf po stronie klienta.
options {
type stand;
port 5000;
syslog daemon;
timeout 60;
ppp /usr/sbin/pppd;
ifconfig /sbin/ifconfig;
route /sbin/route;
firewall /sbin/iptables;
ip /sbin/ip;
} |
type- tryb pracy VTuna. Na listingu ustawiony zostaģstandalone.port- port na którym nasģuchuje VTun.syslog- logi VTuna zbierane będą przez syslog.timeout- timeout VTuna.ppp, ifconfig, route, firewall, ip- ķcieŋki do programów wykorzystywanych w czasie konfiguracji.
Przystępujemy teraz do konfiguracji poģączenia o nazwie vpn1. Jak pamiętasz nazwa zostaģa juŋ wstępnie okreķlona w pliku /etc/sysconfig/vtun.
vpn1 {
passwd tajne.haslo;
type tun;
proto tcp;
compress zlib:9;
encrypt yes;
keepalive yes;
stat yes;
persist yes;
up {
...
};
down {
...
};
} |
passwd- hasģo które posģuŋy nam do szyfrowania poģączenia.type- typ tunelu, w przykģadzie jest to tunel IP.proto- protokóģ warstwy transmisyjnej tunelu.compress- typ oraz stopieņ kompresji. Na listingu ustawiona zostaģa kompresja przy uŋyciu zlib dziewiątego stopnia.encrypt- wģączamy szyfrowanie poģączenia.keepalive- utrzymywanie poģączenia w przypadku braku ruchu na interfejsie tunelu.stat- statystyki pracy tunelu, które VTun będzie zapisywaģ do sysloga co pięæ minut.persist- opcja ustawiona tak jak na listingu sprawi, ŋe w przypadku zerwania poģączenia z serwerem klient będzie nawiązywaģ poģączenie.up, down- programy wykonywane po nawiązaniu poģączenia i po jego zerwaniu.
up {
ifconfig "%% 192.168.2.11 pointopoint 192.168.2.10 mtu 1450";
route "add -host 192.168.2.10 gw 192.168.2.11";
}; |
Poleceniem ifconfig uruchamiamy interfejs naszego tunelu o parametrach
takich jakie zostaģy podane w przykģadzie. Następnym krokiem jest wyznaczenie trasy do naszego
serwera, czyli drugiego koņca tunelu. Jak doskonale widaæ, ta częķæ konfiguracji jest
analogiczna do serwera. Naleŋy tylko zwróciæ uwagę na adresację. Adres następujący po
parametrze gw okreķla nasz (czyli klienta) koniec tunelu. Przez niego wiedzie
droga na drugi koniec.
down {
ifconfig "%% down";
ifconfig "%% delete";
route "del -host 192.168.2.10";
}; |
Polecenia które się wykonają po zamknięciu poģączenia. Kolejno, wyģączamy oraz kasujemy interfejs tunelu. Następnie kasujemy z tablicy routingu trasę do serwera.
Na tym koņczy się etap konfiguracji VTuna. Moŋemy przejķæ do jego uruchomienia.
Uruchomienie
Uruchomienie VTuna sprowadza się do wykonania jednego polecenia na serwerze oraz kliencie.
# /etc/rc.d/init.d/vtund start |
Po jego wykonaniu na komputerach będących koņcami tunelu za kilka chwil powinny się utworzyæ interfejsy tun0. Numeracja zaczyna się od "0". Nazwy kolejnych interfejsów będą koņczyæ się następną w kolejnoķci liczbą naturalną.
Narzędzia sieciowe
W PLD gģównym pakietem narzędzi sieciowych jest iproute2, oferuje on większe moŋliwoķci oraz bardziej ujednolicony interfejs obsģugi w stosunku do narzędzi z pakietu net-tools (ifconfig, route, arp, ifup, ifdown). Sercem pakietu iproute2 jest program ip zawierający funkcjonalnoķæ kilku starszych narzędzi w jednym. Z tego względu będzie naszym podstawowym narzędziem sieciowym.
Jako dodatek do niniejszego rozdziaģu, pragnę poleciæ lekturę opisu najprostszych narzędzi sieciowych (ping, traceroute), który moŋna znaležæ w sekcja Podstawowe narzędzia kontroli sieci TCP/IP w rozdziaģ Podstawy oraz opis zarządzania routingiem statycznym zamieszczony w sekcja Routing statyczny.
Konfiguracja interfejsow
Aby wyķwietliæ konfigurację interfejsów uŋyjemy polecenia ip addr.
# ip addr
1: lo: <LOOPBACK,UP> mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:50:8d:e1:e8:83 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 brd 10.0.0.255 scope global eth0
inet 10.0.0.22/24 brd 10.0.0.255 scope global secondary eth0
inet6 fe80::250:8dff:fee1:e883/64 scope link
valid_lft forever preferred_lft forever
3: sit0: <NOARP> mtu 1480 qdisc noop
link/sit 0.0.0.0 brd 0.0.0.0 |
Polecenie wyķwietliģo listę dostępnych interfejsów, kaŋdy z nich oznaczony jest numerem porządkowym. W większoķci wypadków najbardziej interesujące są dla nas interfejsy fizyczne (eth0 na powyŋszym przykģadzie). Interfejsy lo oraz sit0, są "wirtualnymi" interfejsami, pierwszy z nich to interfejs pętli zwrotnej (loopback), drugi sģuŋy do tunelowania protokoģu IPv6 wewnątrz IPv4.
Tryb pracy urządzenia jest wyķwietlany wewnątrz trójkątnych nawiasów, oto kilka oznaczeņ:
UP - urządzenie dziaģa
LOOPBACK - interfejs pętli zwrotnej
BROADCAST - urządzenie ma moŋliwoķæ wysyģania komunikatów rozgģoszeniowych
MULTICAST - interfejs moŋe byæ uŋywany do transmisji typu multicast
PROMISC - tryb nasģuchiwania, uŋywany przez monitory sieci i sniffery
NO-CARRIER - brak noķnej, komunikat spotykany zwykle w wypadku braku fizycznego poģączenia z siecią
Poniŋej omawianego wiersza wyķwietlone zostaģy informacje o adresach związanych z urządzeniem (adresy IP i maski podsieci są przedstawione w notacji CIDR):
-link/ether - adres fizyczny karty sieciowej (MAC)
-inet - dane protokoģu IPv4
-inet6 - dane protokoģu IPv6
Zarządzanie interfejsami
Do najczęstszych operacji tego typu naleŋy wģączanie i wyģączanie interfejsów, w tym celu uŋyjemy następującego polecenia:
ip link set {$interfejs} {up/down}
# ip link set eth0 up # ip link set eth0 down |
Dodawanie/usuwanie adresów IP interfejsu:
ip addr {add/del} {$adresIP}/{$maska} dev {$interfejs}
# ip addr add 10.1.1.1/24 dev eth0 # ip addr del 10.1.1.1/24 dev eth0 |
Adresy sprzętowe (MAC)
Do odczytania adresu sprzętowego lokalnych kart sieciowych moŋemy uŋyæ opisanego wczeķniej polecenia ip addr. Aby odczytaæ MAC zdalnej maszyny uŋyjemy programu arping {$nazwa/$IP} np.:
# arping 10.0.0.100 ARPING 10.0.0.100 from 10.0.0.1 eth0 Unicast reply from 10.0.0.100 [00:04:ED:07:25:F8] 4.250ms Unicast reply from 10.0.0.100 [00:04:ED:07:25:F8] 0.976ms Unicast reply from 10.0.0.100 [00:04:ED:07:25:F8] 0.929ms |
Dowolny adres MAC karty sieciowej ustawimy poleceniem:
ip link set {$interfejs} address {$MAC-adres}
# ip link set eth0 address 01:01:01:01:01:01 |
Aby adres sprzętowy za kaŋdym razem byģ ustawiany dla interfejsu, powinniķmy dokonaæ odpowiedniego wpisu w pliku konfiguracyjnym interfejsu. W przypadku urządzenia eth0 musimy zmodyfikowaæ plik /etc/sysconfig/interfaces/ifcfg-eth0, i dodaæ zmienną MACADDR np.:
MACADDR="01:01:01:01:01:01" |
ARP
Aby wyķwietliæ tablicę ARP naleŋy uŋyæ polecenia ip neighbour:
# ip neighbour 10.0.0.140 ether 00:E0:7D:A1:8B:E2 C eth0 10.0.0.2 ether 4C:00:10:54:19:50 C eth0 10.0.0.100 ether 00:04:ED:07:25:F8 C eth0 |
Tablica ARP wypeģnia się w miarę komunikowania się z innymi hostami, aby wymusiæ zbadanie dziaģania protokoģu ARP wystarczy zainicjowaæ komunikację. Moŋemy uŋyæ do tego programu ping.
Moŋemy stworzyæ wģasną, statyczną tablicę ARP, posģuŋy nam do tego plik /etc/sysconfig/static-arp w którym umieszczamy wpisy zawierające kolejno: interfejs, adres MAC, adres IP oraz status wpisu.
eth0 00:80:48:12:c2:3c 192.168.10.10 permanent eth0 00:c0:df:f9:4e:ac 10.0.0.7 permanent |
Serwery nazw (DNS)
Do odpytywania serwerów DNS moŋemy uŋyæ programu host z pakietu bind-utils. Pozwala na szybkie sprawdzenie poprawnoķci konfiguracji domeny (strefy).
host {$nazwa/$IP} {$dns_nazwa/$dns_IP}
Pierwszy parametr to nazwa domeny lub IP maszyny, drugi parametr nie jest obowiązkowy - wskazuje na serwer nazw, który chcemy odpytaæ. Jeķli nie podamy drugiego parametru uŋyty zostanie serwer zdefiniowany w pliku /etc/resolv.conf.
Odpytanie serwera DNS o domenę, wpisanego do pliku /etc/resolv.conf
$ host pld-linux.org pld-linux.org has address 217.149.246.8 |
Odpytanie o adres IP (odwzorowanie odwrotne)
$ host 217.149.246.8 8.246.149.217.in-addr.arpa domain name pointer webmachine.pld-linux.org. |
Odpytanie dowolnego serwera DNS
$ host pld-linux.org ns4.pld-linux.org. Using domain server: Name: ns4.pld-linux.org. Address: 217.149.246.7#53 Aliases: pld-linux.org has address 217.149.246.8 |
Aby odczytaæ konkretny rekord domeny uŋyjemy parametru "-t". Dla przykģadu spróbujemy okreķliæ rekord MX dla domeny pld-linux.org:
$ host -t mx pld-linux.org pld-linux.org mail is handled by 0 a.mx.pld-linux.org. |
W celu poznania szczegóģów zarejestrowanej domeny (np. obsģugujące ją serwery nazw) moŋemy posģuŋyæ się programem whois:
$ whois pld-linux.org |
Wydajnoķæ sieci
Aby sprawdziæ przepustowoķæ sieci pomiędzy dwoma hostami moŋemy uŋyæ programu iperf. Jest to program typu klient-serwer sprawdzający na kilka sposobów przepustowoķæ poģączenia. Rozpoczynamy od instalacji programu na obu interesujących nas maszynach, następnie na jednej z maszyn uruchamiamy program w trybie serwera:
$ iperf -s |
$ iperf -c 192.168.0.5 |
Po chwili odczytujemy wyniki testu.
Monitorowanie sieci
Nawiązane poģączenia i otwarte porty protokoģu TCP/IP moŋemy kontrolowaæ za pomocą programu netstat np.:
# netstat -tua Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 *:blackjack *:* LISTEN tcp 0 0 *:ircs *:* LISTEN tcp 0 0 *:netbios-ssn *:* LISTEN tcp 0 0 *:ipp *:* LISTEN tcp 0 0 *:microsoft-ds *:* LISTEN tcp 0 0 gargamel:ircs 192.168.1.3:rapidmq-reg ESTABLISHED tcp 0 0 gargamel:imaps 192.168.1.6:ttc-etap-ds ESTABLISHED tcp 0 0 gargamel:td-postman host-92.gadugadu.p:8074 ESTABLISHED tcp 0 0 gargamel:cma chrome.pl:5223 ESTABLISHED tcp 0 0 *:1024 *:* LISTEN udp 0 0 gargamel:netbios-ns *:* udp 0 0 *:netbios-ns *:* udp 0 0 *:ipp *:* |
Na powyŋszym przykģadzie zostaģy wyķwietlone dane dotyczące protokoģu TCP (opcja: -t) oraz UDP (-u). Dodatkowo zostaģy wyķwietlone gniazda nasģuchujące (-a). Warte uwagi są jeszcze dwa parametry: -n i -p, pierwszy wyķwietla porty i adresy w postaci liczb, drugi zaķ wyķwietla nazwy programów korzystających z danych gniazd.
Do analizowania wielkoķci ruchu sieciowego na interfejsie polecam program nload, jest to proste narzędzie rysujące wykresy pomocą znaków ASCII. Podstawowe statystyki moŋemy przeglądaæ dzięki programowi ip np. ip -s link, dokģadniejsze dane otrzymamy dzięki programowi iptraf.
Wygodnym sposobem ķledzenia wybranego ruchu sieciowego jest uŋycie reguģek linuksowego filtra pakietów. Do ķledzenia ruchu sģuŋy cel "-j LOG" np.:
# iptables -A INPUT -p TCP --dport 80 -s 10.0.0.3 -j LOG |
Duŋo bardziej szczegóģowe informacje o ruchu sieciowym otrzymamy dzięki programowi tcpdump, jest to rozbudowany sniffer i program do analizy pakietów.
Zakoņczenie
W przypadku modyfikacji plików konfiguracji w większoķci wypadków trzeba dokonaæ restartu podsystemu sieci.
W tym rozdziale opisano niewielki fragment moŋliwoķci dostępnych narzędzi sieciowych. Poniŋsza lista przedstawia miejsca gdzie moŋna znaležæ szerszy opis niektórych zagadnieņ.
NET-3-HOWTO z http://www.jtz.org.pl/
Zaawansowany routing: http://echelon.pl/pubs/NET4.pdf
Dokumentacja iproute2 http://www.policyrouting.org/iproute2-toc.html
Usģugi dostępne w PLD
W rozdziale tym przedstawimy opis instalacji i konfiguracji waŋniejszych usģug dostępnych w PLD
Usģugi - wstęp
Usģugi w PLD są przygotowane do natychmiastowego uruchomienia, wystarczy wyedytowaæ pliki konfiguracji i moŋna korzystaæ z programu. Zanim jednak zaczniemy pracowaæ z usģugami warto zapoznaæ się z opisem zarządzania usģugami zawartym w sekcja Zarządzanie podsystemami i usģugami w rozdziaģ Administracja.
Z wieloma demonami dostarczane są przykģadowe pliki konfiguracji, którymi moŋemy się sugerowaæ przy konfigurowaniu aplikacji, przykģady te są umieszczane w dokumentacji programu, w katalogu /usr/share/doc. Ponadto, zanim uruchomimy usģugę, powinniķmy przyjrzeæ się konfiguracji startowej demona, która umieszczana jest w pliku konfiguracji rc-skryptu - plik ten przychodzi wraz z pakietem i umieszczany jest w katalogu /etc/sysconfig. Zwykle zamieszczone w nim opcje odpowiadają argumentom programu demona, są teŋ opcje okreķlające np. priorytet programu i inne wģaķciwoķci.
W trakcie uruchamiania usģugi zdarzają się trudne do odnalezienia
problemy. Pierwszą rzeczą jaką powinniķmy w takim wypadku zrobiæ
to przeczesaæ logi programu, w takich wypadkach niejednokrotnie
pomaga wģączenie większej "gadatliwoķci" demona. Wygodnym sposobem
szukania bģędów jest uruchomienie demona na pierwszym planie
(bez przejķcia w tģo), w takich wypadkach często demony wysyģają
komunikaty na standardowe wyjķcie. W trudniejszych przypadkach
będziemy zmuszeni uŋycia programu strace
w celu ķledzenia wywoģaņ systemowych aplikacji. W wypadku
demonów powinniķmy uŋyæ opcji -f, aby ķledziæ
równieŋ procesy potomne lub uruchomiæ demona z wyģączonym
forkowaniem procesów. Opisane tu
czynnoķci są specyficzne dla kaŋdego z demonów, zatem musimy
skorzystaæ z dokumentacji wģaķciwej aplikacji.
Aktualizacja niektórych demonów wiąŋe się z pewnymi czynnoķciami przygotowawczymi i poprawkami, problem ten dotyczy szczególnie silników baz danych. Zanim bezmyķlnie zaktualizujemy pakiet, naleŋy dokģadnie zapoznaæ się z dokumentacją produktu, aby uchroniæ się przed unieruchomieniem usģugi na dobre.
W PLD usģugi, podobnie jak inne oprogramowanie, kompilowane jest z najczęķciej uŋywanymi opcjami, jeķli program nie obsģuguje jakichķ funkcji, to powinniķmy sprawdziæ czy uzyskamy je samodzielnie budując pakiet, więcej na ten temat odnajdziemy w sekcja Budowanie pakietów w rozdziaģ Zarządzanie pakietami.
ALSA - Džwięk w Linuksie
Obecnie w Linuksie do obsģugi džwięku stosuje się system ALSA (ang: Advanced Linux Sound Architecture), będący następcą systemu OSS. ALSA to zestaw moduģów jądra oraz kilku narzędzi pomocniczych, moduģy moŋemy ģadowaæ za pomocą systemu UDEV lub statycznie, obydwie metody będą opisane w tym rozdziale. Druga z metod jest bardziej zģoŋona, dlatego początkujących zachęcamy do korzystania z metody opartej o system UDEV.
Instalacja
Zaczynamy od pakietu zawierającego moduģy kernela:
$ poldek -i kernel-sound-alsa |
$ poldek -i alsa-utils |
Konfiguracja z uŋyciem systemu UDEV
Niezaawansowanym zalecamy uŋycie udeva zamiast statycznej konfiguracji (opisanej dalej), ze względu na ģatwiejszą konfigurację. Zakģadam, ŋe w systemie mamy dziaģający UDEV, instalujemy pakiet z rc-skryptem, koniecznym do zapisywania stanu miksera (inicjacja miksera jest wykonywana bezpoķrednio przez UDEV):
$ poldek -i alsa-udev |
# /etc/init.d/alsa-udev start |
Konfiguracja statyczna
Konfiguracja statyczna jest alternatywną metodą w stosunku do powyŋszej. Zaczynamy od zainstalowania pakietu alsa-utils-init:
$ poldek -i alsa-utils-init |
samodzielnie - za pomocą dowolnego edytora tekstu; wpisy moŋemy skopiowaæ z opisu Driver & Docs, urządzenia odnalezionego na liķcie obsģugiwanego sprzętu
za pomocą programu alsaconf, który wykryje urządzenie i dokona koniecznych wpisów
# /usr/sbin/alsaconf |
Po ukazaniu się ekranu z napisem "Searching sound cards" czekamy ok. 10 sekund i wciskamy ctrl-c (konfigurator szybko znajduje naszą wģaķciwą kartę - a poniewaŋ szuka równieŋ kart starego typu oraz róŋnych egzotycznych, co zajmuje mu bardzo duŋo czasu dlatego przerywamy wyszukiwanie). Następne okno pokazuje nam listę znalezionych kart muzycznych (zwykle jedną). Zatwierdzamy wyķwietloną kartę i na pytanie:
Do you want to modify /etc/modprobe.conf? |
Odpowiadamy twierdząco, spowoduje to dopisanie odpowiednich aliasów moduģów do pliku konfigurującego. Kiedy progam zakoņczy dziaģanie, uruchamiamy rc-skrypt:
# /etc/init.d/alsasound start |
Ustawienie miksera i testowanie
Domyķlnie wszystkie "suwaki" miksera są ustawione na zero i dodatkowo wģączone jest wyciszenie (mute), aby to zmieniæ musimy uruchomiæ program alsamixer lub amixer:
# /usr/bin/alsamixer |
# /usr/bin/aplay test.wav |
# /usr/bin/alsaplayer -o alsa test.mp3 |
To juŋ praktycznie koniec instalacji. Pamiętaæ naleŋy, ŋe do niektórych programów naleŋy doczytaæ odpowiednie wtyczki, które umoŋliwią prace z ALSA-ą. Wtyczki te ģatwo rozpoznaæ po dopisce "alsa" w nazwie pakietu.
Na koniec pozostaje nam nadaæ uprawnienia wybranym uŋytkownikom, do obsģugi džwięku. Musimy zapisaæ uŋytkowników do grupy audio np.:
# usermod -A jkowalski audio |
Zaawansowana obsģuga miksera
W wielu przypadkach okazuje się, ŋe posiadamy kartę muzyczną, która nie potrafi miksowaæ džwięku sprzętowo - co powoduje m.in., ŋe jednoczeķnie moŋe z karty korzystaæ jeden program lub proces. Zdarza się takŋe, ŋe niektóre programy na sztywno próbują poģączyæ się np. z OSS w celu obsģugi džwięku (np. Skype). W takim przypadku moŋemy skorzystaæ z wtyczki ALSA-y o nazwie dmix. Wbrew nazwie nie musimy niczego dogrywaæ - wszystko odbywa się w plikach tekstowych: /etc/asound (gdy chcemy ustawieņ globalnych) lub ~/.asoundrc (czyli indywidualnych ustawieņ dla kaŋdego uŋytkownika). Przykģadowy wpis przedstawimy poniŋej - po więcej szczegóģów odsyģamy na strony projektu ALSA (www.alsa-project.org):
# definiujemy urządzenie wirtualne nazwane przez nas demixer
# do którego póžniej będziemy się odwoģywaæ:
pcm.demixer
{
type dmix # typ urządzenia, tutaj "dmix"
ipc_key 1024 # numer musi byæ unikalny
slave {
pcm "hw:0,0" # you cannot use a "plug" device here, darn.
period_time 0
buffer_time 0
period_size 1024 # must be power of 2 and much smoother
# than 1024/8192!
buffer_size 8196 # must be power of 2 and for Audiophile
# card (ICE1712 chip) or a VIA VT82xx
# (snd-via82xx) must be less 6652
#format "S32_LE"
periods 128
rate 44100 # with rate 44100 Hz you *will* hear,
# if demixer is used
}
# bindings are cool. This says, that only the first
# two channels are to be used by dmix, which is enough for
# (most) oss apps and also lets multichannel chios work
# much faster:
#
# Wskazujemy ŋe tylko dwa pierwsze kanaģy bedą uŋywane
# przez demixer (czyli tutaj dmix)
bindings {
0 0 # from 0 => to 0
1 1 # from 1 => to 1
}
} # koniec konfiguracji wirtualnego urządzenia demixer
# następnie ustawiamy przekierowanie z wybranych
# urządzeņ do wirtualnego urządzenia demixer:
# moŋemy przekierowywaæ z następujących urządzeņ OSS:
# /dev/audio
# /dev/dsp
# /dev/dspW
# /dev/midi
# /dev/mixer
# /dev/music
# /dev/sequencer (recording doesn't work yet)
# /dev/sequencer2
# dla /dev/dsp0
pcm.dsp0 {
type plug
slave.pcm "demixer"
}
# dla /dev/dsp
pcm.dsp {
type plug
slave.pcm "demixer"
}
# Software mixing for all aplications
# uses ALSA "default" device
#
# Wszystkie aplikacje korzystające z urządzenia
# default ALSA-y przekierowujemy do miksera
# czyli wszystko przechodzi przez dmix
pcm.!default {
type plug
slave.pcm "demixer"
}
# OSS device /dev/mixer0 use hardware
# Urządzenie OSS /dev/mixer0 bez zmian
# obsģuguje pierwszą (0) kartę audio bezpoķrednio
ctl.mixer0 {
type hw
card 0
} |
Jeķli chcemy jedynie przekierowaæ džwięk z programów obsģugujących tylko OSS do ALSA, bez programowego miksowania (czyli bez uŋywania dmix) wystarczy ŋe wpiszemy tylko:
# from /dev/dsp0 to ALSA
pcm.dsp0 {
type plug
slave.pcm "hw:0"
}
# lub:
# pcm.dsp0 pcm.default
# jeķli "default" nie byģo redefiniowane
ctl.mixer0 {
type hw
card 0
} |
Natomiast najprostsze przekierowanie z /dev/dsp0 do dmix wygląda tak:
pcm.dsp0 {
type plug
slave.pcm "dmix"
} |
Dla chipsetów nvidia nforce(2) (intel8x0) oraz C-media konfiguracja powinna wyglądaæ na przykģad tak:
pcm.nforce-hw {
type hw
card 0
}
pcm.!default {
type plug
slave.pcm "nforce"
}
pcm.nforce {
type dmix
ipc_key 1234
slave {
pcm "hw:0,0"
period_time 0
period_size 1024
buffer_size 4096
#rate 44100
rate 48000
}
}
ctl.nforce-hw {
type hw
card 0
} |
Następnie moŋemy przetestowaæ nasz "dmix" czyli urządzenie demixer
alsaplayer -o alsa -d demixer test.mp3 |
poniewaŋ wczeķniej zdefiniowaliķmy urządzenie "default", ALSA kieruje wszystko na urządzenie "demixer" - co jest równowaŋne:
alsaplayer -o alsa test.mp3 |
To tylko podstawowe przykģady dziaģania jakie daje nam ALSA, a dzięki olbrzymim moŋliwoķciom definiowania dowolnych urządzeņ wirtualnych i przekierowywania džwięku, moŋemy uzyskaæ ciekawe i róŋnorodne efekty. Więcej o konfiguracji urządzeņ PCM znajdziemy tutaj: www.alsa-project.org/alsa-doc/alsa-lib/pcm_plugins.html.
Przy pracy z pluginem "dmix" nie naleŋy zapomnieæ o wyģączeniu demonów ARTs i ESD gdyŋ w przeciwnym razie mogą pojawiæ się opóžnienie w odtwarzaniu džwięków i zakģócenia w niektórych programach, gdyŋ wiele z nich próbuje najpierw korzystaæ z w/w demonów džwięku.
Apache - Serwer stron internetowych
Wstęp
Kaŋdy, nawet początkujący uŋytkownik sieci internet zetknąģ się z apaczem ķwiadomie lub nie. Apache jest oprogramowaniem, które moŋna powiedzieæ zdominowaģo w pewnym stopniu rynek aplikacji serwerowych. Do dziaģania wykorzystuje on protokóģ HTTP (RFC2616). Jak sama nazwa wskazuje Apache (a patche server) skģada się z wielu moduģów. Moŋna to zauwaŋyæ juŋ na pierwszy rzut oka. W tym rozdziale zostanie opisana autoryzacja, obsģuga języka PHP, CGI, virtualhosts oraz ogólna jego konfiguracja. Przedstawiona poniŋej oparta zostaģa o apache z serii 2.x.
Instalacja
Apache w PLD jest podzielony na wiele maģych pakietów, moŋemy dzięki instalowaæ tylko potrzebne moduģy. Jeķli nie moŋemy się poģapaæ w tym gąszczu to moŋemy posģuŋyæ się metapakietem apache, który za poķrednictwem mechanizmu zaleŋnoķci zainstaluje najwaŋniejsze pakiety.
# poldek -i apache |
# service httpd start |
$ elinks localhost/test.html |
Pliki konfiguracji
Tytuģem wstępu pragnę powiedzieæ, ŋe niniejszy dokument nie moŋe byæ traktowany jako dokumentacja do Apache. Ma on na celu uģatwienie uŋytkownikowi zapoznania się z usģugą oraz kilkoma jej moŋliwoķciami. Po bardziej szczegóģowe informacje odsyģam do stron podręcznika systemowego (man) oraz dokumentacji on-line
/etc/httpd/httpd.conf - w tym katalogu przechowywane są pliki konfiguracyjne demona. Po instalacji poszczególnych skģadników Apache, wģaķnie w tym miejscu naleŋy szukaæ plików konfiguracyjnych od nich.
/home/services/httpd - pliki domyķlnej strony Apache, katalog z komunikatami o bģędach oraz katalog przeznaczony dla skryptów cgi.
/usr/lib/apache - moduģy potrzebne do dziaģania Apache oraz poszczególnych jego skģadników. Warto o tym pamiętaæ w przypadku problemów z uruchomieniem usģugi.
/usr/sbin - jest to katalog naleŋący stricte do Apache, jednak warto o nim wspomnieæ ze względu na to iŋ przechowywane są w nim jego binaria. Aby się dowiedzieæ które naleŋą do niego wydaj następujące polecenie
# rpm -ql apache |grep ^\/usr\/sbin
Aby nasz serwer obsģugiwaģ dodatkowe funkcje musimy zainstalowaæ odpowiednie moduģy, wraz z moduģami dostarczane, są pliki konfiguracji z dyrektywami konfiguracyjnymi dla tego moduģu.
Apache domyķlnie dziaģa z uprawnieniami zwykģego uŋytkownika (http), dlatego trzeba zadbaæ o to by demon miaģ prawo do odczytu plików ze stronami WWW.
Bardzo poŋyteczną cechą Apache jest moŋliwoķæ tworzenia lokalnych plików konfiguracji, dzięki którym moŋemy modyfikowaæ niektóre opcje konfiguracji. Pliki te mają nazwę .htaccess i moŋe ich uŋywaæ kaŋdy, kto ma tylko dostęp do katalogu ze stroną WWW. Wygoda w ich uŋywaniu polega na tym, ŋe nie ma potrzeby restartowania demona po kaŋdorazowej ich modyfikacji.
Podstawowa konfiguracja
Gģównym plikiem konfiguracyjnym jest /etc/httpd/apache.conf. Spoķród wielu opcji w tym pliku zajmiemy się dwiema podstawowymi:
ServerAdmin root@example.net |
Powinieneķ tutaj wpisaæ kontaktowy adres e-mail do siebie jako administratora tego serwera.
Poniŋej znajduje się opcja ServerName. Powinna ona
wyglądaæ tak jak w poniŋszym przykģadzie.
ServerName example.net:80 |
Dosģownie jest to nazwa tego serwera. A dokģadniej nazwa domenowa skonfigurowana na serwerze nazw opiekującym się Twoją domeną. Jeŋeli nie posiadasz zarejestrowanej domeny, powinieneķ wpisaæ tutaj adres IP.
Teraz zajmiemy się opcją DocumentRoot, którą odnajdziemy w
/etc/httpd/conf.d/10_common.conf
Okreķla ona domyķlny
katalog w którym będzie przechowywana strona internetowa. Wpisując
nazwę lub adres IP okreķlony przez ServerName wģaķnie
z tego katalogu zostaną pobrane i wczytane przez przeglądarkę pliki
strony.
DocumentRoot "/home/services/httpd/html" |
Domyķlnie wszystkie ŋądania są tutaj skierowane. Ta lokalizacja nie jest obligatoryjna, więc nie musisz się jej trzymaæ. Moŋe zostaæ zmieniona przy uŋyciu dowiązaņ symbolicznych lub aliasów wskazujących w inne miejsca.
Zgodnie z obecnym standardem tworzenia stron internetowych, domyķlnym plikiem który jest automatycznie wczytywany po wpisaniu w przeglądarce adresu jest index, który w zaleŋnoķci od konstrukcji strony moŋe mieæ róŋne rozszerzenia. A więc skąd Apache wie, co ma zostaæ wczytane jako pierwsze? Do tego wģaķnie sģuŋy pakiet apache-mod_dir. Jego plikiem konfiguracyjnym jest /etc/httpd/httpd.conf/59_mod_dir.conf
Poprzez dyrektywę DirectoryIndex okreķla się czego i w
jakiej kolejnoķci ma szukaæ przeglądarka.
DirectoryIndex index.html index.html.var index.htm index.shtml \
index.cgi index.php |
Oczywiķcie moŋemy podawaæ tutaj róŋne nazwy plików startowych stron w zaleŋnoķci od naszych potrzeb.
Strony uŋytkowników
Swobodne publikowanie stron internetowych przez uŋytkowników
jest moŋliwe dzięki pakietowi apache-mod_userdir.
Opcja UserDir w pliku 16_mod_userdir.conf
definiuje nazwę katalogu przechowującego strony uŋytkowników wewnątrz
ich katalogów domowych.
UserDir public_html |
Aby strona się wyķwietliģa naleŋy ustawiæ odpowiednie prawa dostępu - tak by Apache (domyķlnie z prawami uŋytkownika http) miaģ prawo do odczytu. Katalog domowy jan powinien mieæ ustawione prawa 711. Katalog przechowujący jego stronę czyli public_html powinien mieæ 755. Kaŋdy katalog zawierający elementy strony powinien mieæ równieŋ uprawnienia 755. Pliki strony natomiast 644.
Virtual Hosts
Mechanizm hostów wirtualnych pozwala obsģugiwaæ strony o róŋnych adresach domenowych na jednej maszynie. Mechanizm ten jest realizowany na dwa sposoby: hosty oparte o adresy IP oraz oparte o nazwy, pierwsza z metod wymaga osobnego adresu IP dla kaŋdego wirtualnego hosta, drugi zaķ korzysta z jednego. Z oczywistych względów duŋo bardziej popularna jest druga z metod i wģaķnie ją będziemy opisywaæ.
Obsģuga hostów wirtualnych jest związana z odpowiednią konfiguracją domen w systemie DNS - wymaga wpisów typu IN A wskazujących na nasz serwer WWW. Konfigurację serwera DNS opisano w sekcja BIND - Serwer Nazw i będzie docelowo konieczna, jednak dla potrzeb testowych wystarczą nam wpisy w pliku /etc/hosts, który z kolei zostaģ opisany w sekcja Podstawowa konfiguracja sieci w rozdziaģ Interfejsy sieciowe.
W naszym przykģadzie dodamy obsģugę domeny moja-strona.com, na początku naleŋy stworzyæ dodatkowy plik konfiguracji (dla porządku) o nazwie np. vhosts.conf, który umieķcimy w katalogu /etc/httpd/httpd.conf/. Zakģadamy, ŋe wszystkie vhosty będziemy trzymaæ w katalogu /home/services/httpd/vhosts/. Plik będzie się zaczynaģ od następującego zestawu opcji:
NameVirtualHost *
<Directory /home/services/httpd/vhosts>
Order allow,deny
Allow from all
</Directory>
<VirtualHost _default_>
DocumentRoot /home/services/httpd/html/
</VirtualHost>
|
<VirtualHost *>
ServerName moja-strona.com
DocumentRoot /home/services/httpd/vhosts/moja_strona
</VirtualHost> |
Istnieje moŋliwoķæ masowego konfigurowania vhostów, bez koniecznoķci tworzenia wpisów dla kaŋdego po kolei, sģuŋy do tego moduģ vhost-alias dostarczany wraz z pakietem apache-mod_vhost_alias. Jego opis wykracza poza ramy tego rozdziaģu, więcej na jego temat odnajdziemy w dokumentacji serwera.
Ograniczanie dostępu na podstawie adresu
Czasami chcemy ograniczyæ moŋliwoķæ przeglądania stron dla konkretnych adresów lub klas adresowych. W tym celu uŋyjemy moduģu apache-mod_authz_host, dzięki niemu będziemy mogli chroniæ przed dostępem do wskazanych katalogów. Jeŋeli potrzebujesz chroniæ jedynie jeden lub kilka plików, stwórz w obrębie strony katalog o dowolnej nazwie i umieķæ je w nim. Oczywiķcie musisz pamiętaæ o przekonstruowaniu linków na stronie.
Do konfiguracji Apache dodajemy podobną konstrukcję konstrukcję:
<Directory "/home/users/jan/public_html/intra"> Order allow,deny Allow from 123.45.0.0/255.255.0.0 Allow from 56.67.9.34 </Directory> |
Dostęp do katalogu intra mają wszystkie komputery z
okreķlonej w przykģadzie sieci oraz jeden komputer (bądž urządzenie
udostępniające NAT) o wymienionym adresie. Wszystkie poģączenia nie pasujące
do tych kryteriów traktowane są jako deny, zgodnie z
porządkiem wyznaczonym przez dyrektywę Order.
Ograniczenie dostępu za pomocą loginu i hasģa
Apache udostępnia mechanizm autoryzacji, który uŋywany jest do wyodrębnienia z serwisu pewnej częķci przeznaczonej dla upowaŋnionych uŋytkowników. Ograniczenie dziaģa na poziomie katalogów i podobnie jak w ograniczeniu dla adresu (opisanego powyŋej) nie moŋna w ten sposób chroniæ poszczególnych plików.
Apache wspiera wiele rodzajów žródeģ uwierzytelniających: pliki tekstowe, konta systemowe, bazy LDAP i inne. My będziemy zajmowaæ się autoryzacją za pomocą plików tekstowych, ze względu na popularnoķæ i prostotę tego rozwiązania. Istnieją dwa protokoģy przesyģania hasģa Basic i Digest (w postaci skrótu). Metoda Digest jest bezpieczniejsza jednak praktycznie nie jest obsģugiwana przez przeglądarki WWW, tak więc pozostaje nam uŋywanie metody Basic.
Zaczynamy od instalacji metapakietu apache-mod_auth oraz pakietu htpasswd-apache. Teraz dodajemy do któregoķ z plików konfiguracji reguģkę chroniącą katalog :
<Directory "/home/users/jan/public_html/private">
AuthType Basic
AuthBasicProvider file
AuthName "Witaj Janie, zaloguj sie."
AuthUserFile /home/services/httpd/.htpasswd
Require valid-user
</Directory> |
AuthUserFile wskazuje plik z
loginami i hasģami uŋytkowników, jak widaæ ķcieŋka ta
jest inna niŋ chroniony katalog ze względów bezpieczeņstwa.
Opcja Require okreķla jacy uŋytkownicy
są akceptowani - tutaj kaŋdy autoryzowany.
Teraz tworzymy plik z hasģami, poprzez dodanie pierwszego konta:
# htpasswd -c /home/services/httpd/.htpasswd jan New password: Re-type new password: Adding password for user jan |
# chmod 600 /home/services/httpd/.htpasswd # chown http.http /home/services/httpd/.htpasswd |
Po restarcie kaŋde odwoģanie do katalogu będzie wymagaģo podania loginu jan i hasģa. Istnieje takŋe moŋliwoķæ dodania obsģugi grup - mechanizmu zbliŋonego dziaģaniem do uniksowych grup systemowych.
W wielu wypadkach będziemy chcieli daæ moŋliwoķæ
uŋytkownikom tworzenia plików z hasģami z wraz z
plikami .htaccess w katalogu
okreķlonym przez DocumentRoot. Stanowi
to zagroŋenie bezpieczeņstwa, ze względu na moŋliwoķæ
wyķwietlenia zawartoķci tych plików. Moŋemy się
zabezpieczyæ przed tym instalując pakiet
apache-mod_authz_host,
dzięki któremu m.in. nie zostaną wysģane do przeglądarki
pliki .ht*
Obsģuga skryptów PHP
Ze względu na duŋą funkcjonalnoķæ język PHP staģ się juŋ w zasadzie pewnym standardem w tworzeniu interaktywnych stron internetowych. Wspóģczesne serwisy wykorzystują m. in. bazy danych, dlatego zostanie równieŋ opisane jak taką obsģugę zapewniæ. Przeglądając listę dostępnych do zainstalowania pakietów z PHP na pierwszy rzut oka widaæ nacisk twórców dystrybucji jaki zostaģ naģoŋony na modularnoķæ. Daje to niesamowitą wolnoķæ w wyborze tego co jest Ci dokģadnie potrzebne.
Zaczynamy od instalacji pakietu apache-mod_php, w ten sposób otrzymamy podstawową wersję PHP, dodatkowe pakiety instalujemy wtedy gdy potrzebna nam jest jakaķ funkcjonalnoķæ. Najlepszą metodą sprawdzenia czy PHP dziaģa jest uŋycie funkcji phpinfo(), aby z niej skorzystaæ stwórz plik z zawartoķcią taką jak poniŋej:
<? phpinfo(); ?> |
Obsģuga róŋnego typu systemów bazodanowych rozbita jest na osobne pakiety zawierające definicje funkcji PHP które ją zapewniają. Poniŋej w tabeli znajduje się lista która to odzwierciedla.
Tabela 1. Obsģuga baz danych
| Nazwa pakietu | Baza Danych |
|---|---|
| php-dba | Moduģ dla PHP dodający obsģugę dla baz danych opartych na plikach (DBA). |
| php-dbase | Moduģ PHP ze wsparciem dla DBase. |
| php-filepro | Moduģ PHP dodający moŋliwoķæ dostępu (tylko do odczytu) do baz danych filePro. |
| php-interbase | Moduģ PHP umoŋliwiający dostęp do baz danych InterBase i Firebird. |
| php-mssql | Moduģ PHP dodający obsģugę baz danych MS SQL poprzez bibliotekę FreeTDS. |
| php-mysql | Moduģ PHP umoŋliwiający dostęp do bazy danych MySQL. |
| php-odbc | Moduģ PHP ze wsparciem dla ODBC. |
| php-pgsql | Moduģ PHP umoŋliwiający dostęp do bazy danych PostgreSQL. |
| php-sybase | Moduģ PHP dodający obsģugę baz danych Sybase oraz MS SQL poprzez bibliotekę SYBDB. |
| php-sybase-ct | Moduģ PHP dodający obsģugę baz danych Sybase oraz MS SQL poprzez CT-lib. |
Aby skorzystaæ z którego kolwiek moduģu wystarczy go po prostu zainstalowaæ. Przeprowadzając instalację w trybie wsadowym pamiętaj o zrestartowaniu usģugi apache, o czym zostaniesz przez poldka poinformowany. Dystrybucja nie posiada niestety pakietów do obsģugi bazy danych Oracle. Jeŋeli jest Ci ona potrzebna musisz zbudowaæ PHP wģączając obsģugę oracla z serwera CVS, instalując uprzednio Oracla którego posiadasz.
Warto jeszcze wspomnieæ o narzędziach wspomagających zarządzanie bazami danych. Do obsģugi bazy MySQL sģuŋy pakiet phpMyAdmin natomiast do PostgreSQL zainstaluj phpPgAdmin. Szerzej o tych aplikacjach w dokumentacji do tych systemów.
CGI
Aby nasz Apache obsģugiwaģ programy CGI wystarczy zainstalowaæ pakiet apache-mod_cgi. Po przeģadowaniu demona programy CGI obsģugiwane będa w katalogu /home/services/httpd/cgi-bin, zgodnie z ustawieniami w pliku /etc/httpd/apache.conf.
Ŋeby przetestowaæ CGI wystarczy ŋe utworzymy plik o następującej treķci:
#!/bin/sh echo "Content-type: text/html\n\n" echo "Hello, World." |
Jeķli zechcemy wskazaæ więcej katalogów w których pozwolimy uruchamiaæ
aplikacje CGI (np. dla hostów wirtualnych) wystarczy, ŋe do któregoķ
z plików konfiguracji dodamy odpowiednio skonfigurowaną opcję
ScriptAlias np.:
ScriptAlias /cgi-bin/ "/home/users/jan/cgi-bin/" |
DocumentRoot.
Security Socket Layer (SSL)
Mechanizm ten wykorzystuje się w serwisach wymagających od uŋytkownika autoryzacji. Najbardziej typowymi aplikacjami tego typu są róŋnego rodzaju klienci poczty. SSL zapewnia szyfrowany kanaģ dla informacji przepģywającej od uŋytkownika do serwera. Dzięki temu niemoŋliwe jest podsģuchanie hasģa. UWAGA! Jeden certyfikat SSL moŋe zostaæ przypisany tylko dla jednego adresu IP.
Konfigurację zaczynamy od zainstalowania pakietu apache-mod_ssl. W wyniku instalacji utworzony zostanie plik /etc/httpd/httpd.conf/40_mod_ssl.conf. Zanim zaczniemy go konfigurowaæ naleŋy wygenerowaæ certyfikaty. Sģuŋy do tego polecenie openssl. Program ten znajduje się w pakiecie openssl-tools.
# openssl genrsa -out /etc/httpd/ssl/apache.key 1024 |
W wyniku tego polecenia zostanie utworzony plik apache.key który posģuŋy do tworzenia certyfikatu. Robimy to w następujacy sposób.
# openssl req -new -x509 -days 365 -key /etc/httpd/ssl/apache.key \
-out /etc/httpd/ssl/apache.crt |
Proces tworzenia certyfikatu będzie wymagaģ podania kilku informacji. Zostaniesz o nie poproszony trakcie jego trwania.
Country Name (2 letter code) [AU]:PL State or Province Name (full name) [Some-State]:Województwo Locality Name (eg, city) []:Miasto Organization Name (eg, company) [Internet Widgits Pty Ltd]: Firma Organizational Unit Name (eg, section) []:Web Server Common Name (eg, YOUR name) []:example.net Email Address []:root@example.net |
Pola, które widzisz w powyŋszym przykģadzie naleŋy wypeģniæ
zgodnie z tym jak zostaģo to przedstawione. W przypadku
kiedy serwer jest prywatną wģasnoķcią i nie naleŋy do ŋadnej
firmy, w polu Organization Name moŋesz
wpisaæ imię i nazwisko. Para plików: klucz oraz
certyfikat powinny mieæ takie uprawnienia, aby uŋytkownik
http mógģ je odczytywaæ.
Moŋemy teraz wyedytowaæ plik
/etc/httpd/httpd.conf/40_mod_ssl.conf.
Poķród szeregu opcji interesuje nas w zasadzie tylko
konfiguracja katalogu, do którego poģączenie będzie
szyfrowane oraz ķcieŋki do plików z kluczem oraz
certyfikatem. Musimy odnaležæ początek sekcji o nazwie
VirtualHost.
<VirtualHost _default_:443> DocumentRoot "/home/services/httpd/html/webmail" ServerName mail.example.net:443 ServerAdmin root@example.net ErrorLog /var/log/httpd/error_log TransferLog /var/log/httpd/access_log |
Jak widaæ jej początek nie róŋni się niczym od konfiguracji VirtualHosts.
Zwróæ uwagę na opcję ServerName. Powinna ona koņczyæ się ciągiem
:443 który oznacza port na którym ma nasģuchiwaæ demon. Przechodzimy
dalej i zmieniamy takie opcje jak SSLCertificateFile oraz
SSLCertificateKeyFile.
SSLCertificateFile /etc/httpd/ssl/apache.crt SSLCertificateKeyFile /etc/httpd/ssl/apache.key |
Podajemy tutaj ķcieŋki do plików które wygenerowaliķmy w poprzednim etapie.
Po zapisaniu i zakoņczeniu edycji pliku restartujemy Apache, aby nasze zmiany odniosģy skutek. Aby nawiązaæ poģączenie szyfrowane z webmailem naleŋy w przeglądarce wpisaæ adres https://example.net/webmail. Aby ustanowiæ poģączenie szyfrowane i za kaŋdym razem nie wpisywaæ https://, powinieneķ uŋyæ mechanizmu vhosts. Stwórz katalog /home/services/httpd/html/mail dla którego zrobisz wpis w pliku 20_mod_vhost_alias.conf. Czyli zgodnie z tym czego juŋ się dowiedziaģeķ, robisz wpis w pliku strefy domeny oraz konfigurujesz apache. Natomiast w katalogu /home/services/httpd/html/mail tworzysz plik o nazwie index.php z zawartoķcią taką jak w przykģadzie.
<?php
/**
* index.php -- Displays the main frameset
*
* Copyright (c) 1999-2002 The SquirrelMail Project Team
* Licensed under the GNU GPL. For full terms see the file COPYING.
*
* Redirects to the login page.
*
* $Id: index.php,v 1.13 2002/02/19 15:05:03 philippe_mingo Exp $
*/
header("Location: https://poczta.example.net\n\n");
exit();
?> |
Oczywiķcie domena, która jest podana na listingu musi odnosiæ się do vhosta z opcją
DocumentRoot ustawioną na
/home/services/httpd/html/mail.
Indeksowana zawartoķæ katalogu
Jest to bardzo przydatna funkcja, pozwalająca w ģatwy sposób udostępniæ zawartoķæ katalogu na serwerze. Aby umoŋliwiæ indeksowanie musimy zainstalowaæ moduģ apache-mod_autoindex.
poldek -i apache-mod_autoindex |
Indexes.
W domyķlnej konfiguracji, Apache ma wģączone indeksy
dla wszystkich podkatalogów wewnątrz /home/services/httpd/html
(w pliku 10_common.conf). Jeķli
ustawiliķmy inaczej to musimy wģączaæ tą opcję dla
kaŋdego z katalogów osobno np.:
<Directory /home/services/httpd/html/katalog> Options Indexes </Directory> |
DirectoryIndex.
Uwagi
Po kaŋdej zmianie konfiguracji w katalogu /etc/httpd/httpd.conf konieczne jest przeģadowanie demona, aby na nowo odczytaģ swoje pliki konfiguracji. Moŋemy uŋyæ w tym celu odpowiedniego wywoģania rc-skryptu:
# service httpd restart |
# apachectl configtest Syntax OK |
Na szczególną uwagę zasģugują parametry rc-skryptu: reload|force-reload|graceful np.:
# service httpd reload |
BIND - Serwer Nazw
DNS - Domain Name System
DNS jest systemem hierarchicznym. Na samym szczycie owej hierarchii stoją tzw. TLD (Top Level Domains), czyli domeny najwyŋszego rzędu. Zaliczają się do nich takie domeny jak .com (komercyjne), .pl (krajowe), .net (sieci) i inne. Są to domeny powstaģe na podstawie odpowiednich postanowieņ, opisane w specjalnych dokumentach. Kaŋda z wymienionych (lub teŋ nie wymienionych) tutaj TLD's posiada swoje subdomeny, np. pld-linux.org. Z kolei kaŋda powstaģa w wyniku rejestracji danej nazwy domena moŋe mieæ swoje poddomeny, np. www.pld-linux.org. W ten sposób moŋna tworzyæ bardzo zagęszczone hierarchie w obrębie danej domeny. Niniejszy rozdziaģ dotyczy implementacji Bind okreķlanego czasem jako named - jednego z najpopularniejszych serwerów DNS.
Kaŋda domena (zwana równieŋ strefą) musi mieæ co najmniej dwa serwery DNS, jest to wymóg registrarów, czyli instytucji oferujących moŋliwoķæ rejestracji domen. Jeden z serwerów okreķla się jako podstawowy (równieŋ master lub primary) a drugi jako zapasowy (slave lub secondary).
Wstęp
Bind w PLD dziala w ķrodowisku chroot, w katalogu /var/lib/named, musimy o tym pamiętaæ, przy niektórych operacjach diagnostycznych. Gģównym plikiem konfiguracyjnym jest /etc/named.conf, który jest symlinkiem do /var/lib/named/etc/named.conf. Struktura katalogu /var/lib/named wygląda następująco:
dev/ etc/ M/ S/ named.pid root.hint |
Dodawanie stref DNS polega na definiowaniu obsģugiwanych domen w pliku /etc/named.conf, oraz tworzenia plików konfiguracji stref.
Podstawowa konfiguracja
Gģównym plikiem konfiguracyjnym serwera Bind jest /etc/named.conf. Znajdują się w nim podstawowe opcje usģugi oraz informacje na temat obsģugiwanych stref. Poniŋej zamieszczono domyķlne wpisy, które znajdują się w tym pliku
options {
directory "/";
pid-file "named.pid";
auth-nxdomain yes;
datasize default;
};
zone "localhost" IN {
type master;
file "M/localhost.zone";
allow-update { none; };
allow-transfer { any; };
};
zone "0.0.127.in-addr.arpa" IN {
type master;
file "M/127.0.0.zone";
allow-update { none; };
allow-transfer { any; };
};
zone "." IN {
type hint;
file "root.hint";
}; |
Na samym początku pliku konfiguracyjnego znajduje się sekcja options.
Najbardziej istotną opcją jest tutaj directory. Wskazuje ona na
gģówny katalog przechowywania plików stref. Byæ moŋe zdziwi Cię nieco parametr
powyŋszej opcji. Jak juŋ wczeķniej wspominaģem Bind w PLD posiada wģasne
chrootowane ķrodowisko, dlatego moŋna taki zapis zastosowaæ.
Zanim przejdę do omawiania pozostaģych wpisów, naleŋy się jeszcze sģowo wyjaķnienia na temat konstrukcji samego pliku. Na pierwszy rzut oka poszczególne wpisy są podzielone na sekcje. Te z kolei ograniczone są klamrami. Znak ; równieŋ peģni tutaj rolę ogranicznika dla poszczególnych opcji jak i caģych sekcji ujętych w klamry. Warto o tym wiedzieæ ze względu na ewentualne szukanie bģędów powstaģych na skutek edycji tego pliku.
Poniŋej mamy zdefiniowane trzy sekcje stref zaczynających się sģowem kluczowym
zone. W powyŋszym przykģadzie przedstawione są wpisy okreķlające
localhosta. Są one typu master. Plik strefy w kaŋdej z nich wskazany jest opcją
file. Strefa nie musi byæ aktualizowana, ani synchronizowana z
serwerem slave, więc dwie pozostaģe opcje mają parametr none oraz
any. Ostatnia strefa sģuŋy do komunikacji naszego binda z Root serwerami
o których byģa mowa we wstępie. Bez tej strefy nie mógģby on wyszukiwaæ nazw w internecie.
Mówiąc w przenoķni byģby ķlepy.
Kaŋdorazowe odpytywanie Root Servers moŋe się okazaæ maģo
wydajne, ze względu na duŋe czasy odpowiedzi. Dlatego, jeŋeli chcemy przyspieszyæ ten proces
powinniķmy sekcję option zmodyfikowaæ o wpis taki jak poniŋej
options {
forwarders { 194.204.159.1; 194.204.152.34; };
} |
Oczywiķcie nie musimy posģugiwaæ się takimi adresami jak w przykģadzie. Moŋemy sobie wybraæ takie serwery DNS, które będą nam odpowiadaģy najszybciej np. serwery naszego ISP.
W PLD zaleca się, aby wszystkie pliki stref w zaleŋnoķci od typu domeny byģy przechowywane w katalogach /var/lib/named/M oraz /var/lib/named/S. Tak naprawdę o ķcieŋce do tych katalogów decydują wpisy w named.conf. Struktura plików stref dla obu typów domen jest taka sama.
Przykģadowa konfiguracja strefy typu primary
Zaczniemy od konfiguracji /etc/named.conf, budowa tego pliku byģa wyjaķniona w poprzedniej częķci tego rozdziaģu. Poniŋej zostaģ zamieszczony przykģadowy wpis dla strefy na serwerze podstawowym:
zone "example.net" {
type master;
file "M/example.net";
allow-transfer { 123.45.67.89; };
notify yes;
}; |
Poszczególne opcje tej sekcji zostaģy omówione juŋ na początku tego rozdziaģu. Podsumujmy więc dostępne informacje skupiając się na powyŋszym przykģadzie:
zone "example.net"- nazwa strefytype master- rodzaj serwerafile "M/example.net"- nazwa pliku z konfiguracją strefyallow-transfer { 123.45.67.89; }- adres serwera, który ma moŋliwoķæ transferu caģej strefy, Jeŋeli posiadasz więcej niŋ jeden taki DNS, moŋesz je wpisaæ pomiędzy klamry pamiętając o tym, aby rozdzieliæ poszczególne adresy IP, znakiem ';'.notify yes- opcja ta wģącza powiadamianie zapasowego serwera DNS o zmianach w naszej domenie.
Musimy teraz utworzyæ plik strefy dla domeny example.net
wskazany przez opcję file. Poniŋej zamieszczam treķæ przykģadowego pliku strefy:
$TTL 86400
$ORIGIN example.net.
@ IN SOA ns1.example.net. root.example.net. (
2004022300 ;; serial
1200 ;; refresh
1200 ;; retry
2419200 ;; expire
86400 ;; TTL
)
@ IN NS ns1.example.net.
@ IN NS ns2.example.net.
@ IN MX 10 mail.example.net.
@ IN A 123.45.67.8
ns1 IN A 123.45.67.8
ns2 IN A 90.12.34.237
mail IN A 123.45.67.8
www IN A 34.5.6.78
ftp IN CNAME www |
Plik strefy moŋna podzieliæ na trzy odrębne sekcje. Pierwsza okreķla nazwę domeny oraz okres waŋnoķci wpisów. Druga, kto tą domeną zarządza. W trzeciej znajduje się caģa jej zawartoķæ. Bardziej szczegóģowy opis znajduje się w poniŋszym wykazie. Kilka zdaņ o wyraŋeniach stosowanych w plikach stref. Warto o nich pamiętaæ. Wszystkie wpisy poprzedzone ;; będą ignorowane i traktowane jak komentarz. Kolejnym waŋnym znakiem jest znak kropki. Jego znaczenie omówię poniŋej w przykģadzie.
@ IN NS ns1.example.net. |
Jeŋeli w powyŋszym wpisie pominęlibyķmy koņcowy znak kropki, wówczas Bind dokleiģby na koņcu nazwę domeny. Wówczas z ns1.example.net zrobiģby się wpis ns1.example.net.example.net, co oczywiķcie nie jest poŋądane. następnym znakiem specjalnym na który warto zwróciæ uwagę jest @. Otóŋ moŋna go potraktowaæ jako pewnego rodzaju zmienną, która przechowuje nazwę example.net. Jednym sģowem, example.net i @ to to samo.
$TTL 86400- czas waŋnoķci rekordów w domenie wyraŋony w sekundach; 86400 s. to jedna doba$ORIGIN example.net.- domena jaką będzie opisywaģ bieŋący plik strefy.@ IN SOA ns1.example.net. root.example.net.- Rekord typu SOA czyli Start Of Authority. Moŋemy się z niego dowiedzieæ, kto zarządza domeną (root@example.net), jaki jest adres serwera primary DNS. Zwróæ uwagę, ŋe w adresie root@example.net zamiast znaku @ uŋyta zostaģa kropka. Rekord SOA posiada swoją wģasną strukturę o której poniŋej. Zawarta jest ona pomiędzy znakami ( ).2004022300 ;; serial- numer seryjny domeny. Powinien on byæ zwiększany wraz z kaŋdą jej modyfikacją. W dobrym tonie jest utrzymywanie go w formacie YYYYMMDDnn czyli rok, miesiąc, dzieņ oraz numer modyfikacji w danym dniu.1200 ;; refresh- To pole rekordu SOA definiuje jak często serwery slave mają sprawdzaæ czy dane o domenie nie zmieniģy się na masterze. Wedģug RFC 1035 wartoķæ ta powinna się zawieraæ pomiędzy 1200 a 43200 (czyli od dwudziestu minut do dwunastu godzin). W praktyce najlepsza wartoķæ zawiera się między 3600 a 7200 sekund.1200 ;; retry- Czas po jakim secondary ma ponowiæ próbę kontaktu z masterem, gdy taka się nie powiedzie. Zalecana wartoķæ pomiędzy 120 a 7200 sekund.2419200 ;; expire- Ta wartoķæ okreķla czas po jakim dane domeny mają zostaæ uznane za nieaktualne gdy serwer secondary nie będzie mógģ się skontaktowaæ z primary. Zalecana wartoķæ zawiera się pomiędzy 1209600 a 2419200 sekund, czyli od dwóch do czterech tygodni.86400 ;; TTL- Time To Live. Okreķla ile czasu informacja o danym rekordzie ma byæ waŋna. Jest to okres przez jaki informacja o naszej domenie będzie przechowywana przez serwer DNS, który ją pobraģ. Zalecana wartoķæ zawiera się między 86400 a 432000 sekund, czyli przez okres od jednego do pięciu dni.
Bezpoķrednio pod rekordem SOA definiujemy, które serwery DNS będą obsģugiwaģy naszą domenę.
Jeszcze raz przypominam aby wģaķciwie zamknąæ ten rekord. Bez tego nasza domena nie będzie dziaģaæ.
Do definiowania serwerów DNS sģuŋą wpisy typu IN NS.
@ IN NS ns1.example.net. @ IN NS ns2.example.net. |
Powyŋszy wpis mówi, ŋe domenę example.net obsģuguje serwer DNS ns1.example.net oraz ns2.example.net. Jeŋeli obie nazwy dotyczą komputerów, które wczeķniej nie peģniģy roli serwerów DNS, powienieķ dodaæ wpisy takie jak poniŋej.
ns1 IN A 123.45.67.8 ns2 IN A 90.12.34.237 |
ns1 oczywiķcie moŋe wskazywaæ na adres serwera DNS który zapewne
konfigurujesz; ns2 powinien wskazywaæ na Twojego
secondary. Zrobiliķmy to posģugując się wpisami typu
IN A. Jak zapewne pamiętasz, brak koņcowej kropki powoduje doklejenie
do wpisanej nazwy tego co znajduje się w zmiennej $ORIGIN. Moŋemy więc
uznaæ to co widzisz w powyŋszym przykģadzie za postaæ skróconą poniŋszego wpisu.
ns1.example.net. IN A 123.45.67.8 ns2.example.net. IN A 90.12.34.237 |
Wpisy typu IN A sģuŋą do okreķlania, ŋe wģaķnie ten adres IP ma przypisaną
taką a nie inną nazwę. Oczywiķcie do jednego adresu IP moŋesz stworzyæ kilka takich wpisów.
Jeŋeli posiadasz serwer poczty, powinieneķ zrobiæ wpis mówiący o tym, ŋe będzie on obsģugiwaģ
pocztę dla domeny example.net.
@ IN MX 10 mail.example.net |
Dokģadnie tak jak wczeķniej wspomniaģem, poczta, dla domeny example.net
kierowana jest do serwera mail.example.net o priorytecie 10. Jest on
tzw. MX'em. Rekord typu IN MX sģuŋy wģaķnie do definiowania w DNS serwera
poczty. Priorytet przydaje się wtedy, kiedy posiadasz kilka serwerów poczty w swojej domenie.
Sģuŋy on do ustalenia porządku; do którego serwera poczta ma trafiæ w pierwszej kolejnoķci.
Mniejszy priorytet zapewnia pierwszeņstwo.
Pozostaģe wpisy dotyczą takich standardowych usģug jak www czy ftp. Umieszczanie ich w pliku strefy nie jest obowiązkowe. Jednak domenę rejestruje się zazwyczaj na potrzeby www, ftp czy poczty, dlatego zostaģy one wymienione w przykģadzie.
ftp IN CNAME www |
Powyŋej umieszczono przykģad rekordu typu IN CNAME, tworzy on dodatkową subdomenę
dla hosta przypisanego juŋ do innej nazwy. Specjaliķci radzą by tego rodzaju rekordy
wskazywaģy wyģącznie na rekordy typu IN A.
Po zakoņczeniu konfiguracji musimy jeszcze uruchomiæ usģugę.
# /etc/rc.d/init.d/named start |
Przykģadowa konfiguracja strefy typu secondary
Konfiguracja serwera secondary sprowadza się do dokonania poniŋszego wpisu w pliku /etc/named.conf.
zone "example.net" IN {
type slave;
file "S/example.net";
masters { 123.45.67.8; };
}; |
Jak widaæ wpis wygląda podobnie jak w przypadku serwera primary. Opcja
type tym razem ma wartoķæ slave. Musimy teŋ wskazaæ
serwer primary. Robimy to uŋywając opcji masters, której
wartoķæ zawiera adres serwera primary DNS.
Obsģuga protokoģu IPv6
Podobnie jak większoķæ usģug w dystrybucji BIND posiada wsparcie dla protokoģu
IPv6 (IPng). Oczywiķcie wczeķniej komputer musi byæ podģączony do tej sieci.
W tej częķci rozdziaģu zostanie omówiona konfiguracja dla stref
IN A oraz strefy odwrotnej. Narzędziem wspomagającym
konfigurację będzie ipv6calc znajdujący się w pakiecie
o tej samej nazwie. Jak sama nazwa wskazuje jest to kalkulator adresów
IPv6.
IN AAAAOdpowiednikiem w IPv6 strefy
IN Ajest wpisIN AAAA. Kaŋda z dotychczasowych stref stworzona do tej pory dla protokoģu IPv4 moŋe mieæ swój odpowiednik w sieci IPv6. Moŋemy równieŋ stworzyæ zupeģnie nowe wpisy, które będą widoczne jedynie w tej sieci.moja IN AAAA 3ffe:1a:2b:3c::1
Umieszczenie powyŋszego wpisu w pliku strefy /var/lib/named/M/example.net spowoduje przypisanie nazwy moja.example.net adresowi 3ffe:1a:2b:3c::1. Aby wpis zacząģ obowiązywaæ naleŋy zrestartowaæ usģugę.
IN PTRKonfigurację strefy odwrotnej zaczniemy od stworzenia odpowiedniego wpisu w pliku /etc/named.conf. Jak sama nazwa wskazuje będzie on przypominaģ lustrzane odbicie adresu w zwykģej postaci. Aby mieæ pewnoķæ, ŋe nasza strefa będzie poprawnie zapisana posģuŋymy się wspomnianym we wstępie narzędziem ipv6calc.
$ ipv6calc -r 3ffe:1a:2b:3c::/64 No input type specified, try autodetection...found type: ipv6addr c.3.0.0.b.2.0.0.a.1.0.0.e.f.f.3.ip6.int.
Uzyskaliķmy w ten sposób informacje, ŋe dla sieci o adresie 3ffe:1a:2b:3c::/64, strefa odwrotna posiada postaæ taką jak na powyŋszym listingu. Wystarczy teraz to zapisaæ w pliku konfiguracyjnym BIND'a.
zone "c.3.0.0.b.2.0.0.a.1.0.0.e.f.f.3.ip6.int" IN { type master; file "M/ipv6"; allow-transfer { 90.12.34.237; }; };Jak widaæ na pierwszy rzut oka, konfiguracja niczym się praktycznie nie róŋni od konfiguracji strefy dla IPv4. Jako nazwę strefy podaliķmy to co nam zwróciģ ipv6calc. Przyjrzyjmy się teraz jak powinien wyglądaæ plik dla tej strefy wskazany dyrektywą
file.$TTL 86400 $ORIGIN 0.1.0.0.e.2.0.0.c.0.0.4.e.f.f.3.ip6.int.
Pierwszy parametr to omawiany juŋ wczeķniej okres waŋnoķci rekordów. Jak widaæ na listingu wynosi on jeden dzieņ. Drugi z nich to de facto nazwa tej strefy. Sama opcja
$ORIGINto swojego rodzaju zmienna, której wartoķæ jest podstawiana w miejsce @ oraz doklejana do tych nazw które nie posiadają na koņcu specjalnego znaku kropki.@ IN SOA ns1.example.net. root.example.net. ( 2004050600 3H 15M 1W 1D )Jak widaæ rekord
IN SOAnie róŋni się niczym od tego dla domeny IPv4.@ IN NS ns1.example.net. @ IN NS ns2.example.net.
Okreķlamy które serwery przechowują naszą domenę odwrotną. Równieŋ tutaj wszystko wygląda identycznie jak dla protokoģu IPv4. Moŋemy teraz przystąpiæ do konfigurowania strefy odwrotnej.
1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0 IN PTR moja.example.net.
Dlaczego tyle zer? Odpowiedž na to znajdziesz obliczając przy uŋyciu programu ipv6calc adres odwrotny dla 3ffe:1a:2b:3c::1. Robimy to w sposób identyczny do poprzedniego przykģadu jego uŋycia. W wyniku obliczeņ będzie on wyglądaģ tak: 1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.c.3.0.0.b.2.0.0.a.1.0.0.e.f.f.3. Jak ģatwo zauwaŋyæ, po ostatnim zerze w listingu nie postawiliķmy kropki, a więc zostanie doklejona po nim zawartoķæ
$ORIGIN.Narzędziem pomocnym w odpytywaniu serwerów DNS, jest program host. Moŋna nim równieŋ odpytywaæ o nazwy skonfigurowane dla protokoģu IPv6. Jak by wyglądaģo zapytanie o nazwę moja.example.net?
$ host -n -i 3ffe:1a:2b:3c::1 1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.c.3.0.0.b.2.0.0.a.1.0.0.e.f.f.3.\ ip6.int domain name pointer moja.example.netPrzeģącznik
-noznacza, ŋe będziemy odpytywali strefę odwrotną, natomiast-i, ŋe jest to adres typu int. Domyķlnie host szuka nazw typu arpa.
Rejestracja
Zanim zarejestrujemy domenę musimy mieæ skonfigurowany podstawowy i zapasowy serwer nazw. Mamy moŋliwoķæ zarejestrowania wģasnej domeny, bądž skorzystaæ z usģug darmowego oddelegowania nam subdomeny zarejestrowanej juŋ domeny. Ceny rejestracji domen spadģy w ostatnich latach tak bardzo, ŋe uŋywanie "obcej" domeny staģo się maģo profesjonalne i warto zarejestrowaæ wģasną.
Jeŋeli nie posiadasz serwera secondary, moŋesz poszukaæ firmy lub organizacji, która za darmo utrzymuje zapasowe DNS-y. Moŋemy teŋ umówiæ się z administratorem innej firmy na wzajemne prowadzenie serwerów secondary.
Diagnostyka
Jeķli chcemy przetestowaæ poprawnoķæ skģadni pliku strefy, powinniķmy skorzystaæ z narzędzia named-checkzone. Program sprawdzi poprawnoķæ pliku strefy i poda w której linii wystąpiģ bģąd np.:
# /usr/sbin/named-checkzone example.net /var/lib/named/M/example.net |
Named generuje logi typu daemon, domyķlnie syslogd umieszcza takie wpisy w pliku /var/log/daemon. Jeķli jednak nastąpiģ problem z uruchomieniem demona, uniemoŋliwiający mu pisanie do logów, to moŋemy sprawdziæ co się dzieje uruchamiając go bez przejķcia w tģo i z wypisaniem komunikatów na standardowe wyjķcie:
/usr/sbin/named -g -t /var/lib/named |
Aby ostatecznie sprawdziæ poprawnoķæ konfiguracji moŋemy odpytaæ nasz serwer za pomocą protokoģu DNS. Uŋyjemy do tego programu host z pakietu bind-utils np.:
# /usr/sbin/host -t mx example.net |
Zakoņczenie
Uwaga! Named nie powinien byæ resolwerem nazw dla maszyny na której pracuje, powinien nim byæ inny serwer DNS aby nie powstawaģy zapętlenia zapytaņ. Wyjątek stanowią usģugi pracujące w osobnych ķrodowiskach chroot/vserver. Więcej o konfiguracji resolwera nazw znajdziemy w sekcja Podstawowa konfiguracja sieci w rozdziaģ Interfejsy sieciowe.
CRON - Cykliczne wykonywanie zadaņ
CRON jest waŋnym demonem systemowym, którego zadaniem jest uruchamianie programów cyklicznie lub o okreķlonej porze. Omówiona zostanie instalacja vixie-cron, który oprócz standardowych usģug posiada dodatkowe opcje konfiguracyjne i zwiększone bezpieczeņstwo
Instalacja
Program instalujemy za pomocą poldka:
# poldek -i vixie-cron |
# /etc/rc.d/init.d/crond start |
Budowa tabel
W cronie istnieje podziaģ na zadania systemowe i zadania uŋytkowników. Pierwszych zwykle uŋywa się do prac administracyjnych, z drugich korzystają uŋytkownicy wedle wģasnych potrzeb (o ile mają do tego prawo). Gģówna konfiguracja demona (systemowa) umieszczona jest w pliku /etc/cron.d/crontab, konfiguracje lokalne uŋytkowników przechowywane są w plikach /var/spool/cron/{$login}. O ile /etc/cron.d/crontab moŋe byæ swobodnie modyfikowany za pomocą edytora tekstu, o tyle uŋytkownicy powinni uŋywaæ w tym celu odpowiedniego narzędzia (opisanego w dalszej częķci).
Pliki konfiguracji crona nazywane są tabelami, zarówno gģówny plik konfiguracji jak i konfiguracje uŋytkowników mają bardzo podobną budowę. Są to pliki tekstowe o ķciķle ustalonej skģadni, w których jeden wiersz odpowiada jednemu zadaniu. Wiersz tabeli systemowej ma następującą skģadnię:
{$data-czas} {$uŋytkownik} {$zadanie}
Nieco prostszą budowę mają tabele uŋytkowników:
{$data-czas} {$zadanie}
Pierwsze pole okreķla jak często wykonywane jest zadanie, pole {$uŋytkownik} występuje jedynie w konfiguracji globalnej (w /etc/cron.d/crontab) i wskazuje z jakimi prawami uruchamiane ma byæ zadanie. Trzecie pole to operacja która ma byæ wykonywana. W tabelach uŋytkowników nie podaje się nazwy uŋytkownika, gdyŋ polecenia tam zawarte są automatycznie wykonywane z prawami ich wģaķciciela.
Przykģadowe zadania w /etc/cron.d/crontab:
02 01 * * * root find /home -size +100M > /root/duze_pliki.txt |
30 * * * * backup.sh |
W tabelach oprócz zadaņ moŋemy definiowaæ zmienne ķrodowiskowe np.:
SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=jakis_user NICE=15 |
Format daty i czasu
Sekcja {$uŋytkownik} i {$zadanie} nie wymagają komentarza więc opisane zostanie jedynie pole {$data-czas}. Pole to skģada się z pięciu kolumn:
1-sza kolumna (zakres 0-59) oznacza minuty.
2-ga kolumna (zakres 0-23) oznacza godzinę.
3-cia kolumna (zakres 0-31) oznacza dzieņ miesiąca.
4-ta kolumna (zakres 0-12) oznacza miesiąc. (0 i 1 to styczeņ)
5-ta kolumna (zakres 0-7) oznacza dzieņ tygodnia (0 i 7 to niedziela)
6-ta kolumna okreķla komendę jaka powinna zostaæ wykonana dla danego wiersza.
Gwiazdka "*" oznacza caģy zakres z moŋliwego przedziaģu. Same zakresy w pierwszych pięciu kolumnach mogą byæ reprezentowane w róŋny sposób. Więcej szczegóģów na ten temat dowiemy się wywoģując polecenie man 5 crontab
Program vixie-cron posiada takŋe maģo udokumentowany format wykonywania poleceņ
Nazwa Dziaģanie ------ ------- @reboot Uruchom jeden raz przy starcie systemu @yearly Uruchom jeden raz w roku, "0 0 1 1 *" @annually To samo co @yearly @monthly Uruchom jeden raz w miesiącu, "0 0 1 * *" @weekly Uruchom jeden raz w tygodniu, "0 0 * * 0" @daily Uruchom jeden raz dziennie, "0 0 * * *" @midnight To samo co @daily @hourly Uruchom raz na godzinę, "0 * * * *" Przykģad: @reboot /usr/bin/rdate -s ntp.task.gda.pl |
Tabele systemowe
Gģówną konfigurację systemu tworzymy za pomocą naszego ulubionego edytora tekstu, poprzez modyfikację pliku /etc/cron.d/crontab. Jego zawartoķæ będzie podobna do poniŋej przedstawionego przykģadu:
SHELL=/bin/sh PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=admin@foobar.foo NICE=15 # run-parts 01 * * * * root /bin/run-parts /etc/cron.hourly 02 1 * * * root /bin/run-parts /etc/cron.daily 02 2 * * 0 root /bin/run-parts /etc/cron.weekly 02 3 1 * * root /bin/run-parts /etc/cron.monthly 0-59/10 * * * * root /bin/run-parts /etc/cron.10min 15 18 * * 1-5 root /bin/run-parts /etc/cron.gielda |
Poniŋej napisu # run-parts umieszczone są konfiguracje zadaņ, pierwsze cztery linijki stanowią domyķlną konfigurację demona. Program run-parts sģuŋy do uruchamiania o jednej porze wszystkich programów we wskazanym katalogu. Dzięki takim opcjom moŋemy dodawaæ programy lub skrypty do odpowiednich katalogów bez koniecznoķci pisania reguģek cron-a. Poniŋej umieszczono opisy powyŋszych przykģadów:
Wykonanie poleceņ zawartych w pliku (plikach) katalogu /etc/cron.hourly codziennie, co godzinę - zaczynając od peģnej pierwszej minuty (np. 02:01, 03:01 itd.):
01 * * * * /bin/run-parts /etc/cron.hourly |
Wykonanie poleceņ zawartch w pliku (plikach) katalogu /etc/cron.daily raz dzienie (o godz. 01:02):
02 1 * * * /bin/run-parts /etc/cron.daily |
Wykonanie poleceņ zawartych w pliku (plikach) katalogu /etc/cron.weekly raz w tygodniu (w niedziele o godz. 02:02):
02 2 * * 0 /bin/run-parts /etc/cron.weekly |
Wykonanie poleceņ zawartych w pliku (plikach) katalogu /etc/cron.monthly raz na miesiąc (w pierwszy dzieņ miesiąca o godz. 03:02):
02 3 1 * * /bin/run-parts /etc/cron.monthly |
Wykonanie poleceņ zawartych w pliku (plikach) katalogu /etc/cron.gielda raz dziennie w dni robocze (od poniedziaģku do piątku o godz. 18:15):
15 18 * * 1-5 /bin/run-parts /etc/cron.gielda |
Wykonanie poleceņ zawartych w pliku (plikach) katalogu /etc/cron.10min co 10 minut (kaŋdego dnia, zaczynając od peģnej godziny - czyli np. 01:00, 01:10, 01:20 itd.):
0-59/10 * * * * /bin/run-parts /etc/cron.10min |
Tabele uŋytkowników
Domyķlnie uŋytkownicy nie mogą tworzyæ wģasnych zadaņ cron-a, aby im na to zezwoliæ kaŋdy nich musi zostaæ dopisany do pliku /etc/cron/cron.allow.
Uŋytkownicy powinni uŋywaæ narzędzia crontab, program ten pozwala na bardzo ģatwe zarządzanie tabelą uŋytkownika. Przyjmuje parametry okreķlające rodzaj dziaģania, które ma byæ wykonane na tabeli. Polecenie crontab -l wyķwietla listę zdefiniowanych zadaņ, wywoģanie crontab -e otworzy plik konfiguracji do edycji, zaķ crontab -r usunie caģą zawartoķæ konfiguracji uŋytkownika.
Wybranie opcji edycji tabeli spowoduje otworzenie edytora tekstu okreķlonego zmienną ķrodowiskową EDITOR, po skoņczonej edycji plik zostanie automatycznie poddany kontroli poprawnoķci i zapisany jako /var/spool/cron/{$login}. Najczęķciej popeģniane bģędy przez uŋytkowników to zģy format daty/czasu lub brak znaku nowej linii po ostatnim wierszu.
Root ma dodatkowo do dyspozycji moŋliwoķæ zarządzania zadaniami dowolnego uŋytkownika, w tym celu stosuje się opcję -u z podaną nazwą uŋytkownika.
Komunikaty cron-a
Cron rejestruje wszystkie swoje prace do pliku /var/log/cron za poķrednictwem demona syslogd, dodatkowo moŋna wskazaæ adres e-mail, na który mają docieraæ informacje o wystąpieniu bģędów w wykonywaniu zadaņ. Jeķli nie zdefiniuje zmiennej MAILTO w tabeli to poczta zostanie wysģana na lokalne konto wģaķciciela tej tabeli. Poczta elektroniczna jest jedyną formą informowania zwykģych uŋytkowników o ewentualnych bģędach zadaņ, gdyŋ nie mają oni dostępu do logów.
Wysyģanie poczty elektronicznej zarówno do uŋytkowników lokalnych jak i zewnętrznych będzie wymagaģo instalacji lokalnego serwera poczty MTA. Moŋe to byæ niemal dowolny demon pocztowy, np.: Exim (opis w sekcja Exim - Transport poczty elektronicznej (MTA)) lub Postfix (opis w sekcja Postfix - Transport poczty elektronicznej (MTA)).
Aby ģatwiej byģo analizowaæ problemy, do wiadomoķci wysyģanej przez demon, dodawane są nagģówki X-Cron-Env, zawierające dane ķrodowiska np.:
X-Cron-Env: <SHELL=/bin/sh> X-Cron-Env: <PATH=/sbin:/bin:/usr/sbin:/usr/bin> X-Cron-Env: <MAILTO=root> X-Cron-Env: <NICE=15> X-Cron-Env: <HOME=/root> X-Cron-Env: <LOGNAME=root> X-Cron-Env: <USER=root> |
CUPS - Popularny system druku dla Uniksa
Wstęp
CUPS jest nowoczesnym i uniwersalnym systemem druku dla systemów uniksowych. Moŋe byæ stosowany zarówno do drukowania lokalnego jak i do drukowania w sieci - obsģuguje domyķlnie protokóģ IPP. Po poprawnym skonfigurowaniu urządzenia będziemy mogli drukowaæ z niemal kaŋdego programu, CUPS akceptuje wywoģania poleceņ drukowania w stylu klasycznego systemu LPD.
System CUPS moŋe byæ zarówno serwerem jak i klientem, o tym jaką funkcję będzie peģniæ zainstalowane "urządzenie" decyduje wybór specjalnego sterownika interfejsu: backendu(poza IPP) i konfiguracji.
Instalacja
Podstawowa częķæ CUPS:
$ poldek -i cups cups-clients |
Następnie instalujemy jeden lub więcej kontrolerów interfejsów drukarki (protokóģ IPP nie wymaga backendu):
cups-backend-parallel - port równolegģy (parallel port)
cups-backend-serial - port szeregowy RS-232 (serial port)
cups-backend-usb - port szeregowy USB (usb printer)
cups-backend-smb - drukowanie zdalne w sieci SMB
W przypadku drukarek nie obsģugujących PostScriptu konieczne będą dodatkowe pakiety:
$ poldek -i cups-filter-pstoraster ghostscript-esp |
Do zdalnej administracji (za pomocą HTTPS), konieczny będzie program openssl:
$ poldek -i openssl-tools |
Czas uruchomiæ demona:
$ /etc/rc.d/init.d/cups start |
Zarządzanie drukarkami
Operacje takie jak dodawanie, czy konfigurowanie drukarek mogą byæ dokonywane na kilka sposobów:
HTTP
Popularnym sposobem jest konfiguracja przy pomocy przeglądarki internetowej, CUPS posiada wbudowany niewielki serwer WWW, z którym ģączymy się dowolną przeglądarką na adres serwera i port 631 np.:
$ lynx localhost:631
Z poziomu tej strony mamy dostęp do wielu opcji administracyjnych: konfiguracji drukarek, zarządzania klasami, zadaniami druku i innymi. Ten sposób zarządzania systemem CUPS w niniejszej publikacji jest traktowany jako domyķlny.
lpadmin
lpadmin jest programem administracyjnym dostarczanym z CUPS-em, obsģugiwany jest caģkowicie z linii wiersza poleceņ. Jest to narzędzie zaawansowane, przez co stosunkowo trudne w obsģudze, jego dokģadny opis zawarto w dokumentacji.
Inne
Dla CUPS powstaģy wygodne programy zarządzające przeznaczone dziaģające w ķrodowiskach GNOME i KDE. Szczególnie pozytywnie przedstawia się system-config-printer - wygodna aplikacja, której ukģad opcji przypomina konfigurację przez WWW.
Dodanie drukarki
W tym rozdziale przedstawiono ogólny opis instalacji urządzenia, szczegóģowe informacje umieszczono w rozdziaģach: Szczegóģy dodawania drukarki lokalnej i Szczegóģy dodawania drukarki zdalnej.
Moŋemy uŋyæ programu system-config-printer lub narzędzia dostępnego przez stronę WWW:
$ lynx localhost:631 |
Okreķlamy nazwę drukarki oraz opcjonalnie komentarz i lokalizację, następnie wybieramy jeden z dostępnych na liķcie kontrolerów interfejsów drukarki (backend). Na koniec wybieramy producenta i model drukarki.
System CUPS jest dostarczany z niewielką iloķcią sterowników drukarek, jednak nie naleŋy się jednak martwiæ jeķli na liķcie nie odnajdziemy szukanego urządzenia. Coraz więcej producentów dostarcza ze sprzętem pliki PPD (w CUPS są uŋywane równieŋ dla drukarek niepostcriptowych), moŋemy takŋe skorzystaæ z bazy Foomatic zawierającej ogromną liczbę sterowników.
Sterowniki Foomatic moŋemy zainstalowaæ w postaci zbiorczego pakietu sterowników danego producenta. Przykģadowo jeķli chcemy zainstalowaæ sterowniki drukarek firmy Samsung to instalujemy pakiet cups-foomatic-db-Samsung. Moŋemy równieŋ pobraæ pojedyncze pliki PPD z z witryny http://www.linuxprinting.org, po wyszukaniu modelu drukarki (Driver Listings) naleŋy kliknąæ link download PPD w celu pobrania sterownika. Plik wskazujemy przy dodawaniu drukarki lub kopiujemy go do katalogu /usr/share/cups/model i uruchamiamy na nowo demona cupsd:
# /etc/rc.d/init.d/cups restart |
Po tej operacji przeprowadzamy normalną instalację drukarki. Moŋemy ich wiele zainstalowaæ, to do której będą trafiaæ dokumenty zaleŋy od tego, którą z nich ustawimy jako domyķlną.
Szczegóģy dodawania drukarki lokalnej
Dodanie drukarki lokalnej dotyczy drukarek podģączonych bezpoķrednio podģączonych do komputera, na którym zainstalowany jest CUPS, w tym wypadku interesują nas interfejsy: Parallel, Serial i USB. Zanim zaczniemy proces konfiguracji, musimy sie upewniæ, ŋe są zaģadowane odpowiednie moduģy jądra (w przeciwnym wypadku dany backend moŋe byæ nieaktywny).
Drukarka podģączona do portu równolegģego będzie wymagaģa moduģów lp, parport i parport_pc. Moduģ lp dopisujemy do pliku /etc/modules, jeķli nie uŋywamy udeva to pozostaģe moduģy takŋe. Drukarki podģączane pod port LPT są dostępne za pomocą urządzeņ /dev/lp*. W przypadku drukarek USB konieczny będzie moduģ usblp oraz rzecz jasna moduģ kontrolera USB, urządzenia te będą dostępne za pomocą /dev/usb/lp*. Więcej o moduģach jądra i ich zarządzaniu odnajdziemy w sekcja Moduģy jądra w rozdziaģ Kernel i urządzenia.
CUPS od wersji 1.3 wymaga zdefiniowania opcji Group w pliku /etc/cups/cupsd.conf, która wskazuje jaki uŋytkownik ma byæ uŋywany dla uruchamiania zewnętrznych programów - w tym backendów. Jako ŋe urządzenia w katalogu /dev mają grupę ustawioną na lp, taką teŋ podamy jako wartoķæ parametru:
Group lp |
Dalszą instalację przeprowadzamy zgodnie z zaprezentowanym wczeķniej opisem Dodanie drukarki.
Szczegóģy dodawania drukarki zdalnej
IPP
Aby CUPS byģo klientem IPP musimy dodaæ drukarkę z backendem IPP oraz podaæ prawidģowy URI zasobu, jako producenta wybieramy Raw, zaķ jako model Raw Queue. URI powinno mieæ następującą postaæ:
ipp://{$serwer}/printers/{$drukarka}
($serwer to nazwa lub IP serwera druku, zaķ $drukarka to nazwa drukarki). Adres taki moŋe wyglądaæ następująco:
ipp://10.0.0.3/printers/laserowa
SMB
Jedyne co musimy zrobiæ to dodaæ drukarkę z uŋyciem odpowiedniego backendu - Windows Printer via SAMBA i podaæ prawidģowy URI, na koniec musimy wskazaæ sterownik danej drukarki. W przypadku systemów MS z serii 95/98/Me URI powinno mieæ następującą postaæ:
smb://{$serwer}/{$drukarka}
($serwer to nazwa lub IP serwera druku, zaķ $drukarka to nazwa drukarki). Adres taki moŋe wyglądaæ następująco:
smb://wodzu/laserowa
W przypadku systemów z serii NT (NT4, 2000, XP Professional) moŋe byæ konieczne podanie konta uŋytkownika i hasģa:
smb://{$uŋytkownik}:{$hasģo}@{$serwer}/{$drukarka}
np.:
smb://jasio:mojehasģo@wodzu/laserowa
Konfiguracja serwera
Aby udostępniæ w sieci zainstalowaną drukarkę, musimy odpowiednio skonfigurowaæ demona cupsd, jego konfiguracja jest przechowywana w pliku /etc/cups/cupsd.conf.
Domyķlnie CUPS pozwala jedynie na drukowanie lokalne, aby uzyskaæ dostęp z sieci musimy dokonaæ zmian w pliku konfiguracji. Naleŋy odszukaæ sekcję oznaczoną znacznikami <Location /></Location>. Dostęp z innych maszyn konfigurujemy za pomocą opcji Allow From {$klient} ($klient to nazwa lub adres IP lub klasa adresów, którym udostępniamy drukarkę). Poniŋszy przykģad przedstawia udostępnienie drukarek dla lokalnego interfejsu i maszyny o adresie 10.0.0.12.
<Location /> Order Deny,Allow Deny From All Allow From 127.0.0.1 Allow From 10.0.0.12 </Location> |
Jeķli chcemy mieæ moŋliwoķæ zdalnej administracji za poķrednictwem HTTP/HTTPS powinniķmy dodatkowo ustawiæ dostęp (zgodnie z powyŋszymi wskazówkami) dla sekcji: /admin, /admin/conf.
IPP
Protokóģ IPP jest uŋywany domyķlnie przez CUPS i nie wymaga ŋadnych dodatkowych przygotowaņ.
SMB
W systemie musi byæ zainstalowany i dziaģający pakiet Samba. Aby systemy Microsoftu mogģy "widzieæ" drukarki CUPS naleŋy dokonaæ modyfikacji w gģównym pliku konfiguracji Samby - /etc/samba/smb.conf. Naleŋy usunąæ z niego wszystkie opcje dotyczące druku z sekcji [global], zaķ w ich miejsce wstawiæ poniŋsze linijki:
printing = cups printcap name = cups
Na koniec naleŋy przygotowaæ sekcję drukarek. Prosty przykģad pliku konfiguracji pakietu Samba moŋe wyglądaæ następująco:
[global] netbios name = shilka workgroup = pod_cisami security = share printing = cups printcap name = cups [printers] comment = Drukarki printable = yes path = /var/spool/samba
Jako, ŋe Windows pre-formatuje dokumenty zanim wyķle je przez sieæ do drukarki, musimy nauczyæ CUPS'a odpowiednio takie pre-formatowane dokumenty obsģugiwaæ. W tym celu musimy wyedytowaæ plik /etc/cups/mime.convs i odkomentowaæ w nim linijkę
application/octet-stream application/vnd.cups-raw 0 -
w pliku /etc/cups/mime.types zaķ, naleŋy odkomentowaæ linijkę
application/octet-stream
Po tych operacjach wymagany jest oczywiķcie restart usģugi CUPS.
# /etc/rc.d/init.d/cups restart
Przy tak skonfigurowanym serwerze drukarkę w MS Windows dodajemy standardowo, musimy jedynie samemu dostarczyæ odpowiedni sterownik. Istnieje moŋliwoķæ umieszczenia takiego sterownika na serwerze Samba, wymaga to jednak dodatkowych operacji konfiguracyjnych. Więcej na ten temat odnajdziemy w dokumentacji Samby.
Zarządzanie kolejką druku
Zarządzanie wydrukami jest moŋliwe z poziomu przeglądarki internetowej, programów dla X-Window oraz z poziomu linii wiersza poleceņ. Z poķród tych ostatnich mamy do dyspozycji: lpstat, lpmove, cancel, lpq oraz lprm. Programy te znajdują się w pakiecie cups-clients.
Test drukarki i rozwiązywanie problemów
Drukarka powinna dziaģaæ od razu po zainstalowaniu, moŋna to przetestowaæ z poziomu panelu konfiguracji drukarki drukując stronę testową. W razie problemów pierwszą rzeczą jaką naleŋy zrobiæ to przejrzeæ plik rejestrowania bģędów (log): /var/log/cups/error_log. Jeķli ciągle nie moŋemy odnaležæ žródģa problemu moŋemy spróbowaæ wģączyæ wysoki poziom raportowania bģędów. Dokonujemy to przez edycję w pliku /etc/cups/cupsd.conf i przestawienie ustawienia opcji "LogLevel" z "info " na "debug" lub " debug2" np.:
LogLevel debug2 |
Kiedy rozwiąŋemy problem naleŋy przywróciæ poprzedni poziom raportowania ze względu na szybki przyrost objętoķci logów. Po kaŋdej modyfikacji pliku konfiguracji naleŋy przeģadowaæ demona:
# /etc/rc.d/init.d/cups restart |
DHCPD - Dynamic Host Configuration Protocol Daemon
DHCP to protokóģ pozwalający urządzeniom pracującym w sieci LAN na pobieranie ich konfiguracji IP (adresu, maski podsieci, adresu rozgģoszeniowego itp.) z serwera. Uģatwia on administrację duŋych i ķrednich sieci.
Instalacja
Aby uruchomiæ serwer DHCP musimy oczywiķcie zainstalowaæ go. Instalacja w PLD jest prosta:
# poldek -i dhcp |
Podstawowa konfiguracja
Konfiguracja usģugi przechowywana jest w pliku /etc/dhcpd.conf , z pakietem dostarczona jest przykģadowa konfiguracja, pozwalająca uruchomiæ usģugę po zmianie zaledwie kilku wartoķci. Przedstawiona poniŋej sekcja zawiera parametry dla okreķlonej podsieci. Dla większej jasnoķci w poniŋszym przykģadzie uŋyto skróconej wersji konfiguracji.
ddns-update-style ad-hoc;
# Sekcja konfiguracji hostów z podsieci o podanym adresie i masce
subnet 192.168.0.0 netmask 255.255.255.0 {
# domyķlna brama sieciowa
option routers 192.168.0.1;
# maska
option subnet-mask 255.255.255.0;
# nazwa domeny (FQDN)
option domain-name "domain.org";
# adres serwera DNS (kolejne dodajemy po przecinku)
option domain-name-servers 192.168.1.1;
# zakres dzierŋawionych adresów IP (z wģączoną obsģugą protokoģu BOOTP)
range dynamic-bootp 192.168.0.128 192.168.0.255;
# domyķlny czas dzierŋawy (w sekundach)
default-lease-time 21600;
# maksymalny czas dzierŋawy (w sekundach)
max-lease-time 43200;
} |
Wewnątrz przedstawionej sekcji (ograniczonej nawiasami klamrowymi) umieszczane są opcje jakie zwykle podajemy przy statycznej konfiguracji interfejsu sieci. Powyŋsza konfiguracja będzie przydzielaæ komputerom dynamiczne adresy IP z zakresu 192.168.0.128 - 192.168.0.255 na okres 21600 sekund, jednak nie większy niŋ 43200 sekund.
I to juŋ prawie koniec, teraz zostaje nam sprawdzenie pliku /etc/sysconfig/dhcpd . Znajdujemy w nim linijki:
# The names of the network interfaces on which dhcpd should # listen for broadcasts (separated by space) DHCPD_INTERFACES="" |
W cudzysģów wpisujemy nazwy interfejsów na których będzie nasģuchiwaģ dhcpd (np. eth1). Po tej operacji wystarczy uruchomiæ lub zrestartowaæ usģugę.
Statyczne przypisanie konfiguracji
Aby komputery mogģy za kaŋdym razem uzyskaæ taką samą konfigurację, musimy dla kaŋdego z nich dodaæ odpowiednie wpisy w pliku konfiguracji. Konfiguracje hostów umieszczamy wewnątrz przedstawionej powyŋej sekcji konfiguracji podsieci (uwaga na nawiasy klamrowe).
host nazwa_hosta {
hardware ethernet 12:34:56:78:AB:CD;
fixed-address 192.168.0.20;
} |
Poszczególne komputery identyfikujemy za pomocą adresów sprzętowych kart sieciowych (MAC). Powyŋszy przykģad wymusza przydzielenie adresu IP 192.168.0.20 maszynie o MAC-u 12:34:56:78:AB:CD. Adresy MAC odczytamy za pomocą programu ip, lub iconfig, szczegóģy na ten temat odnajdziemy w sekcja Narzędzia sieciowe w rozdziaģ Zastosowania sieciowe.
Inne opcje
Poniŋej zamieszczono przykģady innych nieco rzadziej uŋywanych opcji.
Domena NIS:
option nis-domain "domain.org"; |
Opcje protokoģu NetBIOS:
#Adres serwera WINS
option netbios-name-servers 192.168.1.1;
#Rodzaj węzģa NetBIOS
option netbios-node-type 2; |
Adres serwera czasu NTP:
option ntp-servers 192.168.1.1; |
Konfiguracja klienta
Szczegóģowy opis konfiguracji klienta DHCP umieszczono w sekcja Ethernet w rozdziaģ Interfejsy sieciowe. Jeķli zechcemy sprawdziæ poprawnoķæ konfiguracji przydzielonej hostowi to wystarczy uŋyæ programu ip, lub iconfig, szczegóģy odnajdziemy w sekcja Narzędzia sieciowe w rozdziaģ Zastosowania sieciowe.
Uwagi
W większoķci wypadków najlepszym wyborem będzie przypisywanie niezmiennych adresów IP dla kaŋdej z maszyn, pozwoli to zachowaæ porządek i lepszą kontrolę nad siecią. Jest to absolutnie konieczne w wypadku serwerów oraz routerów, jednak przy tego typu maszynach zaleca się zrezygnowanie z DHCP na korzyķæ statycznej konfiguracji.
Domyķlnie logi demona są rejestrowane przez syslog-a z ustawionym žródģem (facility) na "daemon". Tego rodzaju komunikaty zwykle są zapisywane do pliku /var/log/daemon , dlatego tam wģaķnie powinniķmy szukaæ informacji jeķli wystąpią jakieķ problemy.
Exim - Transport poczty elektronicznej (MTA)
Usģuga MTA (ang. message transfer agent) jest odpowiedzialna za przesyģ m.in. e-mail między serwerami. Najpopularniejszymi przedstawicielami tego typu usģug są: Sendmail, Postfix czy opisany przez nas Exim. Oto zalety jakie przemawiają za wybraniem Exim-a jako naszego MTA:
Poniewaŋ Sendmail nie posiada nawet poģowy jego funkcji
Autoryzacja w Exim-ie zaimplementowana jest domyķlnie
Wspóģpracuje z bazami MySQL i z Postgres-em, a takŋe ze zwykģymi plikami tekstowymi
Tom Kistner napisaģ do Exim uŋyteczna ģatkę, rozbudowywującą Exim o obsģugę programów antywirusowych, demona SpamAssasin (skanera antyspamowego) oraz wykrywania bģędów MIME - dzięki temu nie potrzebujemy wielkich i zasoboŋernych programów w perlu
Za to Tomasz Kojm napisaģ bardzo dobry program antywirusowy: Clam AntiVirus - darmowy, w dodatku rewelacyjnie wspóģpracujący z Exiscanem
Podsumowując - Exim jest rewelacyjnym MTA. Jego moŋliwoķci konfiguracji pozwoliģy mi na zbudowanie dosyæ rozbudowanego serwera poczty obsģugującego zarówno konta lokalne jak i konta zapisane w bazie danych MySQL. Dodatkowe moŋliwoķci to np. przeszukiwanie plików konfiguracyjnych serwera cvs w poszukiwaniu adresów docelowych dla aliasów w domenie cvs.rulez.pl. O rzeczach takich jak klasyfikowanie maili czy są spamem czy nie juŋ nawet nie wspomnę. W dodatku Exim jest caģkiem bezpiecznym MTA (wersja 4.x wg. securityfocus jak narazie dorobiģa się jednego bģędu - w koņcu jakaķ cena musi byæ za te wodotryski). Zresztą konstrukcja omawianego MTA na początku doprowadzaģa mnie do szaģu, gdyŋ Exim nie moŋe sobie poradziæ z smtp-auth via PAM z racji braku uruchamiania autoryzacji z wģasnego uid/gid zamiast root ;-)
Instalacja
Instalacja pakietu jest prosta. Uruchamiamy program: poldek i wykonujemy:
poldek -i exim |
Oczywiķcie zanim wykonamy zalecenie startu demona powinniķmy dokonaæ konfiguracji, którą opisuje następny rozdziaģ.
Budowa pliku konfiguracji
Wszelkich zmian w konfiguracji dokonujemy w pliku /etc/mail/exim.conf. Na początek wyjaķnimy jak zorganizowany jest plik konfiguracyjny, wygląda to mniej więcej tak:
# gģówna sekcja ... opcje i dyrektywy sekcji gģównej begin sekcja1 opcje i dyrektywy sekcji1 begin sekcja3 ... |
Tak więc plik ten jest zbudowany z sekcji, które rozpoczynają się sģowem begin nazwa, z wyjątkiem sekcji gģównej, która jest na samym początku pliku i nie posiada swojego begina. Sekcje równieŋ nie mają ŋadnych sģów kluczowych, które by je zamykaģy - po prostu początek begin nowej sekcji oznacza zakoņczenie poprzedniej. I tak, standardowo mamy następujące sekcje:
gģówna - odpowiedzialna za podstawowe ustawienia Exim
acl - listy kontroli dostępu, filtrowania, odrzucania i akceptowania poczty
routers - hm, najproķciej jest to przetģumaczyæ jako routery, czyli reguģy kierowania wiadomoķci do odpowiednich transporterów
transports - tutaj tworzymy sposoby doręczenia poczty
retry - ustawienia ponowieņ
rewrite - reguģy do przepisywania nagģówków
authenticators - reguģy do autoryzacji
Co to są te caģe 'transportery' i 'routery'? Wģaķciwie to serce Exima. Jeŋeli Exim dostaje jakiegoķ maila to najpierw puszcza go przez routery, które moŋna porównaæ do reguģ ipchains/iptables - jeŋeli mail zaģapie się na jakąķ reguģę (router) to jest przekazywany do transportu okreķlonego przez ten router. Inaczej mówiąc router w Eximie kieruje maila do odpowiedniego transportera. Transporter natomiast robi juŋ z mailem co naleŋy - doręcza go lokalnie, albo przekierowywuje gdzieķ indziej albo odsyģa do innego serwera. Wiem, ŋe w tym momencie moŋe wydawaæ się to skomplikowane, ale nie przejmujcie się, to tylko wiedza teoretyczna która na początku nie będzie wam potrzebna. Musiaģem natomiast wam wytģumaczyæ, ŋe są sekcje i ŋe musicie nauczyæ się tego, iŋ jak napiszę 'dopisaæ w sekcji gģównej' to naleŋy coķ dopisaæ na początku pliku.
Podstawowa konfiguracja
Zanim zaczniemy konfigurację demona SMTP, musimy koniecznie dodaæ rekord MX do kaŋdej strefy DNS obsģugiwanej przez nasz serwer. Informacje na ten temat zawarto w sekcja BIND - Serwer Nazw.
Domeny lokalne to takie, które Exim ma traktowaæ jako 'swoje' domeny. Mail zaadresowany @jakas.domena.lokalna który dotrze do Exim zostanie dostarczony lokalnie. Domeny takie definiuje w dyrektywie domainlist local_domains. Standardowo, przyjmowana jest poczta wysyģana do domeny identycznej jak hostname serwera:
domainlist local_domains = @ |
Znak @ oznacza wģaķnie 'moja nazwa'. Aby dopisaæ kolejne domeny wystarczy dodaæ je do tej listy rozdzielając je dwukropkami:
domainlist local_domains = @ : domena.pl : baseciq.org : \
/etc/mail/local_domains |
Poza domena.pl, baseciq.org, Exim będzie teraz takŋe akceptowaģ domeny wypisane w pliku /etc/mail/local_domains. Domeny tam naleŋy wpisywaæ w oddzielnych linijkach. Exim o tyle fajnie dziaģa, ŋe po dopisaniu ķcieŋki do pliku, wystarczy go raz zrestartowaæ. Jakiekolwiek kombinacje w /etc/mail/local_domains nie będą wymagaģy restartu. Tak więc najwygodniej będzie dopisaæ do pliku konfiguracyjnego:
domainlist local_domains = @ : /etc/mail/local_domains |
I po prostu powpisywaæ wszystkie domeny do /etc/mail/local_domains.
Domeny dla których mamy byæ zapasowym MX'em tworzy się bardzo ģatwo. Linijkę pod domainlist local_domains jest domainlist relay_to_domain. Dziaģa to w taki sam sposób jak konfiguracja domen lokalnych, czyli, piszemy:
domainlist relay_to_domains = /etc/mail/relay_to_domains |
Od teraz, Exim będzie akceptowaģ kaŋdą pocztę zaadresowaną do domen zawartych w pliku /etc/mail/relay_to_domains. A co z nią zrobi? Jak wiadomo, jeŋeli domena ma kilka MX'ów, to Exim będzie staraģ się ją dostarczyæ do serwera o najniŋszym priorytecie MX. Chyba ŋe on ma najniŋszy, to wygeneruje bģąd.
Relaying, czyli okreķlenie kto moŋe przez nasz serwer wysyģaæ pocztę. I tutaj, listę adresów i hostów buduje się w podobny sposób do local_domains i relay_to_domains. Wystarczy stworzyæ listę o nazwie relay_from_hosts:
hostlist relay_from_hosts = 127.0.0.1 : 192.168.0.0/16 |
Uwaga! Juŋ w tym momencie moŋemy sprawdziæ dziaģania serwera. Wystarczy ŋe przeģadujemy demona i wyķlemy e-mail do istniejącego konta uŋytkownika. Przy takiej konfiguracji poczta będzie docieraģa do skrzynek typu mbox.
Skrzynki pocztowe
Exim potrafi umieszczaæ pocztę zarówno w skrzynkach typu mbox (pliki tekstowe w /var/mail/) jak i coraz popularniejszych skrzynkach typu Maildir (pliki przechowywanie w katalogu umieszczonym w katalogu domowym uŋytkownika). Ze względu na wsteczną zgodnoķæ Exim domyķlnie uŋywa tych pierwszych, aby uŋywaæ Maildir-a wykonujemy następujące czynnoķci:
W sekcji konfiguracji transporterów odszukujemy opcję "local_delivery", tam wstawiamy znak komentarza przed opcją "file =" i dodajemy linijki:
maildir_format = true
directory=${home}/Mail/Maildir |
local_delivery:
driver = appendfile
# file = /var/mail/$local_part
delivery_date_add
envelope_to_add
return_path_add
group = mail
mode = 0660
maildir_format = true
directory=${home}/Mail/Maildir |
Moŋemy przekazaæ dostarczanie poczty do skrzynek programowi Procmail. Wystarczy, ŋe w sekcji routerów usuniemy znaki komentarza z kolejnych wierszy zaczynających się od "procmail:", podobnie postępujemy w sekcji transporterów w miejscu zaczynającym się od wiersza "procmail_pipe:". Na koniec musimy jeszcze tylko umieķciæ plik konfiguracji Procmaila: .procmailrc w katalogu domowym uŋytkownika.
Róŋne opcje
Czasami (czytaj: gdy mamy sieczkę w /etc/hosts) Exim zgģasza się nie jako serwer.domena.pl a jako sam 'serwer'. Jeŋeli zmiana wpisów w /etc/hosts nie pomaga, albo gdy chcemy aby nasze MTA przedstawiaģo się inaczej niŋ hostname maszyny na którym stoi wystarczy ustawiæ (bądž dodaæ gdy jej nie ma) opcję primary_hostname w gģównej sekcji:
primary_hostname = serwer.domena.pl |
W czasach zabawy z Sendmail-em podawaģem takŋe sposób
na ograniczenie bannera, który się pojawiaģ po telnecie
na port 25. W Exim-ie nie jest to skomplikowane i sģuŋy
do tego opcja smtp_banner w sekcji gģównej:
smtp_banner = $primary_hostname ESMTP $tod_full |
Spowoduje to wyķwietlanie następującego tekstu jako bannera:
220 serwer.domena.pl ESMTP Wed, 23 Jul 2003 15:18:04 +0200 |
Chyba nie muszę tģumaczyæ, ŋe aby usunąæ datę naleŋy
wywaliæ $tod_full?
Teraz zajmiemy się aliasami. Plik z aliasami powinien znajdowaæ się w /etc/mail/aliases. Jest to czysty plik tekstowy, wprowadzone w nim zmiany wymagają wydania polecenia newaliases. Restart demona nie jest konieczny. Jeŋeli jednak nie macie pewnoķci czy tam powinien byæ plik z aliasami, w sekcji routers odszukajcie ciąg system_aliases: - jest to definicja routera odpowiedzialnego za rozwiązywanie aliasów. Tam teŋ, w linijce data widaæ ķcieŋkę do pliku z aliasami:
system_aliases:
driver = redirect
allow_fail
allow_defer
data = ${lookup{$local_part}lsearch{/etc/mail/aliases}}
file_transport = address_file
pipe_transport = address_pipe |
Autoryzacja SMTP
Jeŋeli z naszego SMTP korzystają uŋytkownicy spoza sieci lokalnej przyda nam się autoryzacja. Sprawa w Exim-ie jest dosyæ zawiģa. Otóŋ Exim zbyt wczeķnie zrzuca uprawnienia root, tak ŋe opisywany na wielu stronach opis zrobienia autoryzacji via PAM najczęķciej nie dziaģa. Z pomocą przyjdzie nam pakiet cyrus-sasl, a dokģadniej pwcheck daemon (w PLD cyrus-sasl-saslauthd). W sekcji AUTHENTICATORS wpisujemy następujące linijki (lub kasujemy komentarze #)
plain:
driver = plaintext
public_name = PLAIN
server_prompts = :
server_condition = ${if saslauthd{{$1}{$3}}{1}{0}}
# powyŋszy wpis zadziaģa przy saslauthd -a shadow, jeŋeli
# uruchomicie saslauthd -a pam (np. PLD) wpiszcie wtedy:
# server_condition = ${if saslauthd{{$1}{$3}{smtp}}{1}{0}}
server_set_id = $2
login:
driver = plaintext
public_name = LOGIN
server_prompts = "Username:: : Password::"
server_condition = ${if saslauthd{{$1}{$2}}{1}{0}}
# powyŋszy wpis zadziaģa przy saslauthd -a shadow, jeŋeli
# uruchomicie saslauthd -a pam (np. PLD) wpiszcie wtedy:
# server_condition = ${if saslauthd{{$1}{$2}{smtp}}{1}{0}}
server_set_id = $1 |
Ostatnią rzeczą przy saslauthd (uruchomionym z opcją -a pam) jaką trzeba
stworzyæ (lub sprawdziæ czy jest) to plik
/etc/pam.d/smtp:
#%PAM-1.0 # # example PAM file for saslauthd - place it as /etc/pam.d/ # (e.g. /etc/pam.d/smtp if you want to use saslauthd for SMTP # AUTH) # auth required /lib/security/pam_listfile.so item=user sense=deny file=/etc/security/blacklist onerr=succeed auth required /lib/security/pam_unix.so auth required /lib/security/pam_tally.so file=/var/log/faillog onerr=succeed no_magic_root auth required /lib/security/pam_nologin.so account required /lib/security/pam_tally.so deny=0 file=/var/log/faillog onerr=succeed no_magic_root account required /lib/security/pam_unix.so session required /lib/security/pam_unix.so |
Pozostaje mi tylko wam przypomnieæ, ŋe przed sprawdzaniem autoryzacji naleŋy takŋe uruchomiæ pwcheck saslauthd
# echo 'pwcheck_method:saslauthd' > /etc/sasl/smtpd.conf |
Syfrowanie SSL
Exim sobie bardzo dobrze radzi z poģączeniami szyfrowanymi przy uŋyciu protokoģu SSL (wspiera metodę STARTTLS). Wystarczy wygenerowaæ odpowiednie certyfikaty:
$ openssl genrsa -out /etc/mail/exim.key 1024
Generating RSA private key, 1024 bit long modulus
.......++++++
..............................++++++
e is 65537 (0x10001)
$ openssl req -new -x509 -days 365 -key /etc/mail/exim.key -out \
/etc/mail/exim.crt
Using configuration from /var/lib/openssl/openssl.cnf
You are about to be asked to enter information that will be
incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:PL
State or Province Name (full name) [Some-State]:Mazowsze
Locality Name (eg, city) []:Warsaw
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Baseciq Ltd.
Organizational Unit Name (eg, section) []:Baseciq's Mail Server
Common Name (eg, YOUR name) []:viper.baseciq.org
Email Address []:baseciq@baseciq.org |
Oczywiķcie na pytania odpowiadajcie podając swoje dane... Po takim zabiegu do sekcji gģównej Exim naleŋy dopisaæ:
tls_certificate = /etc/mail/exim.crt tls_privatekey = /etc/mail/exim.key tls_advertise_hosts = * |
Po tym zabiegu i restarcie Exim powinien bez problemu komunikowaæ się po SSL, co zresztą widaæ w logach:
2003-09-07 01:48:36 19vmnC-0006EG-27 <= bensonzow@beer.com H=plug.atn.pl [217.8.186.28] U=exim P=esmtp X=TLSv1:DES-CBC3-SHA:168 S=2909 id=ebb601c374e2$80dace00$cab00a12@fv |
Dawniej Exim mógģ nasģuchiwaæ porcie 465 jedynie przy uŋyciu inetd, w nowszych wersjach wystraczy ŋe ustawimy odpowiednie opcje:
daemon_smtp_ports = 25 : 465 tls_on_connect_ports = 465 |
Warto by byģo, ŋeby takŋe pop3d obsģugiwaģ SSL natywnie ssl (bez jakichķ stunneli i innych wynalazków). Ja osobiķcie polecam demonik tpop3d, którego konfiguracja jest bardzo prosta. Instalujemy tpop3d:
# poldek -i tpop3d |
a następnie wystarczy ŋe standardowe listen-address w pliku /etc/tpop3d.confzmienimy na takie:
listen-address: 0.0.0.0;tls=stls,/etc/mail/exim.crt,/etc/mail/exim.key \ 0.0.0.0;tls=immediate,/etc/mail/exim.crt,/etc/mail/exim.key |
Od teraz tpop3d na porcie 110 będzie obsģugiwaģ SSL po wykonaniu komendy STLS (np. TheBat potrafi tak zacząæ sesję SSL) a na porcie 995 będzie od razu uŋywaģ SSL (TheBat, Outlook Express).
Quota
Generalnie nie ma sensu męczyæ kernela i filesystemu ŋeby pilnowaģ quoty na pocztę. Szczególnie gdy MTA samo sobie moŋe z tym poradziæ. Sģuŋy do tego parametr quota w konfiguracji transportów. I tak, w najprostszy sposób moŋna lokalną quotę per user ustawiæ w konfiguracji transportu local_delivery (odpowiedzialnego za lokalne dostarczanie poczty):
local_delivery: driver = appendfile file = /var/mail/$local_part delivery_date_add envelope_to_add return_path_add # A tutaj dodajemy quotę w wysokoķci 20MB: quota = 20M |
Proste, prawda? Tak naprawdę ma to zastosowanie w systemach poczty wirtualnej gdzie moŋemy w bazie danych przechowywaæ quotę uŋytkownika i moŋna skonstruowaæ zapytanie SQL do odpytania ile miejsca ma dany uŋytkownik. Ale jeŋeli nie moŋecie sobie poradziæ z quotą systemową, moŋecie zamiast quota = 20M dopisaæ coķ takiego:
quota = ${lookup{$local_part}lsearch{/etc/mail/quota.conf}{$value}{0M}} |
Od tego momentu w pliku /etc/mail/quota.conf moŋesz trzymaæ wielkoķci skrzynek dla poszczególnych uŋytkowników. Jeŋeli ktoķ nie zostanie tam wymieniony, to nie będzie miaģ ŋadnych limitów na swoją skrzynkę pocztową. Plik taki powinien wyglądaæ mniej więcej tak:
lukasz: 100M kflis: 5M ania: 20M |
I tak oto ja mam 100mb na pocztę, kubuķ tylko 5, a siostra 20 MB ;) Podobnym parametrem kaŋdego transportera jest message_size_limit. Wystarczy wpisaæ:
message_size_limit = 10M |
Podobnie jak powyŋej, moŋna zrobiæ to na bazie pliku - wystarczy zamiast /etc/mail/quota.conf uŋyæ np. /etc/mail/size_limits.conf ;-) BTW. na koņcu linijki z quotą, gdzie mamy '0M' moŋemy wstawiæ np. '20M'. Wtedy, osoby nie dopisane do /etc/mail/quota.conf będą miaģy 20MB limitu (limit domyķlny).
Oczywiķcie jak na Exim przystaģo, od quoty jest więcej bajerków. Chyba najbardziej poŋądanym będzie opcja quota_warn_message. Jest to nic innego jak mail ostrzegający usera o tym, ŋe skrzynka jest zapchana po same brzegi. Zanim jednak polecisz to wdraŋaæ, zainteresuj się jak to dziaģa. Otóŋ po dostarczeniu kaŋdego maila Exim będzie sprawdzaģ czy zostaģ przekroczony konkretny próg (podany w megabajtach lub w procentowo). Jeŋeli tak, wygeneruje on odpowiednią wiadomoķæ. I tak, dodajemy do molestowanego przez nas local_delivery następujące opcje:
quota_warn_message = "\ Content-Type: text/plain; charset=ISO-8859-2\n\ To: $local_part@$domain\n\ Reply-to: Administratorzy sieci <admins@twojadomena.pl>\n\ Subject: Informacja o Twoim koncie pocztowym\n\ \n\ *** Ta wiadomoķæ zostaģa wygenerowana automatycznie ***\n\ \n\ Uprzejmie informujemy, iŋ skrzynka pocztowa zostaģa zapeģniona w 90%\n\ swojej pojemnoķci. W przypadku 100% nie będą dostarczane\n\ do Ciebie nowe wiadomoķci. Opróŋnij skrzynkę pocztową ze starych\n\ wiadomoķci.\n" quota_warn_threshold = 90% |
Dodanie skanerów antywirusowych
Aby Exim wspóģpracowaģ z jakimķ antywirusem naleŋy najpierw wybraæ i zainstalowaæ program antywirusowy. Doķwiadczenie uczy, ŋe najlepszy jest program Clamav.
Instalujemy więc Clamav
# poldek -i clamav clamav-database |
Po zainstalowaniu Clamav musimy zmodyfikowaæ plik konfiguracyjny /etc/mail/exim.conf w sekcji gģównej ustawiamy typ antywirusa:
av_scanner = clamd:/var/lib/clamav/clamd.socket |
Po dwukropku ustawiamy ķcieŋkę do socketu antywirusa (w przypadku clamav - zajrzyj do pliku /etc/clamav.conf). W miejscu gdzie wpisaliķmy clamd, moŋemy wpisaæ takŋe i inny typ skanera. Niestety, ŋaden z innych obsģugiwanych (sophie, kavdaemon, drweb) skanerów nie jest darmowy. Jeŋeli natomiast wolicie mks, to moŋecie uŋyæ takiej opcji:
av_scanner = mksd |
Kolejnym etapem, jest stworzenie reguģ do filtrowania maili z wirusami. W tym celu, dopisujemy do sekcji gģównej pliku konfiguracyjnego Exim:
acl_smtp_data = exiscan |
Teraz zaczynamy grzebanie w sekcji acl, gdzie dopisujemy (najlepiej na samym początku):
exiscan:
deny message = Znaleziono wirusa. \n\
Virus or other harmful content found: $malware_name
delay = 1s
malware = *
warn message = X-MIME-Warning: Serious MIME defect detected ($demime_reason)
demime = *
condition = ${if >{$demime_errorlevel}{2}{1}{0}}
warn message = Message-ID: <E$message_id@$primary_hostname>
condition = ${if !def:h_Message-ID: {1}}
accept |
Pierwszy wpis odpowiednio skanuje caģy e-mail i jeķli zostanie znaleziony wirus lub inna zawartoķæ uznana za szkodliwą przez skaner antywirusowy to taki mail jest odrzucany oraz informacja o znalezionym wirusie zostaje wyķwietlona z jednosekudnowym opóžnieniem. Te opóžnienie ma na celu unikniecia ewentualnego zapchania serwera poczty poprzez uciąŋliwego uŋytkownika co chwila próbujacego wysģaæ pocztę uznaną za szkodliwą. Kolejny warunek spowoduje iŋ maile z uszkodzonymi nagģówkami MIME zostaną odpowiednio oznaczone (czyli, takŋe, duŋe maile podzielone na częķci, o czym niestety autor exiscana (aut. ģatki dla Exim-a) nie wspomina, dlatego ich nie odrzucamy). Ostatni warunek ma na celu wyeliminowanie sytuacji gdy jakaķ wiadomoķæ, która dotarģa do naszego serwera poczty nie posiada unikalnego identyfikatora. W takim przypadku generujemy i dopisujemy wģasny Message-ID.
Aby skaner av mógģ sprawdzaæ pocztę Exima musi zostaæ dodany do grupy exim. Dokonujemy tego poleceniem groupadd albo edytując po prostu plik /etc/group:
[...] exim:x:79:clamav,mail [...] |
Kolejny feature jaki daje exiscan to odrzucanie plików z zaģącznikiem o okreķlonym rozszerzeniu. W tym celu dopisujemy zaraz po exiscan: następujące linijki:
deny message = Niedozwolone zalaczniki. \n\
Blacklisted file extension ($found_extension) detected.
condition = ${if match \
{${lc:$mime_filename}} \
{\N(\.exe|\.pif|\.bat|\.scr|\.lnk|\.vbs)$\N} \
{1}{0}}
delay = 1s
log_message = Blacklisted file extension ($found_extension) detected. |
Powyŋsza regóģka ma na celu zablokowanie moŋliwoķci wysyģanie wiadomoķci, których zaģącznikami są pliki: *.exe, *.pif, *.bat, *.scr, *.lnk oraz *.vbs. Teraz, jeŋeli nie chcemy aby skanowane byģy maile pochodzące od danych adresów ip dopisujemy (jeŋeli chcemy aby Ci ludzie teŋ nie mogli wysyģaæ plików *.com, to po poprzedniej reguģce, jeŋeli oni będą mogli, to przed):
accept hosts = /etc/mail/dontscan |
Teraz, w pliku /etc/mail/dontscan umieszczamy adresy IP bądž klasy adresowe z których poczta ma nie byæ skanowana.
Jeŋeli natomiast chcecie, by poczta przeskanowana u was w przypadku gdy wróci w jakiķ sposób z powrotem do naszego serwera (np. poprzez alias na innym serwerze) nie byģa ponownie skanowana, moŋecie zacząæ oznaczaæ pocztę odpowiednimi znacznikami oraz przyjąæ ŋe poczta z tym znacznikiem nie byģa ponownie skanowana. Tak więc, przed koņcowym accept dodajemy:
warn message = X-Scan-Signature: ${hmac{md5}{atutajwpiszhaslo} \
{$body_linecount}} |
Exim spowoduje dodanie zaszyfrowanego ciągu znaków skģadającego się z hasģa i wielkoķci maila. Dzięki temu ktoķ kto nie pozna waszego hasģa nie będzie mógģ sfaģszowaæ informacji o tym ŋe mail zostaģ juŋ zeskanowany. Teraz, aby taka poczta przechodziģa bez skanowania, na samym początku po exiscan: dopisujemy:
accept condition = ${if eq {${hmac{md5}{atutajwpiszhaslo} \
{$body_linecount}}}{$h_X-Scan-Signature:} {1}{0}} |
Ustawienie takich reguģek z tym samym hasģem na kilku serwerach spowoduje ŋe gdy mail będzie przechodziģ przez kilka z nich, tylko jeden będzie musiaģ go przeskanowaæ.
Walka ze spamem
Zjawisko spamu jest niezwykle uciąŋliwe. W niektórych Stanach w USA
traktowane jest w kategoriach kryminalnych. Zapewne znasz jego
definicję lub przynajmniej wiesz jak spam wygląda. W skrócie jest to
wiadomoķæ e-mail, której nie chciaģeķ otrzymaæ. Exim posiada wbudowaną obsģugę
filtra antyspamowego opartego na technice dnsbl, moŋe wykorzystwaæ zarówno
czarne listy jak i biaģe listy nadawców oraz adresów serwerów.
Kolejnym bardzo prostym ale niezwykle skutecznym w walce ze spamem jest maksymalne opóžnianie procesu komunikacji pomiedzy klientem wysyģającym poczte a serwerem MTA. Nie tylko odcina to częķæ robotów spamerskich ale takŋe zmiejsza ryzyko przeciąŋenia serwera.
Przejdžmy do konfiguracji. Wszystkie te wpisy powinny znaleķæ się w sekcji ACL CONFIGURATION w obrębie acl_check_rcpt:.
Wymuszamy helo/ehlo
deny message = Wymagane RFC HELO/EHLO zanim wyslesz wiadomosc. \n\
RFCs mandate HELO/EHLO before mail can be sent.
condition = ${if or{{!def:sender_helo_name}{eq{$sender_helo_name}{}}}{yes}{no}}
delay = 5s
log_message = No HELO/EHLO. |
Definujemy wģasne biaģe listy.
Jeķli nasz zestaw regóģ okazaģby się zbyt restrycyjny moŋemy oznaczyæ aby pewne domeny
byģy traktowane "ulgowo".
accept domain = +local_domains condition = /etc/mail/whitelist |
Sprawdzamy czy serwer nadawcy figuruje na listach RBL
deny message = Serwer nadawcy figuruje na liscie RBL \n\ Server $sender_host_address is at RBL: \ $dnslist_domain\n$dnslist_text delay = 5s dnslists = blackholes.mail-abuse.org : \ dialup.mail-abuse.org : \ dnsbl.njabl.org : \ sbl.spamhaus.org : \ list.dsbl.org : \ cbl.abuseat.org : \ relays.ordb.org : \ bl.spamcop.net hosts = ! +relay_from_hosts log_message = Listed at RBL list: $dnslist_domain\n$dnslist_text. deny message = Serwer nadawcy figuruje na liscie RBL \n\ Server $sender_host_address is at RBL: $dnslist_domain. hosts = ! +relay_from_hosts dnslists = bogusmx.frc-ignorant.org/$sender_host_name : \ dns.rfc-ignorant.org/$sender_host_name delay = 5s log_message = Listed at RFC-Ignorant. |
Teraz dokonujemy weryfikacji podanego HELO
HELO nie moŋe byæ postaci localhost.localhomain
deny message = Niepoprawne HELO. \n\
$sender_helo_name is a stupid HELO.
hosts = !+relay_from_hosts
condition = ${if match {$sender_helo_name}{\N^(127\.0\.0\.1|localhost(\.localdomain)?)$\N}{yes}{no}}
delay = 5s
log_message = Stupid localhost HELO. |
HELO musi byæ nazwą domenową (hostname)
deny message = HELO musi byc nazwa domenowa. \n\
HELO must be hostname.
hosts = !+relay_from_hosts
condition = ${if !match {$sender_helo_name}\
{\N.*[A-Za-z].*\N}{yes}{no}}
delay = 5s
log_message = Helo must be hostname. |
Wedģug RFC821 HELO musi byæ peģną nazwą domenową (Fully Qualifield Domain Name).
deny message = HELO nie wyglada poprawnie. Zobacz RFC 821. \n\
HELO must contain a Fully Qualifield Domain Name. See RFC821.
hosts = !+relay_from_hosts
condition = ${if !match{$sender_helo_name} \
{\N.*[A-Za-z].*\..*[A-Za-z].*\N}{yes}{no}}
delay = 5s
log_message = HELO is not a FQDN. |
Eliminujemy sytuację gdy nadawca jako HELO podaje serwer z naszej domeny np. domena.pl
deny message = Wykryto zafalszowane RFC HELO. \n\
Fake HELO detected: $sender_helo_name.
condition = ${if eq{$sender_helo_name}\
{\N^(.*\.)?domena\.pl$\N}{yes}{no}}
hosts = !+relay_from_hosts
delay = 5s
log_message = Fake HELO from host $sender_helo_name. |
Kolejne dwa warunki są bardzo restrycyjnymi testami. Formalnie przez RFC nie jest wymagane aby domena miaģa zdefiniowany rekord MX. Lecz kaŋdy szanujący się administrator powaŋnej domeny zawsze zadba aby odpowiednie serwery figurowaly jako MX. RFC zaleca aby jeķli juŋ jest zdefiniowany rekord MX dla domeny, to aby byģ on postaci FQDN
deny message = Brak zdefiniowanego rekordu MX dla domeny. \n\
No MX envelope sender domain $sender_address_domain.
hosts = ! : !+relay_from_hosts
senders = ! :
condition = ${if eq{${lookup dnsdb{mx=$sender_address_domain}{$value}fail}}{fail}{yes}{no}}
delay = 5s
log_message = No MX record in DNS.
deny message = Rekord MX w DNS musi byc postaci FQDN. \n\
MX for transport sender domain $sender_address_domain must be FQDN.
hosts = ! : !+relay_from_hosts
senders = ! :
condition = ${if !match {${lookup dnsdb{mx=$sender_address_domain}{$value}fail}}\
{\N.*[A-Za-z].*\..*[A-Za-z].*\N}{yes}{no}}
delay = 5s
log_message = MX record is not a FQDN. |
Krótkie wyjaķnienie wykorzystanych opcji
deny message
Okreķlamy jaka informacja zwrotna pojawi się u nadawcy.
delay
Opóžnienie po jakim komunikat okreķlnony jako message zostanie zwrócony nadawcy.
dnslist
Lista systemów z bazami blokującymi serwery
open relay. Wymienione tutaj powinny skutecznie powstrzymaæ spam. Jeŋeli nadal dostajesz niechciane maile, wykonaj następujące czynnoķci. Sprawdž w nagģówku wiadomoķci adres IP serwera, który przekazaģ Twojemu MTA pocztę. Wejdž na stronę: www.ordb.org/lookup/ i wpisz adres IP do sprawdzenia. Jeŋeli wyszukiwanie w bazie ordb.org nie przyniesie rezultatów, wejdž tutaj: http://www.ordb.org/lookup/rbls/?host=w.x.y.z, gdzie zamiast symbolicznego zapisu podajemy adres IP. Skonstruowane w ten sposób zapytanie dokona sprawdzenia, czy dany adres IP figuruje na innych czarnych listach. Pozytywny rezultat testu powinien zwróciæ w odpowiedzi listę systemów RBL (Relay Black List). Moŋna ją wykorzystaæ dopisując do naszej reguģki. Uwaŋaj na system block.blars.org figuruje w nim smtp.wp.pl.hosts
Podana lista serwerów. W powyŋszym przykģadzie jest to !+relay_from_hosts co oznacza, ŋe caģa regóģka dotyczy poģączeņ z wszystkich serwerów za wyjątkiem tych zdefiniowanych jako relay_from_hosts.
log_message
Informacja jaka zostanie zapisana w dzienniku systemowym exima czyli /var/log/exim/main.log
Teraz naleŋaģoby wģączyæ wszystkie usģugi jakie zainstalowaliķmy
# /etc/rc.d/init.d/exim start # /etc/rc.d/init.d/saslauthd start # /etc/rc.d/init.d/clamd start # /etc/rc.d/init.d/tpop3d start # /etc/rc.d/init.d/rc-inetd restart |
Na koniec przykģadowy zapis z dziennika systemowego Exima
2004-03-04 21:05:24 H=(sina.com) [218.79.119.92] F=< jin@sina.com > \
rejected RCPT < user@domena.pl >: \
Serwer 218.79.119.92 figuruje na czarnej liķcie dnsbl.sorbs.net |
Obsģuga wielu domen w Eximie
Jeŋeli czytasz tą częķæ opisu konfiguracji exima stanąģeķ przed problemem obsģugi przez niego więcej niŋ jednej domeny. Exim jest jak najbardziej do tego przystosowany. Poniŋej zamieszczam listing z pliku /etc/mail/exim.conf
virtusertable_alias:
driver = redirect
allow_fail
allow_defer
data = ${lookup{$local_part@$domain}lsearch{/etc/mail/virtusertable}}
file_transport = address_file
pipe_transport = address_pipe
virtusertable_defaultalias:
driver = redirect
allow_fail
allow_defer
data = ${lookup{@$domain}lsearch{/etc/mail/virtusertable}}
file_transport = address_file
pipe_transport = address_pipe
|
Powyŋszy przykģad umieķæ umieķæ na początku sekcji routers. Dla przypomnienia
dodam, ŋe początek sekcji oznacza się sģowem kluczowym begin.
Jak sģusznie zauwaŋyģeķ, wpisy z virtusertable do zģudzenia przypominają
te z system_aliases. Dziaģa to wģaķciwie w ten sam sposób. Podczas
odbierania przesyģki exim czyta linijkę data. Ma w niej zdefiniowane, ŋe
ma szukaæ na podstawie local_partczyli to co jest przed znakiem
@ oraz domain czyli częķci domenowej adresu. Wartoķci
które zostaną podstawione zamiast tych zmiennych zostaną porównane z plikiem
/etc/mail/virtusertable. Jeŋeli wynik porównania wypadnie pomyķlnie
poczta zostanie dostarczona do odpowiedniego uŋytkownika, jeŋeli zaķ nie, odpytane zostaną
aliasy systemowe. Jeŋeli i tam uŋytkownik nie zostanie odnaleziony, zostanie wysģana
wiadomoķæ z odpowiednią informacją do nadawcy z komunikatem bģędu. Częķæ
defaultalias jest prawie identyczna. Róŋnica tkwi jedynie w opcji
data. Sprawdzana jest jedynie częķæ domenowa. Poniŋej zamieszczam listing
z pliku /etc/mail/virtusertable
user@domena.pl user mister@sample.com user2 @jakasdomena.pl user3 |
Jak widaæ budowa pliku jest prosta i czytelna. User3 będzie otrzymywaģ caģą pocztę z domeny jakasdomena.pl. Po tych zabiegach exim powinien byæ juŋ przygotowany do obsģugi wielu domen. Musisz pamiętaæ aby go zrestartowaæ po dokonaniu modyfikacji jego pliku konfiguracyjnego.
# /etc/rc.d/init.d/exim restart |
Automatyczna odpowiedž - Vacations
W przypadku, gdy masz zamiar gdzieķ wyjechaæ na dģuŋej i nie będziesz miaģ dostępu do poczty, dobrym pomysģem jest ustawienie automagicznej odpowiedzi dla ludzi, którzy do Ciebie piszą. Tu z pomocą przychodzi nam opcja w Eximie.
Na początku edytujemy plik /etc/mail/exim.conf i w sekcji routers
przed localuser router dodajemy następujące linijki:
user_vacation:
driver = accept
check_local_user
# nie odpisujemy na bģędy bądž listy dyskusyjne
condition = "${if or {{match {$h_precedence:} {(?i)junk|bulk|list}} {eq {$sender_address} {}}} {no} {yes}}"
no_expn
require_files = /var/mail/vacation/${local_part}/vacation.msg
# nie odpisujemy na maile od list dyskusyjnych oraz na powiadomienia o bģędach
senders = " ! ^.*-request@.*:\
! ^.*@list*.*:\
! ^owner-.*@.*:\
! ^postmaster@.*:\
! ^listmaster@.*:\
! ^mailer-daemon@.*\
! ^root@.*"
transport = vacation_reply
unseen
user = ${local_part}
no_verify |
Następnie tworzymy katalog /var/mail/vacation , w którym będą się znajdowaæ katalogi
zawierające nazwę uŋytkownika oraz pliki z informacjami o powodzie jego nieobecnoķci. Powód taki
wpisujemy do pliku vacation.msg znajdującego się w
/var/mail/vacation/NAZWA_UŊYTKOWNIKA/. Gdy juŋ mamy te ustawienia za sobą w sekcji
transport dodajemy następujące linijki:
vacation_reply:
driver = autoreply
file = /var/mail/vacation/$local_part/vacation.msg
file_expand
from = System Automatycznej Odpowiedzi <$original_local_part@$original_domain>
log = /var/mail/vacation/$local_part/vacation.log
once = /var/mail/vacation/$local_part/vacation.db
once_repeat = 7d
subject = ${if def:h_Subject: {Re: ${quote:${escape:${length_50:$h_Subject:}}} (autoreply)} {Informacja} }
text = "\
Witaj $h_from\n\n\
Ta wiadomoķæ zostaģa wygenerowana automatycznie\n\
Tekst poniŋej zawiera informację od uŋytkownika:\n\
====================================================\n\n\
"
to = "$sender_address" |
Waŋną częķcią tutaj jest opcja once_repeat, która sprawdza jak często nadawcy będą otrzymywaæ
odpowiedzi. W tej konfiguracji jest to co 7dni.
To wszystko, teraz musimy jeszcze zrestartowaæ Exima i moŋemy jechaæ na urlop.
# /etc/rc.d/init.d/exim restart |
Heimdal - Implementacja protokoģu Kerberos
Heimdal jest implementacją nowoczesnego sieciowego protokoģu uwierzytelniania uŋytkowników Kerberos. Uŋytkownik po standardowym zalogowaniu za pomocą hasģa na czas trwania sesji otrzymuje specjalny unikalny klucz (w terminologii kerberos'a nazywany biletem (ang. ticket)) za pomocą którego moŋe uzyskaæ dostęp do innych usģug w sieci juŋ bez koniecznoķci dodatkowego podawania hasģa.
Kaŋda sieæ posiada wydzielony serwer Kerberos, zwany KDC (Key Distibution Center) którego zadaniem jest zarządzanie centralną bazą kluczy (m.in. wydawanie nowych kluczy oraz odpowiadanie na pytania dotyczące ich autentycznoķci).
Uwaga:Kerberos nie zapewnia dystrybucji bazy uŋytkowników w sieci - do tego celu najlepiej uŋyæ usģugi NIS.
Instalacja i konfiguracja KDC
Za pomocą poldka instalujemy serwer i narzędzia heimdal'a:
# poldek -i heimdal heimdal-server |
Edytujemy plik konfiguracyjny /etc/heimdal/krb5.conf. Plik ten uŋywany jest przez biblioteki heimdal'a i powinien byæ obecny na wszystkich maszynach, na których będziemy uŋywali kerberos'a (na serwerze i klientach)
[libdefaults]
default_realm = FOO.PL
clockskew = 300
v4_instance_resolve = false
[realms]
FOO.PL = {
kdc = kdc.foo.pl
kpasswd_server = kdc.foo.pl
admin_server = kdc.foo.pl
}
[domain_realm]
.foo.pl = FOO.PL
foo.pl = FOO.PL |
default_realm okreķla domyķlną domenę kerberos'a.
Zamiast FOO.PL wpisujemy wybraną nazwę domeny, typowo jest to
pisana wielkimi literami nazwa naszej domeny dns.
kdc.foo.pl zastępujemy adresem serwera, na którym uruchomiony jest
serwer KDC heimdal'a.
clockskew okreķla maksymalną róŋnicę czasu (w sekundach) pomiędzy
serwerem a klientami (jeŋeli róŋnica czasu będzie większa niŋ podana,
kerberos odmówi wspóģpracy) dlatego dobrze w sieci uruchomiæ takŋe usģugę
synchronizacji czasu ntp.
Sekcja [realms] definiuje domeny kerberosa. Moŋna tu wymieniæ kilka
niezaleŋnych domen, okreķlając dla nich lokalizację serwerów kerberosa.
kdc.foo.pl zastępujemy oczywiķcie nazwą hosta na którym będzie uruchomiona
usģuga kdc.
Ostatnia sekcja [domain_realm]okreķla mapowanie nazw dns na domeny
kerberosa. Na tej podstawie heimdal wie na podstawie nazwy dns hosta w jakiej
domenie kerberos'a się znajduje. Nazwa dns zaczynająca się od kropki pasuje do
dowolnej poddomeny podanej domeny.
uruchamiamy usģugę dystrybucji kluczy KDC:
# service heimdal start |
Do zarządzania domeną kerberos'a uŋywamy narzędzia kadmin. Inicjalizujemy domenę i dodajemy uŋytkownika, w tym przypadku mrk (zostawiając domyķlnie proponowane wartoķci):
# kadmin -l kadmin>init FOO.PL kadmin>add mrk |
Opcja -l uruchamia kadmin w trybie lokalnym, program musi byæ uruchomiony z konta root. Moŋemy takŋe dopisaæ do pliku /etc/heimdal/krb5.acl:
mrk@FOO.PL all |
dając uŋytkownikowi mrk@FOO.PL prawo do administracji kerberosem - w tym przypadku
kadmin woģamy z parametrem -p uŋytkownik
Logujemy się w systemie na koncie zwykģego uŋytkownika (w naszym przykģadzie mrk) i próbujemy się zalogowaæ do domeny kerberosa:
$ kinit |
kinit domyķlnie próbuje uzyskaæ bilet dla zalogowanego uŋytkownika, moŋna to zmieniæ podając uŋytkownika jako parametr.
Sprawdzamy, czy kerberos wystawiģ nam bilet (ticket):
$ klist
Credentials cache: FILE:/tmp/krb5cc_1000_pSN1Vv
Principal: mrk@FOO.PL
Issued Expires Principal
Apr 13 11:02:40 Apr 13 21:02:40 krbtgt/FOO.PL@FOO.PL
|
Logowanie do systemu
Instalujemy moduģ pam-pam_krb5.
# poldek -i pam-pam_krb5 |
Zmieniamy wybrane pliki /etc/pam.d/*, dodając dodatkowo sprawdzanie hasģa za pomocą nowego moduģu:
Przykģadowo /etc/pam.d/login wykorzystywany przez program login poprawiamy tak:
#zmieniamy linijkę
auth required pam_unix.so |
na:
auth sufficient pam_unix.so auth required pam_krb5.so use_first_pass |
i dodajemy:
session optional pam_krb5.so |
W ten sposób moŋemy się zalogowaæ przy uŋyciu standardowej metody sprawdzania haseģ w /etc/shadow (pam_unix.so) lub w domenie kerberos'a (pam_krb5.so)
Analogicznie poprawiamy inne pliki, np. /etc/pam.d/gdm, /etc/pam.d/xscreensaver
Po tych poprawkach powinniķmy móc zalogowaæ się juŋ podając hasģo kerberos'a. Po zalogowaniu moŋemy jeszcze za pomocą polecenia klist sprawdziæ czy kerberos wystawiģ nam bilet:
$ klist |
Konfiguracja poszczególnych usģug
Kolejnym etapem jest "skerberyzowanie" poszczególnych usģug w naszej sieci tak,
by uwierzytelniaģy uŋytkownika na podstawie wystawionego biletu kerberos'a.
Zaprezentujemy to na przykģadzie sshd, cyrus-imap'a oraz apache'a - opis postępowania
w przypadku innych usģug obsģugujących uwierzytelnianie kerberos jest podobny,
Kaŋda skerberyzowana usģuga musi mieæ utworzone wģasne konto w domenie Kerberos'a
(tzw. service account). Z kontem tym związany jest klucz, który musi byæ
znany zarówno kdc i usģudze. Konto usģugi przewaŋnie jest w postaci:
nazwa_usģugi/hostname, przy czym hostname musi byæ
peģną nazwą hosta wraz z domeną, czyli tym, co zwraca hostname:
$ hostname --fqdn |
Ponadto naleŋy zadbaæ o poprawne odwzorowanie tej nazwy w DNS - opis jak wģaķciwie ustawiæ hostname znajduje się podstawach konfiguracji sieci
SSH
Tworzymy konto dla daemona sshd. Konto musi miec nazwę w postaci:
host/hostname
# kadmin -l kadmin> add -r host/host.foo.pl |
Parametr -r powoduje, ŋe do konta zostanie przypisany
losowy klucz (hasģo). Klucz ten jest zapisany jako jeden z atrybutów
uŋytkownika w bazie uŋytkowników domeny Kerberos'a
(dokģadnie w /var/lib/heimdal/heimdal.db).
By sshd miaģ takŋe dostęp do tego klucza robimy:
kadmin> ext_keytab host/host.foo.pl |
Powyŋsze polecenie zapisuje klucz związany z kontem usģugi do tzw. tablicy kluczy (keytab), z której to tablicy sshd moŋe go pobraæ. Klucz zostaje zapisany w domyķlnej tablicy kluczy znajdującej się w pliku /etc/heimdal/krb5.keytab. Z tej tablicy kluczy domyķlnie korzystają usģugi uŋywające kerberos'a.
By sshd uwierzytelniaģ uŋytkowników za pomocą kerberos'a do pliku /etc/ssh/sshd_config dodajemy jeszcze linijki:
GSSAPIAuthentication yes |
do pliku konfiguracyjnego klienta /etc/ssh/ssh_config dopisujemy:
GSSAPIAuthentication yes GSSAPIDelegateCredentials yes |
Opcja GSSAPIDelegateCredentials okreķla, czy bilet kerberosa
ma byæ przekazany na maszynę, na którą się logujemy.
Po restarcie sshd, jeŋeli mamy wystawiony bilet kerberosa powinniķmy móc zalogowaæ się przez ssh na nasz serwer bez pytania o hasģo.
Powyŋszy opis dotyczy sytuacji, gdy serwer sshd znajduje się na tej samej maszynie co kdc. Jeŋeli sshd jest na innej maszynie w sieci, musimy wyeksportowaæ klucz do innej tablicy kluczy:
kadmin> ext_keytab host/host.foo.pl sshd.keytab |
a następnie przenieķæ plik sshd.keytab na maszynę na której mamy uruchomione sshd. Trzeba jeszcze poinformowaæ sshd, ŋe ma szukaæ klucza w innej lokalizacji niŋ standardowe krb5.keytab. W pliku /etc/sysconfig/sshd dopisujemy:
export KRB5_KTNAME=/etc/heimdal/sshd.keytab |
Cyrus IMAP
Doinstalowujemy plugin gssapi do sasl'a
# poldek -i cyrus-sasl-gssapi |
Tworzymy konto dla cyrrus'a. Konto ma mieæ nazwę w postaci
imap/hostname:
kadmin> add -r imap/host.foo.pl |
exportujemy klucz do tablicy kluczy:
kadmin> ext_keytab /etc/heimdal/cyrus.keytab |
Wybieramy inną niŋ domyķlna tablicę kluczy, poniewaŋ cyrus imap pracuje z uprawnieniami uŋytkownika 'cyrus' i jako taki nie ma prawa czytania domyķlnej tablicy /etc/heimdal/krb5.keytab.
Dajemy dostęp do tablicy kluczy uŋytkownikowi cyrus:
chown cyrus.root /etc/heimdal/cyrus.keytab chmod 660 /etc/heimdal/cyrus.keytab |
Na koniec musimy jeszcze poinformowaæ cyrus'a gdzie ma szukaæ klucza. W pliku /etc/sysconfig/cyrus-imapd dodajemy:
export KRB5_KTNAME=/etc/heimdal/cyrus.keytab |
Przykģadowe programy klienckie, które potrafią uŋyæ protokoģu kerberos do uwierzytelnienia uŋytkownika to evolution i mutt
Apache
Doinstalowujemy moduģ apache'a obsģugujący uwierzytelnianie za pomocą kerberos'a:
# poldek -i apache-mod_auth_kerb |
Dodajemy konto usģugi w domenie kerberos'a:
kadmin> add -r HTTP/hostname |
hostname zastępując nazwą hosta na którym uruchomiony jest apache.
Exportujemy klucz, zmieniamy uprawnienia:
kadmin> ext HTTP/hostname /etc/heimdal/httpd.keytab # chown http.root /etc/heimdal/httpd.keytab # chmod 660 /etc/heimdal/httpd.keytab |
lokalizację tablicy kluczy moŋemy tak jak wczeķniej podaæ apache'owi globalnie przez zmienną ķrodowiskową, dopisując do /etc/sysconfig/apache:
export KRB5_KTNAME=/etc/heimdal/httpd.keytab |
Moŋna to takŋe zrobiæ za pomocą dyrektywy Krb5Keytab w pliku konfiguracyjnym apache'a
Przykģadowa konfiguracja dostępu moŋe wyglądaæ następująco:
<Directory "/home/users/mrk/public_html/kerberos">
AuthType Kerberos
AuthName "Kerberos Login"
KrbMethodNegotiate on
KrbMethodK5Passwd on
KrbAuthRealms FOO.PL
Krb5Keytab /etc/heimdal/httpd.keytab
require user mrk@FOO.PL
</Directory>
|
Próba dostępu z prawdopodobnie zakoņczy się pytaniem o hasģo. Naszym celem jest jednak dostęp do serwisu www'a za pomocą biletu kerberos'a, bez zbędnego podawania hasģa. W firefox'ie wpisujemy url: about:config, i szukamy pozycji:
network.negotiate-auth.delegation-uris network.negotiate-auth.trusted-uris |
Okreķlają one url'e, dla których przeglądarka ma zastosowaæ rozszerzenie negotiate. Wpisujemy tam nazwy dns naszego serwisu www oddzielone przecinkami. Teraz, jeķli mamy aktualny bilet (sprawdzamy przez klist), powinniķmy zostaæ wpuszczeni bez pytania o hasģo. Rozszerzenie negotiate oprócz firefox'a powinny obsģugiwaæ takŋe mozilla i epiphany - o innych mi nie wiadomo.
Jabber 2 - Serwer typu Instant Messaging
Wstęp
Protokóģ jabber sģuŋy gģównie do przesyģania wiadomoķci typu Instant Messaging (czyli dziaģa podobnie jak inne znane komunikatory np. icq, tlen, gadu-gadu itp.). Zaletą jabbera jest to, ŋe jest otwarty, zapewnia darmową i peģną infrastrukturę (serwery, a takŋe klienty) dla osób prywatnych i uŋytkowników komercyjnych. Charakteryzuje się takŋe duŋym bezpieczeņstwem - rozmowy, a takŋe komunikacja między serwerami moŋe byæ szyfrowana.
W PLD jest kilka serwerów obsģugujących komunikację protokoģu XMPP, który jest fundamentem Jabbera - zatwierdzonym przez IETF w formie RFC (RFC od 3920 do 3923). Uŋywany przez wielu ISP jabberd w wersji 1.4, zdobywający popularnoķæ ejaberd czy opisywany poniŋej jabberd w wersji 2.0.
Opisana zostanie podstawowa konfiguracja, umoŋliwiająca poģączenia szyfrowane, a do skģadowania danych przez jabberd2 wykorzystamy silnik SQL Postgresql.
Instalacja
Pakiet jabberd2 instalujemy za pomocą poldka:
poldek> install jabber-common jabberd |
Oczywiķcie, jeŋeli do tej pory nie mamy zainstalowanego Postgresql naleŋy zainstalowaæ go takŋe. Naleŋy pamiętaæ, ŋe jabberd2 moŋe wspóģpracowaæ takŋe z MySQL, sqlite3, a takŋe znacznie prostrzą wersją bazy db.
Konfiguracja DNS i rekordów SRV
Zanim zaczniemy, musimy stworzyæ domenę, która jednoznacznie będzie wskazywaģa na maszynę Jabbera. Dodamy takŋe rekordy SRV, które sģuŋą do zapytaņ domenowych przez demony Jabbera.
Przykģad konfiguracji zostanie przedstawiony dla serwera nazw Bind. Zmian dokonujemy w odpowiednim pliku stref w katalogu /var/lib/named/M.
; Jabber jabber IN A 10.1.1.1 ;Tu wpisujemy IP naszej domeny _jabber._tcp.jabber IN SRV 20 0 5269 domena.org. _xmpp-server._tcp.jabber IN SRV 20 0 5269 domena.org. _xmpp-client._tcp.jabber IN SRV 20 0 5222 domena.org. |
Oczywiķcie nie moŋemy zapomnieæ o zmianie rekordu serial w strefie domeny i restarcie demona named
Konfiguracja portów (jeŋeli korzystamy z firewall-a)
W przypadku wykorzystwania zapór ogniowych w systemie powinniķmy otworzyæ porty tcp dla następujących portów:
5222 - Dla komunikacji klienckiej (poģączenie nieszyfrowane)
5223 - Dla komunikacji klienckiej (poģączenie szyfrowane SSL)
5269 - Dla komunikacji między serwerami Jabbera
5347 - Dla komunikacji między serwerami Jabbera, wykorzystany przez dodatkowe transporty (np. transport GG)
Pamiętaæ naleŋy, ŋe powyŋsze porty są ustalone umownie i w plikach konfiguracyjnych demona Jabber, a takŋe rekordach SRV moŋemy je zmieniæ (np. dla portu klienckiego ustaliæ port 80) - jednak zaleca się pozostawiæ proponowane wyŋej porty.
Oczywiķcie, jeŋeli nie chcemy aby nasz serwer byģ widoczny na zewnątrz naszej sieci (np. jest przeznaczony tylko dla wewnętrzej sieci intranetowej) nie otwieramy portu przeznaczonego do komunikacji między serwerami (u nas to porty 5269 i 5347).
Podstawowa konfiguracja Jabberd2
Moŋemy wreszcie skonfigurowaæ wstępnie usģugę jabberd2. Wszystkie pliki konfiguracyjne znajdują się w katalogu /etc/jabber.
W pliku /etc/jabber/c2s.xml w okolicy tagu "local" dodajemy naszą domenę:
<!-- Local network configuration -->
<local>
<!-- Who we identify ourselves as. This should correspond
to the ID (host) that the session manager thinks it is. You can
specify more than one to support virtual hosts, as long as you
have additional session manager instances on the network to
handle those hosts. The realm attribute specifies the auth/reg
or SASL authentication realm for the host. If the attribute is
not specified, the realm will be selected by the SASL
mechanism, or will be the same as the ID itself. Be aware that
users are assigned to a realm, not a host, so two hosts in the
same realm will have the same users.
If no realm is specified, it will be set to be the same as the
ID. -->
<id>jabber.domena.org</id> |
W pliku /etc/jabber/sm.xml w pierwszych linijkach takŋe dodajemy naszą domenę:
<sm>
<!-- Our ID on the network. Users will have this as the domain part of
their JID. If you want your server to be accessible from other
Jabber servers, this ID must be resolvable by DNS.s
(default: localhost) -->
<id>jabber.domena.org</id> |
Jeŋeli chcemy, aby nasz serwer komunikowaģ się z innymi serwerami w pliku /etc/jabber/jabberd.cfg kasujemy "#" w linijce z "s2s":
# After sm and c2s are configured to use a fully qualified domain name # and proper SRV records are set in DNS uncoment this to enable # communication # with other Jabber servers s2s /etc/jabber/s2s.xml |
Podstawowa konfiguracja jest juŋ zrobiona. Domyķlne ustawienie tzw. "storage" czyli sposobu trzymania przez jabbera informacji o uŋytkownikach jest zrobione w PLD w db. Przy maģej iloķci uŋytkowników jest to wystarczający sposób. Jednak przy większej ich iloķci, bardziej praktyczne jest trzymanie tych danych w bazie SQL.
Konfiguracja dla SQL (Postgresql)
Przy poprawnie dziaģającym postgresie, z uprawnionego dla niego uŋytkownika tworzymy bazę jabberd2
$ createdb -U postgres jabberd2 |
Następnie przypisujemy do tej bazy uŋytkownika jabberd2 i ustalamy dla niego hasģo i opcje dostępu do bazy:
$ createuser -P -U postgres jabberd2 Enter password for user "jabberd2": Enter it again: Shall the new user be allowed to create databases? (y/n) n Shall the new user be allowed to create more new users? (y/n) n CREATE USER |
Teraz musimy wypeģniæ nowoutworzoną bazę odpowiednimi tabelami i polami. Z katalogu /usr/share/doc/jabberd-2* naleŋy rozpakowaæ (najlepiej do katalogu uŋytkownika, który moŋe dziaģaæ na bazie postgresa) plik db-setup.pgsql.gz. Po rozpakowaniu przechodzimy do katalogu, gdzie zostaģ rozpakowany plik db-setup.pgsql i wykonujemy:
$ psql -U jabberd2 jabberd2 jabberd2=>\i db-setup.pgsql |
Baza postgresa jest gotowa. Poģączenie z bazą będzie odbywaæ się po localhost, tak więc musimy zadbaæ o to, ŋeby postgres umoŋliwiaģ takie poģączenie
Zostaģa nam jeszcze konfiguracja w plikach jabbera.
W pliku /etc/jabber/sm.xml szukamy sekcji "storage" i zmieniamy na:
<!-- Storage database configuration --> <storage> <!-- By default, we use the MySQL driver for all storage --> <driver>pgsql</driver> |
Dla porządku dodamy, ŋe zamiast pgsql, moŋemy takŋe wykorzytaæ: mysql, ldap, sqlite (w zaleŋnoķci od mechanizmu jaki wybraliķmy).
W tym samym pliku szukamy następnie sekcji "pgsql" aby w odpowiednim miejscu wpisaæ hasģo dostępu do bazy jabberd2. Moŋemy tam takŋe zmieniæ sposób dostępu:
<!-- PostgreSQL driver configuration -->
<pgsql>
<!-- Database server host and port -->
<host>localhost</host>
<port>5432</port>
<!-- Database name -->
<dbname>jabberd2</dbname>
<!-- Database username and password -->
<user>jabberd2</user>
<pass>tu_wpisujemy_hasģo_do_bazy</pass> |
Podobne zmiany wykonujemy w pliku /etc/jabber/c2s.xml. Umoŋliwiają one autentykacje uŋytkowników jabbera:
<!-- Authentication/registration database configuration --> <authreg> <!-- Backend module to use --> <module>pgsql</module> |
I dalej w tym samym pliku (sekcja "pgsql")
<!-- PostgreSQL module configuration -->
<pgsql>
<!-- Database server host and port -->
<host>localhost</host>
<port>5432</port>
<!-- Database name -->
<dbname>jabberd2</dbname>
<!-- Database username and password -->
<user>jabberd2</user>
<pass>tu_wpisujemy_hasģo_do_bazy</pass>
</pgsql> |
Po zrestartowaniu demona jabberd moŋemy się juŋ cieszyæ bardziej zaawansowaną funkcjonalnoķcią naszego komunikatora.
Szyfrowanie
Przed konfiguracją samego jabbera, musimy sprawdziæ czy mamy pakiet openssl i wygenerowaæ klucz:
# openssl req -new -x509 -newkey rsa:1024 -days 3650 -keyout privkey.pem -out server.pem |
sam parametr -days 3650 moŋemy ustawiæ na krótszy lub dģuŋszy (oznacza on dģugoķæ waŋnoķci certyfikatu - w naszym przypadku 10 lat).
Po wykonaniu powyŋszego polecenia i wpisaniu odpowiedzi na zadane pytania (zwróæmy tylko uwagę, abyķmy w polu Common Name wpisali naszą domenę, obsģugiwaną przez serwer jabbera) usuniemy hasģo z klucza prywatnego:
# openssl rsa -in privkey.pem -out privkey.pem |
Następnie poģączymy oba klucze w jeden plik i skasujemy klucz prywatny:
# cat privkey.pem >> server.pem # rm privkey.pem |
Zmieniamy nazwę naszego certyfikatu (dla porządku), przenosimy w odpowiednie miejsce i nadajemy prawa:
# mv server.pem /var/lib/openssl/certs/jabber.pem # chown root:jabber /var/lib/openssl/certs/jabber.pem # chmod 640 /var/lib/openssl/certs/jabber.pem |
Zostaģa nam jeszcze konfiguracja Jabbera. W pliku /etc/jabber/c2s.xml znajdujemy tag "ssl-port" i odkomentujemy go:
<!-- Older versions of jabberd support encrypted client connections
via an additional listening socket on port 5223. If you want
this (required to allow pre-STARTTLS clients to do SSL),
uncomment this -->
<ssl-port>5223</ssl-port>
</local> |
Zdejmujemy komentarz takŋe z tagu "require-starttls" (kilka linijek wyŋej):
<!-- Require STARTTLS. If this is enabled, clients must do STARTTLS
before they can authenticate. Until the stream is encrypted,
all packets will be dropped. -->
<require-starttls/> |
Teraz w kaŋdym z pięciu plików konfiguracyjnych znajdujących się w /etc/jabber tj. router.xml, sm.xml, resolver.xml, s2s.xml, c2s.xml znajdujemy zakomentowany ciąg wskazujący na nasz certyfikat:
<!-- <pemfile>/etc/jabber/server.pem</pemfile> --> |
Kasujemy komentarze (czyli <!-- i -->) i wpisujemy odpowiednią scieŋkę do naszego certyfikatu:
<pemfile>/var/lib/openssl/certs/jabber.pem</pemfile> |
Kolejny restart demona jabber i moŋemy cieszyæ się poģączeniami szyfrowanymi.
Zakoņczenie
Opisane powyŋej sposoby konfiguracji nie wyczerpują oczywiķcie wszystkich aspektów. Zachęcamy do odwiedzenia strony z oryginalną dokumentacją jabbera. Mimo, ŋe niektórym moŋe sprawiæ problem język angielski, to podane przykģady w jasny sposób omawiają takŋe zaawansowane zagadnienia.
MySQL - System Zarządzania Relacyjnymi Bazami Danych (ang. RDBMS)
Co to jest MySQL?
MySQL jest Systemem Zarządzania Relacyjnymi Bazami Danych. Znany i ceniony jest przede wszystkim ze względu na swoją niebywaģą wydajnoķæ i szybkoķæ dziaģania. Ķwietnie nadaje się do obsģugi projektów internetowych, ale nie tylko - z powodzeniem uŋywany jest równieŋ w wielkich projektach informatycznych organizacji, takich jak chociaŋby NASA. Przeciwnicy MySQL'a często mówią, jak to bardzo brakuje mu wielu ficzerów, które posiadają prawdziwe, duŋe systemy baz danych. Ze swojego doķwiadczenia wiem, ŋe częķæ z tych ludzi nawet nie rozróŋnia wersji systemu, które oferuje nam firma MySQL AB (producent MySQL).
Ogólne cechy MySQL
Napisany w C i C++ (wydajnoķæ!).
API dla wielu języków programowania: C, C++, Eiffel, Java, Perl, PHP, Python, Ruby, Tcl.
Peģna wielowątkowoķæ, korzystająca z wątków kernela. Oznacza to, ŋe MySQL będzie pracowaģ na maszynie wieloprocesorowej, jeķli tylko taką posiadasz.
Opcjonalna obsģuga transakcji.
B-drzewa z kompresowanymi indeksami. To wam się przyda, jakbyķcie mieli wieeeelkie bazy ;) Wystarczy powiedzieæ, ŋe znacząco wpģywa na czas wyszukiwania i pobierania danych (wierszy) z bazy.
Istnieje moŋliwoķæ "osadzenia" (ang. embed) serwera MySQL w aplikacji, którą piszemy. Jeķli ktoķ potrzebuje funkcjonalnoķci systemu baz danych, a niekoniecznie chce się bawiæ w klient-serwer, to czemu nie?
Duŋa liczba typów danych w kolumnach. Liczby, ciągi znakowe, obiekty binarne (BLOB), data & czas, typy wyliczeniowe, zestawy. Na uwagę zasģuguje fakt, ŋe w MySQL moŋemy daną kolumnę dostosowaæ do pewnej wielkoķci danych, które zamierzamy w niej przechowywaæ (np. TINYINT, a nie INT), tym samym uzyskujemy większą wydajnoķæ i mniejsze zuŋycie pamięci (równieŋ dyskowej). Istnieje moŋliwoķæ definiowania niektórych typów danych jako narodowych (róŋne standardy kodowania chociaŋby).
Obsģuga klauzul agregujących i grupujących SQL.
Zģączenia zewnętrzne (LEFT & RIGHT).
Komenda SHOW pozwalająca przeglądaæ informacje na temat baz, tabel i indeksów. Komenda EXPLAIN opisująca pracę optymalizatora zapytaņ.
Bardzo prosty (z punktu widzenia administratora) system zabezpieczeņ. Wszystkie hasģa są szyfrowane.
Poģączenia z serwerem przez: TCP/IP, ODBC, JDBC.
Lokalizacja (w sensie językowym) serwera. Komunikaty m.in. po polsku.
Instalacja
Instalację oprogramowania przeprowadzimy oczywiķcie z pomocą naszego poldka. Logujemy się jako root, bądž uŋywamy polecenia sudo, jeŋeli mieliķmy je skonfigurowane do tego celu. Pierwszą rzeczą, którą będziemy musieli zrobiæ, jest ķciągnięcie i zainstalowanie odpowiednich pakietów z repozytorium PLD. Moŋna zrobiæ to uŋywając zarówno trybu wsadowego, jak i interaktywnego. Podam oba sposoby, wybierz sobie ten, który bardziej Ci odpowiada :) (osobiķcie wolę tryb interaktywny, ze względu na tab-completion).
Najpierw uruchamiamy poldka. Moŋna podaæ mu flagę
-n, która oznacza žródģo, z którego
zamierzamy ķciągaæ pakiety. Jeķli nie podamy tej
flagi, wówczas poldek skorzysta z pierwszego žródģa
wpisanego do pliku
/etc/poldek.conf. Ja korzystam ze
sģowackiego serwera firmy Bentel Ltd., ale to nie ma
znaczenia.
Instalacja w trybie wsadowym
W trybie wsadowym poldka, instalacja wygląda następująco:
# poldek -n bentel -i mysql mysql-client mysql-libs |
Instalacja w trybie interaktywnym
W trybie interaktywnym poldka, instalacja wygląda tak:
# poldek -n bentel Wczytywanie ftp://spirit.bentel.sk/mirrors/PLD/[...]/packages.dir.gz... Przeczytano 5116 pakietów Wczytywanie /root/.poldek-cache/packages.dir.dbcache.var.lib.rpm.gz... Przeczytano 450 pakietów Witaj w poldkowym trybie interaktywnym. Wpisz "help" aby otrzymaæ pomoc. poldek> |
Teraz przystępujemy do instalacji pakietów MySQL:
poldek> install mysql mysql-client mysql-libs |
poldek sam zadba o speģnienie wymaganych zaleŋnoķci.
Konfiguracja MySQL
Ŋeby móc sprawnie (i bezpiecznie) uŋywaæ naszego ķwieŋo zainstalowanego serwera, musimy go odpowiedno skonfigurowaæ.
Otworzymy naszym ulubionym edytorem tekstu plik konfiguracyjny demona MySQL. W przypadku uŋycia edytora Vim wydajemy następującą komendę:
# vim /etc/mysql/clusters.conf |
Jeŋeli nie zamierzamy zmieniaæ lokacji, w której będzie u nas pracowaģ MySQL,
to po prostu odkomentujmy linijkę z MYSQL_DB_CLUSTERS,
a jeŋeli zamierzamy umieķciæ serwer MySQL w innym miejscu,
to naleŋy tą linijkę odkomentowaæ, ale dodatkowo zmieniæ ķcieŋkę.
# standard setting MYSQL_DB_CLUSTERS="/var/lib/mysql" |
Upewniamy się, ŋe jesteķmy zalogowani na konsoli jako root i wydajemy polecenie:
# /etc/rc.d/init.d/mysql init |
Polecenie to będzie nam potrzebne tylko przy pierwszym uruchomieniu serwera - sģuŋy ono zainicjalizowaniu klastra baz danych. Powiedzmy, ŋe nasz katalog jest "formatowany", ok? ;) Jeŋeli pojawiģby wam się bģąd, mówiący o duplikacie wpisu localhost-mysql dla klucza 1 - moŋecie go zignorowaæ.j
Teraz moŋemy przystąpiæ juŋ do edycji wģaķciwiego pliku konfiguracyjnego RDBMS. Uŋywając naszego ulubionego edytora otwieramy plik /var/lib/mysql/mysqld.conf
# vim /var/lib/mysql/mysqld.conf |
Teraz moŋemy przystąpiæ do jego edycji. Pierwszą grupą opcji, na jaką trafiamy jest:
# This section must be the first! [mysqld] datadir = /var/lib/mysql/mysqldb/db pid-file = /var/lib/mysql/mysqldb/mysql.pid port = 3306 socket = /var/lib/mysql/mysqldb/mysql.sock user = mysql |
datadir to oczywiķcie katalog, w którym skģadowane będą nasze bazy. Moŋna zostawiæ tak jak jest.
user to uŋytkownik "pod którym" będzie dziaģaģ nasz serwer, w sensie - uruchomienie serwera wygląda tak, jakby to ten uŋytkownik, reprezentowany przez zmienną user go uruchomiģ (proces naleŋy do niego). Moŋna zmieniæ, chociaŋ nie polecam. Nie zalecane jest wykorzystanie do tego uŋytkownika root!
To co nas natomiast bardzo interesuje, z dwóch względów, to opcja port.
Chodzi o dwa przypadki:
Chcemy umoŋliwiæ dostęp do naszego serwera baz danych z zewnątrz, a admin naszej sieci "ģaskawie" przekierowaģ nam jakiķ port z bramki na nasz komputer, ale niestety nie jest to port 3306, z którego standardowo korzysta MySQL. Edytujemy sobie opcje
portw ten sposób, ŋeby wskazywaģa na ten, który mamy dostępny.Mamy maszynę z zewnętrznym IP (taką, do której moŋna się podģączyæ z Internetu), nie blokowaliķmy jednak dostępu do MySQL, ale chcielibyķmy podnieķæ choæ troszeczkę poziom bezpieczeņstwa i udostępniæ serwer MySQL na innym porcie. Wybieramy i jakiķ i wpisujemy go jako wartoķæ opcji
port.
# Don't allow connections over the network by default skip-networking |
Jeŋeli chcemy zablokowaæ dostęp do serwera MySQL z
zewnątrz (z sieci), to... nie robimy nic. A jeķli
chcemy umoŋliwiæ innym komputerom ģączenie się z
naszym serwerem, to naleŋy wykomentowaæ (dodaæ #)
linijkę z skip-networking.
Gdyby nam się kiedyķ coķ popsuģo (zapomnieliķmy hasģa, nie moŋemy dostaæ się do bazy), to przyda się odkomentowanie tej opcji:
# Emergency option. Use only if you really need this. #skip-grant-tables |
Przydatną rzeczą (ale w sumie tylko, jeķli zamierzamy udostępniaæ bazy na zewnątrz), będzie wģączenie logowania poģączeņ i zapytaņ (zwalnia pracę serwera). Dodam, ŋe moŋna oczywiķcie zmieniæ standardową ķcieŋkę, do której zapisywane są logi.
# Log connections and queries. It slows down MySQL so # it's disabled by default # log = /var/log/mysql/log |
Opcje z grupy set-variable wpģywają bezpoķrednio na pracę i wydajnoķæ serwera, nie będę się więc w nie zagģębiaģ. To trochę trudniejszy temat. Jak ktoķ chce bardzo zoptymalizowaæ pracę swojego serwera, to polecam lekturę dokumentacji MySQL. Przydatna jest równieŋ znajomoķæ zagadnieņ relacyjnych baz danych i SQL'a. Przykģadowo zerkniemy na jedną zmienną:
#set-variable = max_connections=100 |
Odkomentowanie tej linijki pozwoli nam na ustawienie maksymalnej liczby poģączeņ, które nasz MySQL będzie mógģ przyjąæ i obsģuŋyæ w danej chwili. Wszystko zaleŋy od tego, w jakim celu uŋywamy naszego RDBMS - naleŋy postawiæ sobie pytanie - "ile osób moŋe chcieæ podģączyæ się do mojego serwera w jednej chwili i ile takich poģączeņ przypada ķrednio na jedną osobę?". Odpowiedž wpisujemy w zmienną max_connections. Innym pytaniem mogģoby byæ "czy skrypty obsģugujące moje strony www korzystają ze staģych (persistent) poģączeņ?"
Poniewaŋ "Polacy nie gęsi i swój język mają" odkomentujemy jeszcze jedną linijkę w pliku konfiguracyjnym, aby wģączyæ polskie komunikaty:
# Language language = polish |
W tej chwili nasz serwer powinien byæ juŋ skonfigurowany do pracy. Upewniamy się, ŋe jesteķmy zalogowani na konsoli jako root i wydajemy polecenie:
# /etc/rc.d/init.d/mysql start |
Wywoģanie tego skryptu startowego spowoduje uruchomienie demona MySQL w systemie. Upewnijmy się jeszcze, ŋe nasz serwer baz danych rzeczywiķcie "wstaģ":
# /etc/rc.d/init.d/mysql status MySQL cluster /var/lib/mysql: running |
Jak widaæ na zaģączonym obrazku serwer dziaģa. Poniewaŋ w tej chwili jest zainstalowany w sposób domyķlny i dlatego maģo bezpieczny, naleŋy ustawiæ jakieķ hasģo dla uŋytkownika mysql:
# mysqladmin -u mysql -S /var/lib/mysql/mysqldb/mysql.sock password 'naszehaslo' |
Po opcji -S podajemy scieŋkę do pliku mysql.sock,
który powinien znajdowaæ się w katalogu, w którym umieķciliķmy MySQL.
Demon MySQL
Demon MySQL standardowo startuje wraz z systemem, ale przydaje się znaæ dwie komendy. Aby wģączyæ lub wyģączyæ serwer, będąc zalogowanym jako root, bądž uŋywając komendy sudo, wydajemy polecenie:
# /etc/rc.d/init.d/mysql start | stop |
wstawiając oczywiķcie opcje start lub stop,
w zaleŋnoķci od tego, co chcemy zrobiæ.
mysqladmin
mysqladmin jest narzędziem, za pomocą którego
moŋemy tworzyæ i usuwaæ bazy oraz przeģadowywaæ konfigurację.
Nie będziemy go uŋywaæ do wyģączania serwera,
bo od tego jest skrypt omówiony powyŋej.
Narzędzie wywoģuje się poleceniem mysqladmin,
a flagi i argumenty (opcje) polecenia sģuŋą do wykonywania okreķlonych zadaņ.
Poniewaŋ wczeķniej zmieniliķmy hasģo dla uŋytkownika
mysql, winniķmy przy kaŋdym poleceniu dodaæ
-u mysql i -p na koņcu
(aby klient zapytaģ nas o hasģo), np tak dla komendy status:
# mysqladmin -u mysql status -p Enter password: Uptime: 6720 Threads: 1 Questions: 1 Slow queries: 0 Opens: 6 \ Flush tables: 1 Open tables: 0 Queries per second avg: 0.000 |
Kilka przydatnych komend:
create nazwabazy - tworzy nową bazę danych o nazwie nazwabazy.
drop nazwabazy - usuwa bazę danych o nazwie nazwabazy
flush-privileges albo reload - obie opcje robią to samo - przeģadowują tablice uprawnieņ. Powinniķmy wykonaæ przeģadowanie zawsze, gdy dodamy np nowego uŋytkownika do jakiejķ bazy, poniewaŋ do czasu przeģadowania takie konto jest nieaktywne.
mysqldump
mysqldump to program, sģuŋący do "zrzucania" danych - czyli do robienia kopii zapasowych. Polecenie to jest przydatne w przypadku wykonywania kopii zapasowych podczas aktualizacji MySQL czy teŋ przenoszenia danych na inny serwer.
Kilka przydatnych opcji:
--databases baza1 baza2...- zrzuca dane z baz, których nazwy podaliķmy w liķcie oddzielonymi spacjami.--all-databases- to samo co wyŋej ale dla wszystkich bazy.--add-drop-table- dodaje DROP TABLE do skryptów tworzących tabele z backup-u (jak będziemy przywracaæ dane). Przydatne, kiedy np chcemy przywróciæ juŋ istniejącą tabelę. Spowoduje to najpierw jej usunięcie, a następnie utworzenie od nowa z danych, które mieliķmy w kopii zapasowej. Ogólnie, ŋeby uniknąæ ewentualnych problemów z duplikatami wierszy, itp. warto tą opcję wģączyæ.--no-create-info- w kopii nie zostanie zawarta informacja o tworzeniu tabel (nazwy tabel, typy pól, indeksy itp.). Przydatne, jeŋeli chcemy zrobiæ kopię tylko danych, a nie caģej struktury bazy.--no-data- Ta opcja pozwala zapisaæ samą informację o strukturze bazy i tabel, nie zapisuje natomiast danych.--opt nazwabazy- tworzy kopię bazy nazwabazy wraz z rozszerzonymi informacjami MySQL, blokowaniem tabel, itd. Chyba najczęķciej stosowana opcja przy robieniu kopii zapasowych.
Naleŋy pamiętaæ, ŋe wynik polecenia mysqldump naleŋy przekierowaæ (>) do jakiegoķ pliku. Podam moŋe kilka przykģadów uŋycia tego programu. Zrzucenie zawartoķci bazy baza1 do pliku baza1_bkp.sql:
# mysqldump -u mysql --databases baza1 > baza1_bkp.sql -p |
Stworzenie kopii zapasowej struktury bazy (bez danych) baza2 i zapisanie jej w pliku baza2_str.sql:
# mysqldump -u mysql --databases --no-data baza2 > baza2_str.sql -p |
Niezwykle przydatną opcją jest --opt omówiona wczeķniej.
Polecam jej stosowanie do wykonywania kopii caģej bazy,
wģącznie ze strukturą tabel i samymi danymi.
Aby stworzyæ peģną kopię zapasową bazy baza1
i zapisaæ ją w pliku baza1_kopia.sql:
# mysqldump -u mysql --opt baza1 > baza1_kopia.sql -p |
Przywracanie baz wykonanych poleceniem mysqldump wygląda tak:
# mysql -u mysql baza1 < baza1_kopia.sql -p |
Inna metoda (w sumie róŋniąca się zapisem):
# mysql -u mysql -e 'source /sciezka_do_pliku/baza1_kopia.sql' baza1 -p |
NFS - Network File System
NFS jest to usģuga pozwalająca udostępniaæ zasoby dyskowe komputerom w sieci. Serwer udostępnia katalog(i) klientom, którzy mogą je podmontowaæ i dziaģaæ jak na lokalnym systemie plików. Ponadto moŋna z niego uruchamiaæ stacje bezdyskowe lub tworzyæ rozproszone systemy plików.
Serwer
Najpierw instalujemy demona portmap (o ile nie jest juŋ zainstalowany) oraz demona NFS poleceniem:
# poldek -i portmap nfs-utils |
Serwer NFS jest gotowy do pracy od razu po zainstalowaniu, wystarczy jedynie uruchomiæ usģugę portmap, a następnie nfs (dokģadnie w tej kolejnoķci). Teraz moŋemy przejķæ do konfiguracji udziaģów sieciowych. Do podstawowej pracy serwera nie ma potrzeby konfigurowania czegokolwiek, w pozostaģych wypadkach naleŋy przyjrzeæ się plikowi /etc/sysconfig/nfsd, który moŋe wyglądaæ następująco:
SERVICE_RUN_NICE_LEVEL="+0" #RPCMOUNTOPTIONS="--no-nfs-version 3" RPCNFSDCOUNT=8 NFSDTYPE=K |
SERVICE_RUN_NICE_LEVEL- ustala priorytet serwera#RPCMOUNTOPTIONS="--no-nfs-version 3"- opcja dla jąder z serii 2.2, dla wspóģczesnych kerneli powinna byæ zakomentowanaRPCNFSDCOUNT- podaje liczbę instancji serwera, czyli ilu klientów moŋe obsģuŋyæ jednoczeķnieNFSDTYPE- podaje czy serwer ma pracowaæ jako oddzielny demon (U), czy w trybie jądra (K). Zalecane jest to drugie z rozwiązaņ, gdyŋ zapewnia większą wydajnoķæ.
Modyfikacja pliku konfiguracji wymaga restartu uslugi.
Udostępnianie
Uruchomiliķmy serwer, teraz przyszedģ czas na udostępnienie zasobów. W pliku /etc/exports definiuje się udostępniane katalogi, ich listę podajemy w postaci wierszy, które mają następującą skģadnię:
$katalog $klient1($opcja1,$opcja2,...) $klient2($opcja1,$opcja2,...) |
$katalog - udostępniony katalog. Warto tutaj wspomnieæ, ŋe jeŋeli udostępniamy dany katalog to nie moŋemy udostępniæ w nowej reguģce katalogu będącego jego ojcem jak i synem, jeŋeli leŋą na tym samym systemie plików. Udostępnianie partycji FAT, itp. teŋ nie jest dobrym rozwiązaniem.
$klient - IP lub nazwa komputera, któremu udostępniamy katalog. Moŋna podaæ takŋe caģą sieæ, wtedy zezwolimy wszystkim komputerom w sieci na przeglądanie i/lub zapisywanie do katalogu.
$opcje - tutaj moŋemy ustaliæ m.in. czy zasób ma byæ udostępniony tylko do odczytu, czy takŋe do zapisu, oraz naģoŋyæ inne ograniczenia. Wszystkie opcje opisane są w manualu (man exports).
Oto przykģadowe wpisy do /etc/exports:
/srv/pub 192.168.0.1(ro) 192.168.0.2(rw) /home 192.168.0.0/255.255.255.0(rw) |
Pomijając sensownoķæ wpisów, pierwszy wiersz daje prawo odczytu katalogu /srv/pub komputerowi 192.168.0.1 i prawo odczytu i zapisu komputerowi 192.168.0.2. Drugi z kolei daje prawo zapisu do katalogu /home komputerom z podsieci 192.168.0.0/24. Jeŋeli modyfikujemy /etc/exports w trakcie pracy serwera to musimy poinformowaæ demona, ŋeby ponownie odczytaģ plik konfiguracji. Przed tym moŋemy sprawdziæ czy nasze wpisy są poprawne:
# exportfs -v |
Polecenie to wyķwietli listę katalogów gotowych do wyeksportowania, jeķli któryķ z udziaģów nie jest wyķwietlony, to prawdopodobnie popeģniliķmy jakiķ bģąd w skģadni. Gdy jesteķmy pewni, ŋe chcemy udostępniæ udziaģy NFS, to wydajemy polecenie:
# exportfs -rv |
W PLD stworzono grupę systemową fileshare, która ma prawo do modyfikowania konfiguracji udziaģów sieciowych (NFS i SMB), bez koniecznoķci posiadania praw root-a. Aby nadaæ uŋytkownikowi takie prawo wystarczy zapisaæ go do tej grupy, opis zarządzania grupami uŋytkowników opisano w sekcja Grupy w rozdziaģ Administracja.
Klient
Konfigurację klienta rozpoczynamy od zainstalowania i uruchomienia usģugi portmap. Jeķli chcemy, aby zasoby NFS byģy montowane w trakcie startu systemu, instalujemy pakiet nfs-utils-clients, dostarczający wymagany rc-skrypt: /etc/rc.d/init.d/nfsfs.
Teraz przyszedģ czas na poģączenie się z zasobem NFS, w tym celu musimy go zamontowaæ np.:
# mount serwer.net:/srv/pub /mnt/net -t nfs |
serwer.net to IP bądž nazwa naszego serwera, /srv/pub jest przykģadowym udostępnionym katalogiem na serwerze (wpisaliķmy go wczeķniej do /etc/exports). Katalog /mnt/net to przykģadowe miejsce podmontowania zasobu. Moŋna uŋyæ dodatkowo flagi -o a po niej podaæ potrzebne nam opcje montowania. Peģną listę opcji znajdziemy w podręczniku systemowym: man 5 nfs.
Jeķli nic nie stoi na przeszkodzie abyķmy podģączali zasób przy starcie systemu, to dodajemy wpis do /etc/fstab:
192.168.0.1:/srv/pub /mnt/net nfs rw,hard,intr 0 0 |
Wpis wygląda znajomo, ale uwagę zwracają opcje hard i intr. Otóŋ hard oznacza, ŋe programy korzystające z zasobów NFS w momencie awarii serwera zostaną zawieszone w oczekiwaniu na dostęp do danych i nie będzie moŋliwoķci ich odwieszenia w postaci polecenia kill, chyba, ŋe dodamy opcję intr dzięki czemu będziemy mogli zabiæ dany proces. Zamiast hard moŋemy uŋyæ opcji soft, jednak w przypadku awarii serwera NFS sygnalizuje bģąd programom korzystającym z zasobów. Wadą tego rozwiązania jest to, ŋe nie wszystkie programy potrafią poradziæ sobie z takim komunikatem i moŋe dojķæ do utraty danych.
Bezpieczeņstwo serwera
Musimy zadbaæ o bezpieczeņstwo naszego serwera, podstawowym sposobem zabezpieczania zasobu jest ograniczenie dostępu. Moŋemy go ograniczaæ za pomocą ustawieņ w pliku /etc/exports, za pomocą filtra pakietów lub plików /etc/tcpd/hosts.allow i /etc/tcpd/hosts.deny, co zostaģo przedstawione poniŋej.
Najpierw blokujemy wszystkim dostęp do naszych usģug wpisując do pliku pliku /etc/tcpd/hosts.deny:
portmap:ALL lockd:ALL mountd:ALL rquotad:ALL statd:ALL |
Następnie w /etc/tcpd/hosts.allow wpisujemy komputery, którym zezwalamy na korzystanie z wymienionych usģug. Moŋemy zarówno wpisaæ adresy IP komputerów jak i caģą podsieæ.
portmap: 192.168.0.0/255.255.255.0 lockd: 192.168.0.0/255.255.255.0 rquotad: 192.168.0.0/255.255.255.0 mountd: 192.168.0.0/255.255.255.0 statd: 192.168.0.0/255.255.255.0 |
NFS nie obsģuguje autoryzacji na poziomie uŋytkownika, a jedynie na poziomie hosta. Z tego względu nie bardzo nadaje się do udostępniania w Internecie, jeķli to tylko moŋliwe lepiej uŋyæ protokoģu FTP lub WebDAV.
Dostrajanie wydajnoķci
Wolne dziaģanie protokoģu NFS wskazuje przewaŋnie na brak odpowiedniego dostrojenia poģączenia, wystarczy ustawiæ kilka opcji by uzyskaæ zaskakująco duŋy wzrost wydajnoķci. Podane poniŋej zalecenia dotyczą konfiguracji klienta.
Na początek zajmiemy się opcjami rsize i wsize. Dzięki nim moŋemy zwiększyæ szybkoķæ odczytu i zapisu plików na serwer. Manual systemowy radzi by ustawiæ im na wartoķci: rsize=8192 i wsize=8192. Linijka w pliku /etc/fstab będzie wyglądaæ teraz następująco:
192.168.0.1:/usr/local /usr/local nfs rw,hard,intr,rsize=8192,wsize=8192 0 0 |
Domyķlnie NFS dziaģa w oparciu o protokóģ UDP, doķwiadczenie pokazuje jednak, ŋe przeģączenie w tryb TCP moŋe w niektórych wypadkach zwiększyæ szybkoķæ przesyģu danych. Niestety nie kaŋdy serwer NFS obsģuguje poģączenia TCP, więc nie wszędzie moŋemy uŋyæ tej opcji. Na szczęķcie PLD zawiera demona pozwalającego na uŋywanie TCP. Aby wģączyæ tą opcję do linijki w pliku /etc/fstab dodajemy wpis tcp np.:
192.168.0.1:/usr/local /usr/local nfs rw,hard,intr,tcp 0 0 |
W przypadku protokoģu NFS naleŋy trochę eksperymentowaæ z ustawieniami, na początek dobrym pomysģem moŋe byæ uŋycie obu powyŋszych wskazówek. Więcej o dostrajaniu NFS-a moŋna odnaležæ w podręczniku systemowym.
PDNS (Power DNS) - Serwer Nazw
Power DNS zwany w dalszej częķci tego dokumentu jako PDNS jest zaawansowanym i bardzo efektywnym serwerem nazw. Jego moŋliwoķci wspóģpracy z LDAP lub bazami SQL (Mysql i Postgresql) dają szerokie moŋliwoķci tworzenia skryptów lub interface zarządzających. Sam PDNS jest uwaŋany za zdecydowanie bezpieczniejszy niŋ Bind, a takŋe od niego szybszy - zwģaszcza przy większej iloķci obsģugiwanych domen.
Wstęp
W tym rozdziale zostanie omówiona podstawowa instalacja, konfiguracja z bazą Postgresql, a takŋe wstępna konfiguracja przykģadowej domeny. Oczywiķcie więcej szczegóģów moŋemy znaležæ w oryginalnej dokumentacji.
Instalacja
Instalacja przebiega standardowo za pomocą poldka.
poldek> install pdns |
Do poprawnego dziaģania naszej bazy potrzebujemy takŋe postgresql (moŋemy takŋe wykorzystaæ mysql lub ldap, a nawet pliki konfiguracyjne Bind-a). Tak więc jeŋeli nie mamy Postgresql to instalujemy go i poprawnie konfigurujemy.
Konfiguracja Postgresql dla PDNS
Następnym krokiem będzie stworzenie bazy obsģugiwanej przez PDNS w Postgresql. W tym celu moŋemy wykorzystaæ klienta dostarczanego razem z Postgresql - psql. Moŋemy takŋe do tego celu uŋyæ innych wygodnych narzędzi np. phpPgAdmin
Najpierw z konta uŋytkownika uprawnionego do operacji na bazie tworzymy bazę:
$ createdb -U postgres powerdns |
Tworzymy takŋe uŋytkownika dla w/w bazy:
$ createuser -P -U postgres pdns Enter password for user "pdns": Enter it again: Shall the new user be allowed to create databases? (y/n) n Shall the new user be allowed to create more new users? (y/n) n CREATE USER |
Teraz za pomocą swojego ulubionego klienta Postgresql wykonujemy poniŋsze polecenia SQL w celu stworzenia szkieletu bazy:
create table domains ( id SERIAL PRIMARY KEY, name VARCHAR(255) NOT NULL, master VARCHAR(20) DEFAULT NULL, last_check INT DEFAULT NULL, type VARCHAR(6) NOT NULL, notified_serial INT DEFAULT NULL, account VARCHAR(40) DEFAULT NULL ); CREATE UNIQUE INDEX name_index ON domains(name); CREATE TABLE records ( id SERIAL PRIMARY KEY, domain_id INT DEFAULT NULL, name VARCHAR(255) DEFAULT NULL, type VARCHAR(6) DEFAULT NULL, content VARCHAR(255) DEFAULT NULL, ttl INT DEFAULT NULL, prio INT DEFAULT NULL, change_date INT DEFAULT NULL, CONSTRAINT domain_exists FOREIGN KEY(domain_id) REFERENCES domains(id) ON DELETE CASCADE ); CREATE INDEX rec_name_index ON records(name); CREATE INDEX nametype_index ON records(name,type); CREATE INDEX domain_id ON records(domain_id); create table supermasters ( ip VARCHAR(25) NOT NULL, nameserver VARCHAR(255) NOT NULL, account VARCHAR(40) DEFAULT NULL ); GRANT SELECT ON supermasters TO pdns; GRANT ALL ON domains TO pdns; GRANT ALL ON domains_id_seq TO pdns; GRANT ALL ON records TO pdns; GRANT ALL ON records_id_seq TO pdns; |
Konfiguracja PDNS
W /etc/pdns/pdns.conf konfigurujemy dziaģanie programu PDNS. Przykģadowa konfiguracja PDNSa wspóģpracującego z bazą Postgresql moŋe wyglądaæ następująco:
#chroot=/some/where # If set, chroot to this directory for more security config-dir=/etc/pdns/ # Location of configuration directory (pdns.conf) launch=gpgsql # Launch this backend #gpgsql-socket=/var/lib/pgsql/postmaster.pid gpgsql-dbname=powerdns # Nazwa bazy danych w psql gpgsql-user=pdns # Uŋytkownik bazy w psql gpgsql-password=hasģo_do_bazy_pdns module-dir=/usr/lib/pdns # Default directory for modules #load-modules= # Load this module - supply absolute or relative path #local-address=0.0.0.0 # Local IPv4 address to which we bind #local-ipv6=:: # Local IPv6 address to which we bind #use-logfile=no # Use a log file or syslog #logfile=var/log/pdns.log # Logfile to use allow-recursion=IP_ZEWN_DNS/maska,IP_ZEWN_DNS/maska # Tu podajemy adresy zewn. serwerów DNS np. # allow-recursion=194.204.152.34/24,194.204.159.1/24 # nameserver setgid=djbdns # If set, change group id to this gid for more security setuid=pdns # If set, change user id to this uid for more security #slave=no # Act as a slave (Ustawiamy na YES w przypadku # pracy serwera PDNS jako SLAVE) socket-dir=/var/run # Where the controlsocket will live webserver=yes # Wģączenie usģugi monitorowania pracy PDNS przez WWW webserver-address=10.1.1.1 # Adres IP strony monitorującej pracę PDNS webserver-password=hasģo_do_strony_monitorującej webserver-port=8088 # port strony monitorującej |
Krzyŋyk "#" na początku oznacza komentarz bądž wyģączenie danej opcji. Oryginalne teksty komentarzy są na tyle czytelne, ŋe tylko niektóre opcje skomentowalismy po polsku.
Domeny
Praktycznie PDNS jest gotowy do pracy. Musimy jeszcze wypeģniæ treķcią bazę - czyli dodaæ domenę (domeny). Przykģadową domenę zaprezentujemy w formie tzw. "dump-a" bazy. Jest to na tyle czytelne, ŋe skomentowane zostaną tylko niektóre aspekty.
--
-- PostgreSQL database dump
--
SET client_encoding = 'UNICODE';
SET check_function_bodies = false;
SET client_min_messages = warning;
SET search_path = public, pg_catalog;
--
-- Name: domains_id_seq; Type: SEQUENCE SET; Schema: public; Owner: pdns
--
SELECT pg_catalog.setval(pg_catalog.pg_get_serial_sequence('domains', 'id'), 1, true);
--
-- Name: records_id_seq; Type: SEQUENCE SET; Schema: public; Owner: pdns
--
SELECT pg_catalog.setval(pg_catalog.pg_get_serial_sequence('records', 'id'), 16, true);
--
-- Data for Name: domains; Type: TABLE DATA; Schema: public; Owner: pdns
--
INSERT INTO domains VALUES (1, 'foo.com', NULL, NULL, 'NATIVE', NULL, NULL);
INSERT INTO domains VALUES (2, '1.1.10.in-addr.arpa', NULL, NULL, 'NATIVE', NULL, NULL);
-- W pierwszym ID podajemy domenę 'foo.com'
-- W drugim ID definiujemy domenę odwrotną dla danego IP
--
-- Data for Name: records; Type: TABLE DATA; Schema: public; Owner: pdns
--
-- Poniŋej zgodnie z okreķlonymi ID definiowane są kolejno strefy
INSERT INTO records VALUES (2, 1, 'localhost.foo.com', 'A', '127.0.0.1', 120, NULL, NULL);
INSERT INTO records VALUES (3, 1, 'www.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (5, 1, 'dns.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (6, 1, 'ftp.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (7, 1, 'poczta.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (8, 1, 'pop3.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (9, 1, 'smtp.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (10, 1, 'ssh.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (11, 1, 'jabber.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (1, 1, 'foo.com', 'SOA', 'localhost user.foo.com 1', 86400, NULL, NULL);
INSERT INTO records VALUES (16, 1, 'foo.com', 'TXT', 'Serwer PDNS', 300, NULL, NULL);
INSERT INTO records VALUES (17, 1, 'foo.com', 'NS', 'ns.foo.com', 300, NULL, NULL);
INSERT INTO records VALUES (4, 1, 'mail.foo.com', 'A', '10.1.1.1', 120, NULL, NULL);
INSERT INTO records VALUES (18, 1, 'foo.com', 'MX', 'mail.foo.com', 300, 5, NULL);
INSERT INTO records VALUES (19, 1, 'foo.com', 'A', '10.1.1.1', 300, 0, NULL);
-- Poniŋej definiujemy rekordy SRV dla serwera Jabber
INSERT INTO records VALUES (12, 1, '_jabber._tcp.jabber.foo.com',
'SRV', '0 5269 foo.com', 300, 10, NULL);
INSERT INTO records VALUES (13, 1, '_xmpp-server._tcp.jabber.foo.com',
'SRV', '0 5269 foo.com', 300, 10, NULL);
INSERT INTO records VALUES (14, 1, '_xmpp-client._tcp.jabber.foo.com',
'SRV', '0 5222 foo.com', 300, 10, NULL);
-- Domena odwrotna
INSERT INTO records VALUES (15, 2, '1.1.1.10.in-addr.arpa', 'PTR', 'foo.com', 86400, NULL, NULL);
INSERT INTO records VALUES (20, 2, '1.1.10.in-addr.arpa',
'SOA', 'localhost root.localhost', 86400, NULL, NULL);
INSERT INTO records VALUES (21, 2, '1.1.10.in-addr.arpa', 'NS', 'nc.foo.com', 86400, NULL, NULL);
--
-- Data for Name: supermasters; Type: TABLE DATA; Schema: public; Owner: pdns
--
--
-- PostgreSQL database dump complete
-- |
Wszelkie zmiany lub dodawanie nowych domen moŋemy wykonywaæ na bazie danych lub wykorzystując do tego odpowiednie skrypty. Teraz moŋemy uruchomiæ demona PDNS wykorzystując skrypt:
# /etc/init.d/pdns start |
Naleŋy pamiętaæ, ŋe jeŋeli wczeķniej uŋywalismy BINDa bądž innnego demona do obsģugi nazw domenowych, naleŋy go przed uruchomieniem PDNS wyģączyæ.
Po uruchomieniu serwisu moŋemy za pomocą przeglądarki http wejķæ na stronę monitorującą pracę PDNS (odpowiednie opcje dotyczące tej usģugi znajdziemy w /etc/pdns/pdns.conf). Wywoģanie zgodne z przykģadowym wpisem w pdns.conf to http://10.1.1.1:8088. Na stronie tej moŋemy odnaležæ wiele cennych informacji dotyczących pracy naszego serwera nazw.
Postfix - Transport poczty elektronicznej (MTA)
Postfix jest MTU czyli w wielkim skrócie demonem poczty elektronicznej. No tak, w sumie powiecie ķciągamy poldkiem instalujemy i dziaģa... dziaģa ale chcemy coķ więcej... chcemy by nasz smtpd byģ ģadnie skonfigurowany.
Zaczynamy
Ķciągamy to co nam będzie potrzebne. Wiadomo... postfix i dodatki, które mu są potrzebne:
poldek -i postfix cyrus-sasl cyrus-sasl-plain cyrus-sasl-saslauthd \
cyrus-sasl-login |
A tutaj coķ co będzie nam potrzebne do tworzenia certyfikatów.
poldek -i openssl-tools |
A tutaj coķ ŋebyķmy mogli pobraæ pocztę z serwera.
poldek -i tpop3d inetd rc-inetd |
Konfiguracja
Przyszedģ czas na konfigurację postfix-a.
# echo 'pwcheck_method:saslauthd' > /etc/sasl/smtpd.conf |
Naleŋy jeszcze sprawdziæ czy w /etc/pam.d/ znajduje się plik smtp, jeŋeli nie to naleŋy przegraæ na to miejsce przykģadowy konfig z /usr/share/doc/cyrus-sasl-saslauthd-*/cyrus.pam.gz , rozpakowaæ i nazwaæ plik smtp.
Uruchom saslauthd:
# /etc/rc.d/init.d/saslauthd start |
Uruchom postfix-a:
# /etc/rc.d/init.d/postfix start |
Teraz chcemy, ŋeby postfix wymagaģ autentykacji:
# postconf -e smtpd_sasl_auth_enable=yes
# postconf -e smtpd_recipient_restrictions=permit_mynetworks, \
reject_sender_login_mismatch,permit_sasl_authenticated, \
reject_unauth_destination |
Teraz linijka dla popsutych Outlook-ów.
# postconf -e broken_sasl_auth_clients=yes # postconf -e mynetworks=127.0.0.0/8,192.168.1.1/32 |
Restart postfix-a:
# /etc/rc.d/init.d/postfix restart |
No i to wszystko razem powinno wyglądaæ tak:
# postconf -n
alias_database = hash:/etc/mail/aliases
alias_maps = hash:/etc/mail/aliases
biff = no
broken_sasl_auth_clients = yes
command_directory = /usr/sbin
config_directory = /etc/mail
daemon_directory = /usr/lib/postfix
debug_peer_level = 2
default_privs = nobody
mail_owner = postfix
mail_spool_directory = /var/mail
myhostname = networking.ee
mynetworks = 127.0.0.0/8, 192.168.1.1/32, 192.168.1.1/32
myorigin = $myhostname
queue_directory = /var/spool/postfix
setgid_group = maildrop
smtpd_recipient_restrictions = permit_mynetworks, \
reject_sender_login_mismatch,permit_sasl_authenticated, \
reject_unauth_destination
smtpd_sasl_auth_enable = yes |
Szyfrowanie
Wģączamy teraz szyfrowanie wysyģania poczty oraz transmisji między MX-ami dla róŋnych domen
Następnie generujemy certyfikat SSL. Podczas generowania certyfikatu będziesz musiaģ odpowiedzieæ na kilka prostych pytaņ.
Robimy to w sposób następujący:
# openssl genrsa -out key.pem 1024 # openssl req -new -x509 -key key.pem -out cert.pem # cat cert.pem >> key.pem; mv -f key.pem cert.pem # cp cert.pem /var/lib/openssl/certs/nasza.domena.pl.pem |
Do pliku /etc/mail/main.cf naleŋy dodaæ 4 linijki, takie jak poniŋej:
smtpd_tls_cert_file = /var/lib/openssl/certs/nasza.domena.pl.pem smtpd_tls_key_file = $smtpd_tls_cert_file smtpd_use_tls = yes smtp_use_tls = yes |
W pliku /etc/mail/master.cf naleŋy zastąpiæ aktualną linijkę czyli tą z domyķlnej instalacji:
#smtps inet n - n - - smtpd
na naszą aktualną:
smtps inet n - y - - smtpd -o smtpd_tls_wrappermode=yes \
-o smtpd_sasl_auth_enable=yes |
Domeny
Jeŋeli posiadamy więcej niŋ jedną domenę na serwerze to w /etc/mail/main.cf dopisujemy:
mydestination = $myhostname, jakas.domena.pl, \
costam.gdziestam.pl, PLD.biz.pl |
Jeŋeli chcemy aby nasz postfix obsģugiwaģ wirtualne domeny (przyznawaģ się do nich) dopisujemy w /etc/mail/main.cf takie trzy linijki:
relay_domains = hash:/etc/mail/domains virtual_maps = hash:/etc/mail/virtual smtpd_sender_login_maps = hash:/etc/mail/virtual |
Tworzymy /etc/mail/domains i robimy nastepujące wpisy:
# plik domains, w nim wpisane domeny dla których nasz serwer #pocztę będzie przyjmowaģ. pld-linux.org relay 81.0.225.27 relay |
Do /etc/mail/virtual dopisujemy na przykģad coķ takiego:
# plik virtual, w nim wpisane są konta w domenach które obsģugujemy # schemat wpisu # ktostam.nazwisko@domena.pl konto_w_systemie rafal.drozd@networking.ee grifter rafal.drozd@jakas.domena.pl grifter rafal.drozd@costam.gdziestam.pl grifter rafal.drozd@PLD.biz.pl grifter virusalert@networking.ee grifter # to ostatnie będzie nam póžniej do amavisa potrzebne :) |
Teraz musimy wklepaæ
# postmap /etc/mail/domains # postmap /etc/mail/virtual |
No i restart postfixa
# /etc/rc.d/init.d/postfix restart |
Usprawnienia
Dodatkowe wpisy które poprawią pracę naszego postfix-a Edytujemy /etc/mail/main.cf i dodajemy następujące wpisy:
disable_vrfy_command = yes # liczba odbiorców max 100 dla jednego maila smtpd_recipient_limit = 100 smtpd_error_sleep_time = 5 smtpd_hard_error_limit = 10 smtpd_helo_required = yes # ogranicz do 2 mega [2000000] wielkoķæ przesyģki, wģaķciwie mając \ # dobre ģącze moŋna # wpisaæ 10 mega [10000000] message_size_limit = 2000000 # spam fight! :> header_checks = regexp:/etc/mail/header_checks mail_name = PLD - $myhostname smtpd_banner = $myhostname ESMTP $mail_name. We block/report all spam. smtpd_soft_error_limit = 60 default_process_limit = 3 maps_rbl_domains = relays.ordb.org smtpd_client_restrictions = reject_maps_rbl |
Tworzymy /etc/mail/header_checks i dopisujemy:
/^To: .*friend@public/ REJECT Header-To address revoked \
due to too much spam.
/^Subject: ADV\W/ REJECT Header-Subject beginning with \
"spam" ADV tag rejected. |
Koņcowa konfiguracja
# postconf -n
alias_database = hash:/etc/mail/aliases
alias_maps = hash:/etc/mail/aliases
biff = no
broken_sasl_auth_clients = yes
command_directory = /usr/sbin
config_directory = /etc/mail
daemon_directory = /usr/lib/postfix
debug_peer_level = 2
default_privs = nobody
default_process_limit = 3
disable_vrfy_command = yes
header_checks = regexp:/etc/mail/header_checks
mail_name = PLD - $myhostname
mail_owner = postfix
mail_spool_directory = /var/mail
maps_rbl_domains = relays.ordb.org
message_size_limit = 2000000
myhostname = networking.ee
mynetworks = 127.0.0.0/8,192.168.1.1/32
myorigin = $myhostname
queue_directory = /var/spool/postfix
relay_domains = hash:/etc/mail/domains
setgid_group = maildrop
smtp_use_tls = yes
smtpd_banner = $myhostname ESMTP $mail_name. We block/report all spam.
smtpd_client_restrictions = reject_maps_rbl
smtpd_error_sleep_time = 5
smtpd_hard_error_limit = 10
smtpd_helo_required = yes
smtpd_recipient_limit = 100
smtpd_recipient_restrictions = permit_mynetworks, \
reject_sender_login_mismatch,permit_sasl_authenticated, \
reject_unauth_destination
smtpd_sasl_auth_enable = yes
smtpd_soft_error_limit = 60
smtpd_tls_cert_file = /var/lib/openssl/certs/nasza.domena.pl.pem
smtpd_tls_key_file = $smtpd_tls_cert_file
smtpd_use_tls = yes
virtual_maps = hash:/etc/mail/virtual
smtpd_sender_login_maps = hash:/etc/mail/virtual |
Zawartoķæ master.cf
# grep -v ^# /etc/mail/master.cf
smtp inet n - n - - smtpd
smtps inet n - y - - smtpd -o smtpd_tls_wrappermode=yes \
-o smtpd_sasl_auth_enable=yes
pickup fifo n - n 60 1 pickup
cleanup unix n - n - 0 cleanup
qmgr fifo n - n 300 1 qmgr
rewrite unix - - n - - trivial-rewrite
bounce unix - - n - 0 bounce
defer unix - - n - 0 bounce
flush unix n - n 1000? 0 flush
smtp unix - - n - - smtp
showq unix n - n - - showq
error unix - - n - - error
local unix - n n - - local
virtual unix - n n - - virtual
lmtp unix - - n - - lmtp
cyrus unix - n n - - pipe flags=R user=cyrus \
argv=/usr/lib/cyrus/deliver -e -m ${extension} ${user}
uucp unix - n n - - pipe flags=Fqhu user=uucp \
argv=uux -r -n -z -a$sender - $nexthop!rmail ($recipient)
ifmail unix - n n - - pipe flags=F user=ftn \
argv=/usr/lib/ifmail/ifmail -r $nexthop ($recipient)
bsmtp unix - n n - - pipe flags=Fq. user=foo \
argv=/usr/local/sbin/bsmtp -f $sender $nexthop $recipient |
tpop3d
tpop3d, czyli coķ dzięki czemu będziemy mogli pobraæ pocztę z serwera.
No i wģączamy tpop3d-a
# /etc/rc.d/init.d/tpop3d start |
amavis + mks
Przystępujemy do instalacji i konfiguracji amavisa + mks :)
Instalujemy poldkiem mks, serwer mksd, bazy, oraz skrypt aktualizujący bazy
poldek -i mks mksd mks-bases mks-updater mksd-clients |
Teraz ķciągamy jakiegoķ wirusa i sprawdzamy czy mks32 dziaģa...
# wget http://www.eicar.org/download/eicar.com # mks32 eicar.com mks_vir: init... 1.9.0 for Linux i386, 2003.07.02 mks_vir: database version 2003 7 11 13 23 mks_vir: init OK, scan mode mks_vir: check file(s) mks_vir: file: eicar.com mks_vir: --heuristic for virus Eicar.Test mks_vir: --heuristic for virus Eicar.Test mks_vir: status: virus found: eicar.com mks_vir: exit code: 0x01 |
Jeķli dostaliķcie coķ takiego, tzn. ŋe wszystko jest ok ;)
Teraz przetestujemy czy mksd dziaģa poprawnie.
# /etc/rc.d/init.d/mksd start # mkschk /root/skaner/eicar.com VIR Eicar.Test /root/skaner/eicar.com |
Jeķli dostaģeķ coķ takiego, tzn. ŋe wszystko jest okej. mksd przyķpiesza znacznie pracę na sģabych maszynach... wtedy znacznie odczujesz.
Instalujemy teraz amavisa
poldek -i amavisd-new |
No i teraz najgorsze ;)
Edytujemy /etc/amavisd.conf
Odkomentuj linię:
@bypass_spam_checks_maps = (1); # uncomment to DISABLE anti-spam code |
Pozmieniaj odpowiednie linie
$mydomain = 'twoja.domena.pl'; # (no useful default) $daemon_user = 'amavis'; # (no default; customary: vscan or amavis) $daemon_group = 'amavis'; # (no default; customary: vscan or amavis) |
Moŋemy tutaj ustawiæ uŋytkownika amavis. Dodatkowo naleŋy dopisaæ mksd do grupy amavis, dzięki czemu będzie on mógģ korzystaæ z katalogów z częķciami maili amavisa.
# grep amavis /etc/group amavis:x:116:mksd |
Zakomentuj linię:
#$unix_socketname = "$MYHOME/amavisd.sock"; # amavis helper protocol socket |
Jeķli nie chcesz ŋeby amavis uŋywaģ pewnych pakerów to zakomentuj odpowiednie linie, np.
#$unrar = 'unrar'; |
Usuņ wszystkie wpisy na temat antywirusów (@av_scanners = ) i zastąp to wpisem z pliku README z archiwum mksd:
['MkS_Vir daemon',
'mksscan', '-s -Q {}',
[0], [1..7],
qr/^... (\S+)/
], |
Usuņ wpisy z @av_scanners_backup =
W swoim systemie pocztowym (postfix) utwórz uŋytkownika (lub alias) "virusalert" lub pozmieniaj wpisy:
$mailfrom_notify_admin $mailfrom_notify_recip $virus_admin |
My zrobiliķmy wczeķniej aliasa dla virusalert ;)
Ja sobie jeszcze dopisaģem:
$hdrfrom_notify_sender = $mailfrom_notify_admin; |
Jeķli nie chcesz aby nadawcy listów oraz admini dostawali informacje o wirusach w domyķlnym języku (English) to odkomentuj linie i zrób wģasne wpisy w /var/amavis/*.txt
# $notify_sender_templ = read_text('/var/amavis/notify_sender.txt');
# $notify_virus_sender_templ=read_text('/var/amavis/notify_virus_sender.txt');
# $notify_virus_admin_templ = read_text('/var/amavis/notify_virus_admin.txt');
# $notify_virus_recips_templ=read_text('/var/amavis/notify_virus_recips.txt');
i zmieņ
#$bdy_encoding = 'iso-8859-1'; # (default: 'iso-8859-1')
na
$bdy_encoding = 'iso-8859-2'; # (default: 'iso-8859-1') |
Wedģug licencji powinieneķ umieķciæ w notify_sender.txt reklamę http://www.mks.com.pl gdyŋ jest do warunek licencji na uŋywanie mks. Na koņcu pliku /usr/sbin/amavisd znajdują się przykģadowe szablony.
W pliku /etc/mail/master.cf dopisujemy nową linię:
localhost:10025 inet n - n - - smtpd |
No i restart postfix-a, amavisd-a i mks
# /etc/rc.d/init.d/postfix restart # /etc/rc.d/init.d/mksd restart # /etc/rc.d/init.d/amavisd restart |
Teraz testujemy amavis-a:
# telnet 127.0.0.1 10024 Trying 127.0.0.1.10024... Connected to localhost. Escape character is '^]'. 220 [127.0.0.1] ESMTP amavisd-new service ready MAIL FROM: <root> 250 2.1.0 Sender root OK RCPT TO: <root> 250 2.1.5 Recipient root OK DATA 354 End data with <CR><LF>.<CR><LF> Subject: test bez wirusa test . 250 2.6.0 Ok, id=29569-01, from MTA: 250 Ok: queued as A1017FD1E |
Dostaģeķ 250? To znaczy, ze amavisd sprawdziģ przesyģkę :) nie wierzysz? tail -n 100 -f /var/log/maillog
A teraz sprawdzimy jak reaguje na przesyģkę z wirusem:
# telnet 127.0.0.1 10024 Trying 127.0.0.1.10024... Connected to localhost. Escape character is '^]'. 220 [127.0.0.1] ESMTP amavisd-new service ready MAIL FROM: <root> 250 2.1.0 Sender root OK RCPT TO: <root> 250 2.1.5 Recipient root OK DATA 354 End data with <CR><LF>.<CR><LF> Subject: test z wirusem X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H* . 250 2.5.0 Ok, but 1 BOUNCE |
No i znalazģ wirusa :) w logach mamy:
Jul 14 04:17:43 networking amavis[29569]: (29569-02) INFECTED (Eicar.Test),
<root> -> <root>, quarantine virus-20030714-041716-29569-02, \
Message-ID: , Hits: - |
Teraz jeszcze maģa obróbka plików cf od postfix-a ;)
Edytujemy /etc/mail/master.cf
Linijkę:
smtp inet n - n - - smtpd
zamieniamy na:
smtp inet n - n - - smtpd -o \
content_filter=smtp-amavis:[127.0.0.1]:10024
|
oraz dodajemy jeszcze:
smtp-amavis unix - - n - 2 smtp -o smtp_data_done_timeout=1200 -o disable_dns_lookups=yes |
Restart postfix-a:
# /etc/rc.d/init.d/postfix restart |
i powinno wszystko nam pięknie lataæ:)
Wyķlij sobie eicar.com w zaģączniku a zobaczysz, ŋe smtp odrzuci i dostaniesz maila z alertem :]
PostgreSQL - Baza danych SQL
Co to jest PostgreSQL
PostgreSQL : The most advanced Open Source database system in the world
PostgreSQL: Najbardziej zaawansowany system zarządzania bazą danych na ķwiecie typu OpenSource - w taki oto sposób grupa rozwijająca SZBD PostgreSQL reklamuje swój produkt. SZBD PostgreSQL jest implementacją języka SQL, która zawiera w sobie bardzo wiele jego elementów, a na dodatek wprowadza wiele wģasnych rozszerzeņ. Porównywany z mySQL oddaje mu pola przy maģych instalacjach, które w prosty, a szybki sposób mają obsģugiwaæ bazę danych - typu maģe portale internetowe, proste bazy, i tym podobne. Jednakŋe SZBD PostgreSQL dostaje skrzydeģ w większych projektach, jest często porównywany do bardzo rozbudowanego SZBD Oracle. Cechy SZBD PostgreSQL to między innymi:
osadzane języki proceduralne wykonywane przez bazę danych (plperl, pl/perlu, plpgsql, plpython, pltcl, pl/tcl)
moŋliwoķæ tworzenia funkcji w PostgreSQLu w języku C, kompilowanych do bibliotek dynamicznych
sterowniki dostępu do bazy z języków C, C++, python, perl, czy Java (poprzez JDBC), ODBC
wysoce zaawansowana implementacja standardu SQL, obejmująca SQL/92
obsģuga BLOB (Binary Large OBjects) -- duŋych obiektów binarnych, takich jak pliki graficzne, itp.
obsģuga pól typu AUTOINCREMENT jako SERIAL lub SEQUENCE
licencję BSD, która umoŋliwia zamykanie kodu SZBD PostgreSQL przy dokonywaniu modyfikacji, co jest istotne w rozwiązaniach biznesowych
Instalacja pakietów
Uruchamiamy program poldek:
# poldek |
Wykonujemy:
poldek>ls -l postgresql-* |
Przykģadowy wynik to:
poldek> ls -l postgresql-* package build date size postgresql-7.4-0.8 2003/12/16 20:45 8.8 MB postgresql-backend-devel-7.4-0.8 2003/12/16 20:45 1.4 MB postgresql-clients-7.4-0.8 2003/12/16 20:45 1.5 MB postgresql-devel-7.4-0.8 2003/12/16 20:45 93.0 KB postgresql-doc-7.4-0.8 2003/12/16 20:45 5.3 MB postgresql-ecpg-7.4-0.8 2003/12/16 20:45 479.0 KB postgresql-ecpg-devel-7.4-0.8 2003/12/16 20:45 17.0 KB postgresql-libs-7.4-0.8 2003/12/16 20:45 252.0 KB postgresql-module-pgcrypto-7.4-0.8 2003/12/16 20:45 91.0 KB postgresql-module-plperl-7.4-0.8 2003/12/16 20:45 30.0 KB postgresql-module-plpgsql-7.4-0.8 2003/12/16 20:45 100.0 KB postgresql-module-plpython-7.4-0.8 2003/12/16 20:45 35.0 KB postgresql-module-pltcl-7.4-0.8 2003/12/16 20:45 44.0 KB postgresql-static-7.4-0.8 2003/12/16 20:45 303.0 KB postgresql-tcl-7.4-0.8 2003/12/16 20:45 38.0 KB postgresql-tcl-devel-7.4-0.8 2003/12/16 20:45 0.0 KB postgresql-tcl-static-7.4-0.8 2003/12/16 20:45 36.0 KB 17 packages, 18.6 MB poldek> |
Do poprawnego dziaģania SZBD PostgreSQL konieczne są następujące pakiety:
postgresql
postgresql-clients
postgresql-libs
Zatem moŋna przystąpiæ do ich instalacji, wpisując następujące polecenie:
# poldek -i postgresql postgresql-clients postgresql-libs |
Aby SZBD PostgreSQL skorzystaģ z wewnętrznych języków plpgsql czy teŋ plphpython naleŋy doinstalowaæ pakiety postgresql-module-plpgsql
# poldek -i postgresql-module-plpgsql |
oraz
root# poldek -i postgresql-module-plpython |
Konfiguracja PostgreSQLa w PLD
Wstępna konfiguracja
Edytujemy plik /etc/sysconfig/postgresql:
# vim /etc/sysconfig/postgresql |
I wybieramy odopowiednie podejķcie do bazy danych. Polecam standard setting. Po edycji wykonanie komendy
# grep PG_DB_CLUSTERS /etc/sysconfig/postgresql | egrep -v ^# |
powinno daæ wynik:
PG_DB_CLUSTERS="/var/lib/pgsql" |
Sortowanie po polsku
poldek -i localedb-src && localedb-gen -l pl_PL && echo LANG=pl_PL \
>>/etc/sysconfig/i18n |
TODO: locale tylko dla PostgreSQLa.
Inicjalizacja
Wykonujemy polecenie:
# service postgresql init |
Podczas inicjalizacji SZBD PostgreSQL stworzy pliki potrzebne mu do przechowywania tabel, tabele systemowe jak i bazy danych template0 i template1 konieczne do jego dalszego dziaģania. Inicjalizacja PostgreSQLa nie jest równoznaczna z jego uruchomieniem, o czym dalej.
Konfiguracja PostgreSQLa
W punkcie (3) (<- TODO, shufla docbook lame) zostaģ zainicjalizowany cluster, w którym to moŋna dodawaæ bazy danych. Trzeba teraz odpowiednio skonfigurowaæ tenŋe cluster. Przyda się edycja plików ${PG_DB_CLUSTERS}/{postgresql.conf,pg_hba.conf}:
# vim /var/lib/pgsql/{postgresql.conf,pg_hba.conf} |
Przydatna opcja to tcpip_socket = true w pliku /var/lib/pgsql/postgresql.conf.
Dodanie uŋytkownika
# su - postgres -c 'psql template1'
template1=# CREATE USER uzytkownik WITH ENCRYPTED PASSWORD 'hasģo' \
CREATEUSER CREATEDB;
CREATE USER |
Uŋytkownik `uzytkownik' będzie miaģ moŋliwoķæ tworzenia baz danych (za pomocą createdb lub CREATE DATABASE z poziomu psql) jak i dodawania uŋytkowników (createuser lub CREATE USER z poziomu psql).
Ostatni test
$ psql -h 127.0.0.1 template1
template-1=# SELECT count(*) FROM pg_database;
count
-------
2
(1 row) |
Dodatki
Warto wģączyæ obsģugę PostgreSQLa w PHP, instalując pakiet php-pgsql, równieŋ w perl-u perl-DBD-Pg lub perl-Pg, oraz w python-ie python-postgresql. Pakiet postgresql-devel jest przydatny przy pisaniu aplikacji w C/C++ korzystających z PostgreSQLa. Dokumentacja do PostgreSQLa znajduje się, a jakŋe, w pakiecie postgresql-doc.
# poldek -i php-pgsql # poldek -i perl-DBD-Pg # poldek -i perl-Pg # poldek -i python-postgresql # poldek -i postgresql-devel # poldek -i postgresql-doc |
Odnoķniki
/usr/share/doc/postgresql-*/FAQ_polish.gz - Lokalna wersja FAQ, instalowana z pakietem postgresql (moŋe byæ takŋe w oddzielnej paczce z dokumentacją).
ProFTPD - serwer FTP
Wstęp
Duŋą zaletą ProFTPD jest jego prostota. Plik konfiguracyjny demona do zģudzenia przypomina ten od Apache. Jego zrozumienie nie powinno sprawiaæ trudnoķci.
Instalacja
Zanim przystąpisz do instalacji powinieneķ zdecydowaæ w jakim trybie ma pracowaæ usģuga. Jako demon, czy ma byæ uruchamiana poprzez superserwer inetd. Tryb inetd polega na tym, ŋe proces proftpd zostanie uruchomiony dopiero po odebraniu przez inetd ŋądania o tę usģugę. Natomiast w trybie daemon ProFTPD jest uruchomiony caģy czas i pracuje niezaleŋnie od inetd. Tak więc, jeŋeli Twój komputer, który przeznaczysz na serwer nie jest zbyt szybki, powinieneķ wybraæ ProFTPD uruchamianego poprzez inetd. Dystrybucja udostępnia obie te moŋliwoķci. Pakiet proftpd-inetd zapewnia uruchamianie poprzez inetd, natomiast po zainstalowaniu usģugi z pakietu proftpd-standalone uruchamiana ona będzie w trybie daemon. W opisie posģuŋymy się wersją daemon. Instalujemy pakiet proftpd-standalone
Podstawowa konfiguracja demona
Jak juŋ wspomniaģem we wstępie, ProFTPD jest jednym z prostszych w konfiguracji programów serwerowych. Wszystkie pliki potrzebne do jego skonfigurowania znajdują się w katalogu /etc/ftpd.
# ls -1 /etc/ftpd ftpusers proftpd.conf |
W pliku ftpusers znajduje się lista uŋytkowników, którym odebrana zostaģa moŋliwoķæ logowania się do serwera ftp. Poszczególne pozycje z tej listy zakoņczone są znakiem nowej linii, tak więc kaŋda pozycja jest rozmieszczona jedna pod drugą. Natomiast plik proftpd.conf zawiera wģaķciwą konfigurację usģugi.
ServerName "ProFTPD" ServerIdent off ServerType standalone DeferWelcome off DefaultServer on DefaultRoot ~ |
ServerNameokreķla nazwę serwera wyķwietlaną ģączącym się z nim uŋytkownikom.ServerIdentpozwala na wyķwietlenie wiadomoķci powitalnej podczas poģączenia, np. zawartoķci pliku .message. Domyķlnie wyģączona.ServerTypeustawia tryb pracy demona ProFTPDDeferWelcomeNie pokazuje wiadomoķci powitalnej dopóki uŋytkownik się nie zautoryzuje.DefaultServerOkreķlamy konfigurację jako domyķlnąDefaultRootWyznaczamy nadrzędny dla kaŋdego uŋytkownika katalog spoza którego nie będzie mógģ wyjķæ. W listingu powyŋej będzie to katalog domowy.
Poniŋej znajduje się szereg zakomentowanych opcji pozwalających na konfigurację poģączeņ bezpieczną metodą przy uŋyciu SSL. Jeŋeli jesteķ zainteresowany ich uŋyciem powinieneķ zapoznaæ się z dokumentacją on line serwera ProFTPD. Przechodzimy teraz do dalszej konfiguracji.
Port 21 Umask 022 User ftp Group ftp AuthPAMAuthoritative on |
PortDefiniujemy tutaj port na którym serwer będzie oczekiwaģ nadchodzących poģączeņUmaskTryb umask 022 jest typowym standardem dla ogolnie dostępnych plików i katalogówUserKonto uŋytkownika na którego uprawnieniach pracuje usģugaGroupGrupa do której naleŋy konto uŋytkownika usģugiAuthPAMAuthoritativeDajemy moŋliwoķæ autoryzacji uŋytkowników poprzez moduģ PAM jeķli jest to moŋliwe.
Przedstawione tutaj wartoķci poszczególnych opcji są domyķlnie ustawiane w pliku konfiguracyjnym w trakcie instalacji pakietu. Jak najbardziej moŋesz z nich korzystaæ. Na pewno nie powinieneķ zmieniaæ takich ustawieņ jak uŋytkownik czy grupa, port oraz sposób autoryzacji.
Konfiguracja dostępu
<Directory /> AllowOverwrite on </Directory> |
Zezwalamy na nadpisywanie plików w obrębie katalogu do którego uŋytkownik się zaloguje. Poniŋej
w pliku znajduje się przykģadowa konfiguracja dla uŋytkownika anonimowego. Sekcja mieķci się
wewnątrz znacznika <Anonymous ~ftp></Anonymous>.
Poniŋszy wykaz omawia najczęķciej wykorzystywane dyrektywy w tej sekcji.
User ftp Group ftp AnonRequirePassword off RequireValidShell off |
User- konto uŋytkownika którego prawa będzie uzyskiwaģa osoba logująca się do serweraGroup- grupa do której naleŋy powyŋsze konto.AnonRequirePassword- w powyŋszym przykģadzie wyģączona. Umoŋliwia uŋytkownikom anonimowym logowanie się bez hasģa.RequireValidShell- opcja ta powoduje, ŋe ProFTPD nie sprawdza czy dany uŋytkownik, który się loguje posiada przypisaną w /etc/shells powģokę.
UserAlias anonymous ftp MaxClients 10 DisplayLogin welcome.msg DisplayFirstChdir .message AllowStoreRestart on |
UserAlias- przyporządkowuje nazwę uŋytkownika do systemowego konta. W przykģadzie anonymous zostaģ przypisany kontu ftp.MaxClients- iloķæ jednoczesnych poģączeņ anonimowych które będą realizowane przez serwer.DisplayLogin- okreķlamy plik którego zawartoķæ będzie wyķwietlana po starcie.DisplayFirstChdir- plik którego zawartoķæ będzie wyķwietlana po pierwszym wejķciu do katalogu.AllowStoreRestart- pozwala klientom wznawiaæ upload.
<Limit WRITE> DenyAll </Limit> |
Zabraniamy klientom pisania do katalogu /home/services/ftp/pub.
<Directory /home/services/ftp/pub/Incoming> <Limit READ> DenyAll </Limit> <Limit WRITE> AllowAll </Limit> <Limit STOR> AllowAll </Limit> </Directory> |
Katalogowi Incoming zostaģy precyzyjnie okreķlone prawa dostępu. W powyŋszym przykģadzie kaŋdy ma dostęp do zapisu w tym katalogu natomiast nikt nie posiada prawa do jego odczytywania.
Zakoņczenie
Dostęp do serwera ftp moŋemy ograniczaæ na kilka sposobów. Moŋna limitowaæ iloķæ jednoczesnych poģączeņ, stworzyæ listę adresów IP, które będą miaģy prawo do zapisu czy odczytu okreķlonych katalogów.
Na tym zakoņczymy podstawową konfigurację serwera ProFTPD. Więcej informacji na jego temat znajdziesz na stronach z jego dokumentacją.
Samba - wspóģpraca z Windows
Samba jako Serwer domeny NT4 (PDC)
W tym rozdziale przedstawiona zostanie konfiguracja samby w roli serwera domeny Microsoft Windows NT4 (PDC).
Instalacja
Do realizacji tego zadania potrzebne będą pakiety: samba i samba-clients. Znaczenie poszczególnych pakietów:
samba - pakiet ten zawiera serwer samby
samba-clients - zestaw narzędzi przydatnych w poruszaniu się w ķrodowisku Microsoft Networks.
Proces instalacji pakietów przedstawiony zostaģ w dziale Zarządzanie pakietami.
Konfiguracja
Przy uŋyciu dowolnego edytora otwieramy plik /etc/samba/smb.conf. Caģą konfigurację naleŋy wykonaæ w sekcji [global]. Przyjęta w nim zostaģa następująca konwencja: <opcja> = <wartoķæ>. Jeŋeli dana opcja ma kilka wartoķci,
oddziela się je znakiem spacji. Poszczególne opcje umieszczane są w osobnych liniach. Komentarze w pliku rozpoczynają się znakiem "#" lub ";". Poniŋej znajduje się wykaz najwaŋniejszych opcji które naleŋy ustawiæ podczas realizacji zadania.
workgroup = DOM server string = File Server announce as = NT Server |
Ustawiamy nazwę domeny której czģonkiem będzie nasz serwer oraz opcjonalnie komentarz (opis) komputera i typ serwera (opcjonalnie).
domain logons = yes domain master = yes preferred master = yes local master = yes wins support = yes os level = 255 |
Ustawiamy logowanie do domeny oraz bycie kontrolerem domeny Windows NT4 i gģówną przegladarką komputerów w sieci.
security = user |
Okreķlamy poziom bezpieczeņstwa. Nasza konfiguracja wymaga ustawieņ zabezpieczeņ na poziomie uŋytkownika.
nt acl support = yes nt pipe support = yes |
Ustawiamy
time server = yes |
Ustawiamy bycie serwerem czasu (opcjonalnie).
Następnie restartujemy SAMBĘ i przystępujemy do dalszej konfiguracji. W bazie uŋytkowników Samby musi znaležæ się konto administratora. Będzie ono wymagane przy doģączaniu stacji klienckich do domeny.
# smbpasswd -a root New SMB password: Retype new SMB password: Added user root. |
Hasģo roota Samby nie powinno byæ identyczne z hasģem administratora systemu! następnie tworzymy konta uŋytkowników - podobnie jak przy zwykģym serwowaniu plików, tak i tutaj potrzebujemy nie tylko wpisu w bazie Samby, ale i konta uniksowego.
# useradd -g users jurek |
Pamiętajmy teŋ o utworzeniu wpisu w bazie uŋytkowników Samby:
# smbpasswd -a jurek |
następnie ustawiamy mapowanie grup w linux na odpowiednie grupy windows-a, poleceniem net groupmap. Domyķlne ustawienia Samby (mapowanie na uniksową grupę -1) wymaga zmiany, którą wprowadzi polecenie net groupmap add:
# net groupmap add ntgroup="Domain Admins" unixgroup=domadmin type=d Updated mapping entry for Domain Admins |
Podobnie modyfikujemy wpisy dla grup Domain Users - decydując się na wybór grupy users oraz Domain Guests - nobody: net groupmap.
# net groupmap add ntgroup="Domain Users" unixgroup=users type=d Updated mapping entry for Domain Users # net groupmap add ntgroup="Domain Guests" unixgroup=nobody type=d Updated mapping entry for Domain Guests # net groupmap add ntgroup="Users" unixgroup=users type=d Add mapping entry for Users |
Sprawdžmy, czy zmiany będą widoczne:
# net groupmap list ... Domain Admins (S-1-5-21-353545269-2518139598-3611003224-512) -> domadmin Domain Users (S-1-5-21-353545269-2518139598-3611003224-513) -> users Domain Admins (S-1-5-21-353545269-2518139598-3611003224-514) -> nobody Users (S-1-5-21-353545269-2518139598-3611003224-3001) -> users .. |
Praca komputera w domenie wymaga zaģoŋenia mu konta - tzw. Machine Trust Account. Jest to specyficzne konto, gdyŋ jego hasģo ustalane jest przy podģączaniu komputera do domeny i znane tylko parze klient-serwer. Dzięki temu istnieje moŋliwoķæ sprawdzenia toŋsamoķci próbującego się logowaæ komputera - nawet gdy ktoķ doģączy maszynę o tej samej nazwie, to nie powinien uzyskaæ moŋliwoķci dostępu do domeny. Nazwy kont odpowiadają nazwom NetBIOS komputerów, ale z doģączonym na koņcu symbolem dolara. Dla stacji biuro będzie to więc biuro$. Konto to powinno byæ zablokowane, by niemoŋliwe byģo uzyskanie dostępu poprzez ssh, czy teŋ inne usģugi systemu operacyjnego. Nie jest takŋe konieczny katalog domowy, w zamian za to zdecydujemy się na umieszczenie kont w grupie machines - pozwoli to w jakimķ stopniu ogarnąæ szybko zwiększającą się liczbę uŋytkowników systemu serwera.
# groupadd machines # useradd -c "Komputer biurowy" -g machines -d /dev/null -s /bin/false biuro$ # passwd -S biuro$ Password locked. |
Wydaje się, ŋe powinniķmy teraz utworzyæ odpowiedni wpis w bazie haseģ Samby - nie jest to jednak konieczne. Przy próbie podģączenia komputera do domeny czynnoķæ ta zostanie wykonana automatycznie. Gdy jednak zajdzie potrzeba ręcznego utworzenia wpisu, do wywoģania smbpasswd dodaæ musimy parametr -m (machine):
# smbpasswd -a -m ksiegowosc |
W tym przypadku nie podajemy symbolu $. Oczywiķcie caģy proces dodawania kont maszyn moŋna zautomatyzowaæ w tym celu naleŋy dodaæ do /etc/samba/smb.conf:
add machine script = /usr/sbin/useradd -d /var/lib/nobody -g machines -c 'Konto Maszyny %I' -s /bin/false %u passwd chat debug = no passwd chat = *New*UNIX*password* %n\n *ReType*new*UNIX*password* %n\n *passwd:*all*authentication*tokens*updated*successfully* passwd program = /usr/bin/smbpasswd -L -a %u |
i oczywiķcie utworzyæ katalog /var/lib/nobody
# mkdir /var/lib/nobody |
naleŋy sie teŋ upewniæ czy nie mamy w smb.conf wpisu
# kto nie moze sie logowac do samby invalid users = root |
Aby dodaæ Windows XP Profesional lub Microsoft Windows NT Server 4.0 Standard Edition (wersja Home nie obsģuguje modelu domenowego w ŋaden sposób) naleŋy w rejestrze zmieniæ:
REGEDIT4
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\netlogon\parameters
"RequireSignOrSeal"=dword:00000000
lub z poziomu Local Group Policy wyģączając (Disabled) Security Options | Domain Member | Digitally encrypt or sign secure channel data (always)
wiecej:
/usr/share/doc/samba-doc/Registry/WinXP_SignOrSeal.reg
Brian Getsinger (Apple Corp). Mac OS X Server Samba Primary Domain Controller Configuration http://www.afp548.com/Articles/system/sambapdc.html Sherlock Error logging a Win XP machine into a domain running Samba.
Serwer czģonkowski domeny NT4
W tym rozdziale przedstawiona zostanie konfiguracja samby w roli serwera czģonkowskiego domeny Microsoft Windows NT4. Zaletą takiej konfiguracji jest moŋliwoķæ budowania polityki praw dostępu do zasobów zgromadzonych na serwerze w oparciu o konta uŋytkowników lokalnego serwera PDC.
Instalacja
Do realizacji tego zadania potrzebne będą trzy pakiety: samba, samba-clients oraz samba-winbindd. Znaczenie poszczególnych pakietów:
samba - pakiet ten zawiera serwer samby
samba-clients - zestaw narzędzi przydatnych w poruszaniu się w ķrodowisku Microsoft Networks.
samba-winbindd - demon pozwalający na pobieranie uprawnieņ z serwera PDC.
Proces instalacji pakietów przedstawiony zostaģ w dziale Zarządzanie pakietami.
Konfiguracja
Przy uŋyciu dowolnego edytora otwieramy plik /etc/samba/smb.conf. Caģą konfigurację z której będzie
równieŋ korzystaģ demon winbindd naleŋy wykonaæ w sekcji [global]. Przyjęta w nim zostaģa następująca konwencja: <opcja> = <wartoķæ>. Jeŋeli dana opcja ma kilka wartoķci,
oddziela się je znakiem spacji. Poszczególne opcje umieszczane są w osobnych liniach. Komentarze w pliku rozpoczynają się
znakiem "#" lub ";". Poniŋej znajduje się wykaz najwaŋniejszych opcji które naleŋy
ustawiæ podczas realizacji zadania. Wykraczają one nieco poza czystą konfigurację winbindd ale są
konieczne do jego prawidģowego dziaģania.
workgroup = DOM server string = File Server |
Ustawiamy nazwę domeny której czģonkiem będzie nasz serwer oraz opcjonalnie komentarz (opis) komputera.
security = domain |
Okreķlamy poziom bezpieczeņstwa. Nasza konfiguracja wymaga ustawieņ zabezpieczeņ typu domenowego.
password server = PDC |
Nazwa netbiosowa serwera PDC. To z tego wģaķnie serwera demon winbind będzie pobieraģ uprawnienia.
To tyle, jeŋeli chodzi o ogólną konfigurację samby. Teraz czas na dodanie kilku opcji potrzebnych winbindowi.
winbind separator = + idmap uid = 10000-20000 idmap gid = 10000-20000 winbind enum users = yes winbind enum groups = yes client signing = yes |
winbind separator- znak, którym oddzielana będzie nazwa uŋytkownika bądž grupy od nazwy domeny. Np. "DOM+jan"idmap uid- zakres uidów w systemie zarezerwowanych na uŋytkowników domenowychidmap gid- zakres gidów w systemie przeznaczonych na grupy domenowe
Na tym moŋemy zakoņczyæ edycję pliku konfiguracyjnego samby. Aby nasza konfiguracja staģa się aktywna musimy przerestartowaæ usģugę.
/etc/rc.d/init.d/smb restart |
W ķlad za usģugą smb zostaną przerestartowane takŋe nmbd oraz interesujący nas winbindd. Czynnoķcią którą musimy bezwzględnie wykonaæ jest podģączenie naszego serwera do domeny. Aby to uczyniæ wykonujemy poniŋsze polecenie:
# net rpc join -S PDC -U Administrator%hasģo Joined the domain DOM |
Jeŋeli w tym momencie miaģbyķ problemy ze skomunikowaniem się z serwerem domeny moŋesz dodaæ do polecenia opcję -I a po niej adres
IP serwera PDC. Po pomyķlnej operacji podģączenia moŋemy sprawdziæ dziaģanie winbinda.
# wbinfo -g DOM+Administrator DOM+Basia DOM+Darek ... # wbinfo -g DOM+Domain Admins DOM+Domain Users ... |
Opcja -u pokazuje listę uŋytkowników, natomiast -g listę grup.
Jeŋeli wynik obu poleceņ wygląda podobnie jak na listingu oznacza to, ŋe winbind pracuje poprawnie.
Zakoņczenie
Jakie korzyķci pģyną z takiej konfiguracji samby? Otóŋ sprawdza się ona w ķrodowisku sieciowym w którym zasoby udostępniają zarówno serwery pracujące pod kontrolą Windows jak i linuksa. Pozwala to na budowanie spójnej polityki bezpieczeņstwa w oparciu o uwierzytelnianie uŋytkownika na poziomie domeny. Drugą z zalet jest prostota w implementacji. Dzięki winbindd dostęp do grup oraz uŋytkowników domenowych odbywa się w taki sam sposób jak do ich odpowiedników lokalnych.
# chown DOM+Administrator.DOM+Domain\ Users plik.txt |
Snort - Sieciowy System Wykrywania Wģamaņ
Snort to bardzo silny sieciowy system wykrywania ataków (ang. Network Intrusion Detection System, NIDS), który daje szeroki zakres mechanizmów detekcji, mogących w czasie rzeczywistym dokonywaæ analizy ruchu i rejestrowania pakietów w sieciach opartych na protokoģach IP/TCP/UDP/ICMP. Potrafi przeprowadzaæ analizę strumieni pakietów, wyszukiwaæ i dopasowywaæ podejrzane treķci, a takŋe wykrywaæ wiele ataków i anomalii, takich jak przepeģnienia bufora, skanowanie portów typu stealth, ataki na usģugi WWW, SMB, próby wykrywania systemu operacyjnego i wiele innych.
Wymagania
Przed instalacją Snorta warto zaopatrzyæ się w bazę danych (w opisie wykorzystano MySQL) i serwer Apache z obsģugą PHP. W bazie będą skģadowane logi, a za wygodny interfejs do przeglądania alarmów posģuŋy ACID (ang. Analysis Console for Intrusion Databases).
Instalacja Snorta i ACID
Gdy mamy juŋ bazę danych i serwer WWW z PHP, instalujemy następujące pakiety.
# poldek -i snort acid |
Przed konfiguracja ķrodowiska NIDS zakģadamy dwie bazy, dla Snorta i dla archiwum alarmów.
# mysql -u mysql -p Enter password: mysql> create database snort_log; Query OK, 1 row affected (0.01 sec) mysql> create database snort_archive; Query OK, 1 row affected (0.01 sec) mysql> quit |
Dodajemy tabele w taki sam sposób dla obu baz.
# gzip -d /usr/share/doc/snort-{wersja}/create_mysql.gz
# mysql -D snort_log -u mysql -p < \
/usr/share/doc/snort-{wersja}/create_mysql
# gzip -d /usr/share/doc/acid-{wersja}/create_acid_tbls_mysql.sql.gz
# mysql -D snort_log -u mysql -p < \
/usr/share/doc/acid-{wersja}/create_acid_tbls_mysql.sql
# mysql -D snort_archive -u mysql -p < \
/usr/share/doc/snort-{wersja}/create_mysql
# mysql -D snort_archive -u mysql -p < \
/usr/share/doc/acid-{wersja}/create_acid_tbls_mysql.sql |
Następnie (najproķciej przy uŋyciu popularnego narzędzia phpMyAdmin) tworzymy uŋytkownika i nadajemy mu prawa dla stworzonych baz.
Przechodzimy do edycji pliku /etc/acid_conf.php, w którym dodajemy parametry dla poģączenia się z bazami.
[...] /* Alert DB connection parameters */ [...] $alert_dbname = "snort_log"; $alert_host = "localhost"; $alert_port = "3306"; $alert_user = "login"; $alert_password = "haslo"; /* Archive DB connection parameters */ $archive_dbname = "snort_archive"; $archive_host = "localhost"; $archive_port = "3306"; $archive_user = "login.; $archive_password = "haslo"; [...] |
Teraz strona z interfejsem jest dostępna pod adresem http://twoje_ip/acid. Oczywiķcie dla bezpieczeņstwa zalecane jest zastosowanie protokoģu SSL do komunikacji z zasobem i autoryzacji poprzez pakiet apache-mod_auth.
Snort zaleŋnie od ķrodowiska w jakim dziaģa moŋe generowaæ duŋą iloķæ zbędnych alertów, te bardziej istotne moŋna przenosiæ do drugiej bazy za pomocą ACID, dla przejrzystoķci ogóģu.
Konfiguracja Snorta
Do dziaģania jako sieciowy system wykrywania wģamaņ, Snort potrzebuję sprecyzowania zasad funkcjonowania caģoķci w gģównym pliku konfiguracyjnym snort.conf. W starszych wersjach systemu, wszystkie opcje, ģącznie z reguģami ataków znajdowaģy się w jednym pliku. Ciągģa rozbudowa Snorta, rosnąca liczba sygnatur i ogólna funkcjonalnoķæ, wymusiģa rozdzielenie niektórych częķci konfiguracyjnych, w tym reguģ ataków. Przejrzystoķæ i spójnoķæ snort.conf zostaģa przywrócona przy uŋyciu polecenia include, którym doģącza się odpowiednie zestawy sygnatur i inne częķci konfiguracyjne, np.:
include: ķcieŋka_do_pliku/nazwa |
Bazy reguģ charakteryzują się nazwą pliku z koņcówką .rules, pierwszy czģon nazwy zawiera rodzaj usģugi lub typ ataku, którego dotyczy dany zestaw.
Pozostaģymi plikami konfiguracyjnymi są:
classification.config - zawierający klasyfikatory rodzajów ataków z nadanym priorytetem zagroŋenia, tak jak poniŋej:
config classification: web-application-attack,Web Application Attack,1
reference.config - posiadający skróty adresów do stron organizacji z bazą opisów ataków, np.:
config reference: bugtraq http://www.securityfocus.com/bid/
threshold.conf - metody ģagodzenia licznych, faģszywych alarmów,
unicode.map - zestaw kodowanych znaków unicode, na potrzeby preprocesora http_inspect.
Gģówny plik konfiguracyjny moŋna podzieliæ na cztery sekcje. Pierwsza, odpowiedzialna jest za ustalanie zmiennych var, wykorzystywanych w skģadni reguģ ataków.
Przyjmijmy ŋe docelowo Snort ma monitorowaæ dwie podsieci o adresach 192.168.1.0/24 i 192.168.2.0/24, jego pliki konfiguracyjne znajdują się bezpoķrednio w katalogu /etc/snort, a reguģki w /etc/snort/rules.
# Adres sieci lokalnej var HOME_NET [192.168.1.0/24,192.168.2.0/24] # Adres sieci zewnetrznej var EXTERNAL_NET !$HOME_NET # Lista adresow serwerow znajdujacych sie w strefie chronionej var DNS_SERVERS $HOME_NET var SMTP_SERVERS $HOME_NET var HTTP_SERVERS $HOME_NET var SQL_SERVERS $HOME_NET var TELNET_SERVERS $HOME_NET var SNMP_SERVERS $HOME_NET # Lista portow var HTTP_PORTS 80 var SHELLCODE_PORTS !80 var ORACLE_PORTS 1521 # Lista serwerow czat, komunikatorow var AIM_SERVERS [64.12.24.0/24,64.12.25.0/24,64.12.26.14/24,64.12.28.0/24,] # Scieŋka do katalogu z regulami atakow var RULE_PATH /etc/snort/rules |
W tej samej sekcji znajduje się zestaw parametrów
uruchomieniowych, zaczynających się od wyraŋenia
config (peģna
ich lista znajduję się w dokumentacji):
# wybor interfejsu do nasģuchu (jeden demon Snorta moze # obslugiwac tylko jeden interfejs sieciowy) config interface: eth0 |
Druga częķæ gģównego pliku konfiguracyjnego, zawiera ustawienia preprocesorów. Parametry domyķlne nie będą przedstawione w poniŋszym opisie. Kompletną listę opcji, moŋna znaležæ w dokumentacji Snorta. Oto przykģady ustawieņ preprocesorów:
Frag2:
# detect_state_problems . zwraca alarm przy pokrywaniu sie fragmentow. preprocessor frag2: detect_state_problems |
Stream4, Stream4_reassemble:
# disable_evasion_alerts - brak alarmow przy nakladaniu sie
#pakietow TCP, detect_scans - detektor prob cichego skanowania,
# detect_state_problems - detektor nienaturalnego zachowania
# pakietow.
preprocessor stream4: disable_evasion_alerts \
detect_scans detect_state_problems
# both - skladanie sesji TCP w obu kierunkach pomiedzy
# klientem i serwerem,
# ports - lista portow, na ktorych ma dzialac reasemblacja.
preprocessor stream4_reassemble: both ports [ 21 25 80 143 110 ] |
Http_inspect:
# iis_unicode_map - wskazuje plik z kodowaniem unicode i wybiera standardowe.
preprocessor http_inspect: global is_unicode_map unicode.map 1252
# profile - wybor profilu ustawien dla serwerow typu iis, apacze i all.
preprocessor http_inspect_server: server adres_IP_serwera_MS_IIS \
profile iis \
ports { 80 }
preprocessor http_inspect_server: server adres_IP_serwera_Apache \
profile apache \
ports { 80 } |
Powyŋszy przykģad przedstawia moŋliwoķæ profilowania ustawieņ dla poszczególnych serwerów, które podlegają ochronie. Serwery IIS i Apache, pracują w odmienny sposób, a zarazem posiadają inne sģabe punkty wykorzystywane podczas ataków. Operacja dostosowania ustawieņ skupia mechanizmy ochronne na odpowiednich metodach ataków dla danego typu serwera bądž ich grupy w danej sieci objętej ochroną.
RPC_decode, Back Orfice, Telnet_decode, Arpspoof, Performance Monito:
# alert_fragments . wlacza alarm, przy fragmentowaniu pakietow RPC,
# Domyķlne porty: 111 i 32771.
preprocessor rpc_decode: 111 32771 alert_fragments
preprocessor bo
preprocessor telnet_decode
preprocessor arpspoof
preprocessor arpspoof_detect_host: adresy_IP \
przypisane_do_nich_adresy_MAC
# console . wyswietlanie statystyk na ekranie,
# flow i events . statystyki badanego ruchu i ilosci dopasowanych
# regul,
# time . aktualizacja danych co 10s.
preprocessor perfmonitor: console flow events time 10 |
Flow i Flow-portscan:
# stats_interval . zapisywanie statystyk, 0 - wylaczone, # hash . wybor metody mieszania. preprocessor flow: stats_interval 0 hash 2 # server-watchnet . adresy IP, na ktorych flow bedzie # prowadzic badania, # server-learning-time . czas utrzymania punktow dla danego adresu IP, # server-scanner-limit . ilosc zapytan decydujacych o przyznaniu # statusu # skanowania z danego adresu, # src-ignore-net, dst-ignore-net . lista ignorowanych adresow docelowych # i zrodlowych. preprocessor flow-portscan: \ server-watchnet [xxx.xxx.xxx.xxx/xx] \ server-learning-time 14400 \ server-scanner-limit 10 \ src-ignore-net [xxx.xxx.xxx.xxx/xx, xxx.xxx.xxx.xxx/xx] \ dst-ignore-net [xxx.xxx.xxx.xxx/xx] |
Trzecia sekcja snort.conf, zawiera metody konfiguracji moduģów wyjķciowych, czyli róŋnych sposobów logowania wyników i tzw. akcji reguģ. Na potrzeby tego opisu wymieniony będzie tylko przykģad logowania do bazy MySQL.
output database: alert, mysql, user=login password=haslo \ dbname=snort_log host=127.0.0.1 |
Za pomocą reguģ akcji moŋna tworzyæ wģasne rodzaje reakcji na wykryte zdarzenie, np.:
ruletype czerwony_alarm
{
type log
# zapis do demona syslogd, lokalnie
output alert_syslog: LOG_ALER
}
# Przykladowa regula:
czerwony_alarm $HOME_NET any -> $HOME_NET 6667 (msg:"Internal \
IRC Server";) |
Czwarta, ostatnia częķæ, gģównego pliku konfiguracyjnego, zawiera odniesienia do zestawów reguģ i wczeķniej juŋ opisanych plików, classification.config, reference.config, threshold.conf (przykģad poniŋej).
include classification.config include reference.config include $RULE_PATH/bad-traffic.rules include $RULE_PATH/exploit.rules include $RULE_PATH/telnet.rules include $RULE_PATH/rpc.rules include $RULE_PATH/dos.rules (...) # dodatkowy zestaw regul Bleeding Snort - # http://www.bleedingsnort.com include $RULE_PATH/bleeding.rules include threshold.conf |
Dostosowanie Snorta do swoich potrzeb obejmuje, obok konfiguracji preprocesorów przede wszystkim decyzje, jakie zbiory reguģ mają byæ brane pod uwagę (czyli jakie pliki z reguģami mają byæ doģączane za pomocą polecenia include). W ķrodowisku, w którym wszystkie serwery WWW to Apache, reguģy chroniące serwer IIS będą generowaģy zupeģnie niepotrzebne alarmy. Jeķli nie udostępniamy FTP, reguģy opisujące ataki na tę usģugę będą tylko spowalniaģy pracę caģego systemu. To sprawy oczywiste, jednak wģaķciwe dostosowanie NIDS do swoich potrzeb wymaga wiele pracy. Dobranie odpowiednich dla danego ķrodowiska reguģ jest kluczowe dla dziaģania caģego systemu, duŋa iloķæ faģszywych alarmów nie tylko zuŋywa zasoby (kaŋda z reguģ musi byæ przecieŋ przeanalizowana), ale moŋe równieŋ bardzo skutecznie "zaciemniæ" obraz, sprawiając, ŋe prawdziwy atak moŋe przejķæ niezauwaŋony w zalewie informacji maģo istotnych. Obecna baza sygnatur liczy sobie okoģo 2500 reguģ i jest praktycznie kaŋdego dnia wzbogacana o nowe opisy ataków. Dla przybliŋenia występujących w bazie kategorii sygnatur, opiszę jakiego rodzaju ataki wykrywają:
attack-responses - odpowiedzi usģug na próbę ataku;
backdoor - dziaģalnoķæ tzw. tylnych drzwi, trojanów, rootkitów;
bad-traffic - nieprawidģowy ruch, np. na port 0;
chat - aktywnoķæ róŋnego rodzaju komunikatorów;
ddod, dos - zmasowane ataki Distributed Denial of Service (rozproszony atak typu - blokada usģugi);
deleted - reguģy przestarzaģe, wykasowane;
dns - ataki na usģugę Domain Name System;
experimental - zestaw eksperymentalnych reguģ;
exploit - programy mające na celu wykorzystywanie bģędów w oprogramowaniu;
icmp-info, icmp - komunikaty ICMP z róŋnych programów, testujących ruch;
imap, pop2, pop3, smtp - ataki na systemy pocztowe;
info - próby logowania na usģugi Telnet, Ftp;
local - zestaw wģasnych reguģ;
misc - róŋne, dotyczące usģug CVS, MS Terminal, BOOT, UPnP itd.;
multimedia - strumienie audio, wideo;
mysql, sql, oracle - ataki na znane serwer baz danych;
netbios - anomalia związane z protokoģem Netbios/SMB;
nntp - ataki na serwer grup dyskusyjnych;
other-ids - dziaģalnoķæ innych systemów IDS;
p2p - aktywnoķæ programów Peer to Peer;
policy - próby ataków na usģugi policy ftp itp.
porn - aktywnoķæ stron pornograficznych;
rpc - ataki na usģugi Remote Procedure Call;
finger, rservices, telnet - ataki na doķæ sģabo zabezpieczone usģugi uniksowe: finger, rlogin, rsh, rexec, telnet;
scan - róŋnego rodzaju techniki skanowania portów;
shellcode - wykorzystanie nieprawidģowego kodu do prób przepeģnienia bufora;
snmp - ataki na usģugi SNMP;
tftp, ftp - zdarzenia związane z przesyģaniem plików poprzez serwer ftp;
virus - transfer poczty z podejrzanym zaģącznikiem;
web-attacks, web-misc, web-client, web-cgi, web-php, web-coldfusion, web-frontpage, web-iis - ataki na róŋnego typu serwery WWW, przewaŋnie z wykorzystaniem bģędów w skryptach cgi, php;
x11 - aktywnoķci sesji serwera XFree86.
Aktualizacja reguģ
Do aktualizacji sygnatur posģuŋy nam perlowy skrypt Oinkmaster. Ma on duŋe moŋliwoķci które pozwalają w prosty sposób zarządzaæ reguģami Snorta. Wymagane pakiety do uruchomienia to: perl, perl-base, perl-modules i vixie-cron albo hc-cron .
Instalacja Oinkmaster
Ķciągamy archiwum tar, rozpakowujemy, skrypt wgrywamy do katalogu /usr/local/bin, a konfig do /etc:
# wget --passive-ftp \ ftp://ftp.it.su.se/pub/users/andreas/oinkmaster/oinkmaster-1.0.tar.gz # tar -zxvpf oinkmaster-1.0.tar.gz # cp oinkmaster-1.0/oinkmaster.pl /usr/local/bin/ # cp oinkmaster-1.0/oinkmaster.conf /etc/ |
Operacja aktualizacji odbywa się po następującej sekwencji komend:
# /usr/local/bin/oinkmaster.pl -o /etc/snort/rules/ |
Dodanie innego žródģa reguģ:
# /usr/local/bin/oinkmaster.pl -o /etc/snort/rules/ -q -u \ http://www.bleedingsnort.com/bleeding.rules.tar.gz |
Aby aktualizacja odbywaģa się automatycznie, w katalogu /etc/cron.daily tworzymy plik uprules.
# touch /etc/cron.daily/uprules # chmod 700 /etc/cron.daily/uprules |
I dodajemy do niego następującą zawartoķæ, podając adres e-mail na który ma zostaæ wysģany raport z codziennej aktualizacji jeķli pojawia się coķ nowego:
TMP=`mktemp /tmp/oinkmaster.XXXXXXXX` &&
(/usr/local/bin/oinkmaster.pl -o /etc/snort/rules/ \
-q > $TMP 2>&1;
if [ -s $TMP ]; then mail -s "Update Snort Rules" root@twoja_domena < $TMP; fi;
rm $TMP)
# dodatkowy zestaw regul Bleeding Snort - http://www.bleedingsnort.com
TMP=`mktemp /tmp/oinkmaster.XXXXXXXX` &&
(/usr/local/bin/oinkmaster.pl -o /etc/snort/rules/ -q -u \
http://www.bleedingsnort.com/bleeding.rules.tar.gz > $TMP 2>&1;
if [ -s $TMP ]; then mail -s "Update Bleeding Rules" \
root@twoja_domena < $TMP; fi; rm $TMP)
/etc/rc.d/init.d/snort restart |
Warto przyjŋeæ się bliŋej ciekawym funkcjonalnoķciom oinkmastera. W pliku konfiguracyjnym mamy moŋliwoķæ wyģączania poszczególnych reguģek po nr sid, dodawania do nich wģasnych modyfikacji itp. Wtedy jest pewnoķæ ŋe po aktualizacji, nasze zmiany w plikach reguģ nie będą nadpisywane.
Architektura Snorta
Snort jest logicznie podzielony na kilka komponentów, które wspóģpracują ze sobą by wykrywaæ ataki i generowaæ wyniki w odpowiednim formacie. Gģównymi skģadnikami systemu są: dekoder pakietów (sniffer), preprocesory, silnik detekcji i moduģ wyjķciowy.
W swej najprostszej formie Snort moŋe dziaģaæ jako sniffer. Przechwytuje pakiety z warstwy ģącza danych za pomocą biblioteki pcap. Rozpoznaje róŋne protokoģy modelu OSI - Ethernet, 802.11, Token Ring oraz wiele protokoģów dziaģających w wyŋszych warstwach jak: IP, TCP, UDP i ICMP. Surowe pakiety z warstwy ģącza danych (np. ramki Ethernetowe) po zdekodowaniu wądrują do preprocesorów (warstwa transportowa), gdzie są testowane i w razie koniecznoķci obrabiane na potrzeby silnika detekcji (warstwa sesji). Tam dokonywana jest analiza pakietów pod kątem zbioru zadanych reguģ. Następnie po wykryciu próby ataku bądž anomalii sieciowych, system przekazuje odpowiednie dane do moduģu wyjķciowego, który to decyduje o zapisaniu wyniku wykrycia w logach lub wszczęciu alarmu.
Tryby pracy
Snort umoŋliwia duŋą swobodę konfiguracji, za pomocą wielu parametrów, które pozwalają kontrolowaæ trzy podstawowe tryby pracy programu: sniffer, packet logger i network intrusion detection.
Sniffer Mode - wychwytuje wszystkie pakiety w danym segmencie sieci i przedstawia ich zawartoķæ na ekranie. Najprostszym sposobem uŋycia tego trybu jest uruchomienie programu z parametrem
-vw wyniku, czego Snort będzie wyķwietlaæ informacje o nagģówkach IP, TCP/UDP/ICMP. Do uzyskania bardziej szczegóģowych danych o wychwyconych pakietach, sģuŋą parametry-d(aby monitorowaæ ģadunek pakietów) i-e(dodatkowe nagģówki warstwy ģącza danych). Parametry moŋna ģączyæ razem, bez znaczenia jest ich kolejnoķæ (np. snort -ved). Aby zakoņczyæ pracę w tym trybie naleŋy uŋyæ sekwencji klawiszy CTRL+C.Packet Logger Mode - logowanie pakietów poprzez zapis na dysku. Czynnoķæ ta odbywa się po uŋyciu opcji
-l, którą wskazujemy katalog, gdzie Snort będzie zapisywaæ w odpowiednio nazwanych podkatalogach i plikach, zawartoķæ zebranych pakietów. Program potrafi takŋe zapisywaæ dane w formie binarnej tak jak robi to znany sniffer tcpdump. Sģuŋy do tego opcja-b, po jej uŋyciu nie trzeba stosowaæ dodatkowych kombinacji parametrów-ved, poniewaŋ format tcpdump, okreķla to, co ma byæ logowane (np. snort -b -l ./log). Uzyskane w ten sposób informacje, moŋna wykorzystaæ do póžniejszej analizy za pomocą programów rozpoznających format binarny tcpdump (np. Ethereal). Oczywiķcie moŋna tą samą czynnoķæ wykonaæ z wykorzystaniem Snorta, uŋywając opcji-r, po czym przetworzyæ sczytane pakiety dostępnymi trybami. Snort czytając swoje dzienniki (tak samo dziaģając w trybie sniffera) przyjmuje parametry w formacie BPF (Berkeley Packet Filter), dzięki którym moŋemy sprecyzowaæ (na podstawie nagģówków), jakie konkretnie pakiety chcemy obserwowaæ (np. okreķliæ adres hosta, protokóģ, port). Jeķli np. interesuje nas tylko ruch na porcie 80 moŋna uruchomiæ Snorta poleceniem: snort -r /var/log/snort/snort.log port www, jeķli chcemy wyķwietliæ tylko odpowiedzi serwera www: snort -vde src port www. Aby ignorowaæ caģy ruch z sieci np. 192.168.1.0 na port 80: snort -vde not ( src net 192.168.1 and dst port 80). Poģączenie Snorta z filtrami BPF znacznie zwiększa wydajnoķæ caģego systemu, gdyŋ filtrowanie BPF odbywa się w warstwie ģącza danych (a więc na poziomie biblioteki pcap). Okreķlając w ten sposób, jakie pakiety nas interesują (lub jakie chcemy zignorowaæ) moŋna doķæ dokģadnie "zawęziæ" obszar poszukiwaņ. Filtry BPF moŋna równieŋ zapisaæ w oddzielnym pliku i zaģadowaæ w trakcie uruchamiania Snorta parametrem-F: snort -r snort.log -F plik_z_bdf. Więcej na temat moŋliwoķci oferowanych przez BPF moŋna poczytaæ na stronach podręcznika zarówno Snorta, jak i Tcpdump.Network Intrusion Detection Mode - sieciowy system wykrywania wģamaņ. Jest najbardziej skomplikowanym trybem dziaģania programu. Za pomocą parametru
-c, wskazujemy plik konfiguracyjny, w którym okreķlane są zasady badania przechwyconego ruchu sieciowego, ustawienia preprocesorów, a takŋe zestaw sygnatur ataków. Aby program dziaģaģ w tle jako demon, naleŋy uŋyæ opcji-D(np. snort -d -D -c snort.conf). Reszta operatorów i ich opisy, jakie moŋna wykorzystaæ przy starcie programu, przedstawia parametr-h.
Preprocesory
Preprocesory zostaģy wprowadzone do Snorta w wersji 1.5. Pozwalają uŋytkownikom i programistom w prosty sposób na rozbudowę funkcjonalnoķci caģego systemu poprzez pisanie dodatkowych moduģów (ang. plugins).
Preprocesory analizują pakiety przed wykorzystaniem ich przez silnik detekcji. W ten sposób zwiększają moŋliwoķci caģego procesu wykrywania ataków sieciowych, wzbogacając go o zdolnoķæ skģadania (reasemblacji) pakietów, wykonywania specyficznych dla poszczególnych protokoģów operacji (np. konwersja na ASCII znaków z URI zakodowanych szesnastkowo, usuwanie ciągów binarnych z sesji FTP czy Telnet, normalizacja ŋądaņ RPC), jak i wykrywania niezgodnoķci z tymi protokoģami.
Poniŋej pokrótce opiszemy standardowy zestaw preprocesorów wchodzących w skģad darmowej dystrybucji Snorta w wersji 2.1.3.
Frag2 - defragmentuje i normalizuje dane przychodzące w postaci fragmentów, co utrudnia ukrywanie ataków prowadzonych za pomocą nieprawidģowo sfragmentowanych pakietów IP. W tym celu wykorzystuje ustalony przez uŋytkownika bufor pamięci, w której przez okreķlony czas przetrzymuje do badania pakiety z tablicy stanów poģączeņ. Im większa liczba sfragmentowanych pakietów tym wymagany jest większy bufor. Defragmentacja, ukģadając datagramy IP w jedną caģoķæ, uģatwia dalszą analizę danych poprzez pozostaģe preprocesory i silnik detekcji. Frag2 umoŋliwia wychwytywanie znanych ataków wykorzystujących znieksztaģcenia fragmentów pakietów np. teardrop, fragroute.
Stream4 - rozwija model detekcji oparty na testowaniu pojedynczych pakietów umoŋliwiając ķledzenie sesji (stanu poģączenia) TCP i skģadanie (reasemblacji) strumieni TCP, co nie byģoby moŋliwe w mechanizmie opartym na wyszukiwaniu wzorców. Na tym poziomie dziaģa takŋe wykrywanie niektórych prób skanowania portów, gdzie wymagane jest notowanie prób ģączenia się z poszczególnymi usģugami w okreķlonych odstępach czasu oraz wykrywanie prób oszukania Snorta za pomocą narzędzi takich, jak np. Stick lub Snot, które generują pojedyncze (niewchodzące w skģad poprawnych sesji TCP) pakiety mające za zadanie zalaæ mechanizm detekcji masą faģszywych alarmów (są to pakiety budowane na losowo wybranych sygnaturach). Snort broni się przed takimi technikami wykorzystując stream4 preprocesor - losowe pakiety są doķæ ģatwo identyfikowane (i ignorowane), poniewaŋ nie naleŋą do prawidģowej sesji TCP. Stream4 wychwytuje próby skanowania technikami: stealth, null, xmas, fin; wykrywanie systemu operacyjnego - fingerprint i inne anomalia związane z protokoģem TCP.
Flow i Flow-Portscan - posiada mechanizm ķledzenia poģączeņ, zapisując caģoķæ do tablicy stanów w celu dalszego przetwarzania. Na tej podstawie flow-portscan wykrywa próby skanowania w bardziej wyrafinowany sposób niŋ preprocesory stream4 i portscan. Celem wykrywania, są skany z jednego hosta do wielu i z jednego hosta na wiele portów. Flow-portscan prowadzi statystyki na podstawie punktacji róŋnych rodzajów poģączeņ, np. jeķli jakaķ usģuga jest popularna i na jej port przychodzi duŋo zapytaņ, jednoczeķnie dostaje najmniej punktów w ogólnej skali. Preprocesor posiada bardzo wiele opcji za pomocą, których reguluje się skale punktacji, rozmiary tablicy wyników, tolerancję niepowtarzalnoķci zdarzeņ itp.
HTTP Inspect - jest ogólnym dekoderem protokoģu HTTP na poziomie warstwy aplikacyjnej. Za pomocą ustalonego bufora wynajduje odpowiednią skģadnie HTTP i ją normalizuje. HTTP Inspekt dziaģa w obydwu trybach jednoczeķnie: client requests (pol. zapytania klienta) i server responses (pol. odpowiedzi serwera). Mnoga liczba dostępnych opcji w konfiguracji preprocesora, umoŋliwia dostosowanie ustawieņ do konkretnego typu serwera WWW. Gģównymi zadaniami http_inspect jest przetwarzanie adresów URI, konwertując na ASCII znaki zakodowane w postaci szesnastkowej. Utrudnia to ukrycie ataku przed moduģem wykrywającym sygnatury ataków przez zakodowanie typowych sekwencji. Dekoduje takŋe znaki zakodowane jako Unicode, oraz wykrywa nielegalne kodowania, wykorzystywane m.in. w ostatnich dziurach MS IIS.
Portscan Detector - wykrywa próby skanowania portów, polegające na przekroczeniu pewnej progowej liczby prób poģączeņ z róŋnymi portami w okreķlonym przedziale czasu. Ze względu na brak moŋliwoķci uniknięcia faģszywych alarmów w typowych przypadkach (np. obciąŋony serwer DNS), istnieje moŋliwoķæ wyģączenia alarmów wzbudzanych przez okreķlone adresy IP uŋywając dodatkowego procesora portscan-ignorehosts. Pozwala takŋe, zapisaæ wyniki w oddzielnym pliku dziennika.
Telnet Decode - usuwa z sesji TELNET i FTP binarne ciągi mogące utrudniæ wyszukiwanie z udziaģem sygnatur ataków.
RPC Decode - normalizuje ŋądania po protokole RPC, utrudniając ukrywanie podejrzanych pakietów za pomocą mniejszych operacji.
Back Orifice detektor - wyszukuje w pakietach UDP próby poģączeņ konia trojaņskiego Back Orifice i próbuje zģamaæ zabezpieczające je sģabe kodowanie.
Arpspoof - wykrywa podejrzane pakiety ARP, mogące sygnalizowaæ próby ARP spoofingu.
Performance Monitor - udostępnia wszelkiego rodzaju statystyki liczbowe, odnoķnie iloķci przeanalizowanych pakietów, zuŋycia procesora itp. Caģoķæ wyķwietlana jest na ekranie konsoli lub zapisywana do pliku, wg ustalonych wczeķniej wartoķci.
Zarówno preprocesory, jak i mechanizm detekcji mogą zareagowaæ w okreķlony sposób. Po wychwyceniu pakietów, speģniających warunki nadane konfiguracją preprocesorów lub reguģami, podejmowane jest odpowiednie dziaģanie (np. zapisanie pakietów bądž alarm).
Moduģ sygnatur
Gģówny mechanizm systemu detekcji zagroŋeņ polega na dopasowaniu przetworzonych pakietów i ich zrekonstruowanych strumieni z bazą sygnatur. System detekcji porównuje cechy pakietu ze zbiorem reguģ. Po dopasowaniu, zostaje podjęta odpowiednia akcja. Do porównywalnych cech naleŋą atrybuty gģówne - adresy, porty žródģowe i docelowe oraz opcje pomocnicze: flagi TCP identyfikujące np. ŋądania związane z WWW, róŋne typy pakietów ICMP, opcje IP czy wreszcie sama treķæ pakietu. Na razie w gģównej częķci reguģ moŋliwe jest ķledzenie protokoģów IP, ICMP, TCP i UDP. Autorzy przewidują rozszerzenie Snorta o następne protokoģy sieciowe, m.in. IPX, GRE, czy protokoģy wymiany informacji między routerami - RIP, OSPF oraz IGRP.
Reguģy identyfikowania ataku pozwalają na podjęcie pięciu rodzajów akcji: przepuszczenia pakietu (pass), zapisania informacji do dziennika (log), ogģoszenia alarmu (alert), alarmowania i podjęcia do dziaģania innej dynamicznej reguģy (activate) i pozostanie w spoczynku do czasu aktywowania przez reguģę activate, po czym dziaģanie jako reguģa log (dynamic).
Sygnatury Snorta zazwyczaj skģadają się z dwóch gģównych sekcji - nagģówka i ciaģa (treķci). Nagģówek okreķla m.in., jaką akcję naleŋy podjąæ po przypasowaniu reguģy, informacje o wykorzystanym protokole, adresy bądž porty žródģowe i docelowe. Ciaģo reguģy pozwala rozwinąæ informacje zawarte w nagģówku, tu takŋe podaje sią treķæ wzbudzanych alarmów i róŋnego rodzaju informacje dodatkowe (np. odniesienia do bazy z opisami danego naruszenia, tzw. referencje - Bugtraq, CERT czy CVE).
Najprostsze sygnatury obejmują wskazanie akcji, protokoģu, kierunku, adresów i portów będących przedmiotem obserwacji, jak np. poniŋsza reguģa, stanowiąca reakcję na próbę skorzystania z usģugi pop3 (port 110):
log tcp any any -> 192.168.1.0/24 110 |
W sygnaturach moŋna umieszczaæ zmienne zdefiniowane jako adresy sieci (wg CIDR) lub porty zapisane w pliku konfiguracyjnym snort.conf:
log tcp $EXTERNAL_NET -> $HOME_NET 110 |
W podanych powyŋej reguģach wykorzystany byģ jednokierunkowy operator "->". Język sygnatur umoŋliwia zadeklarowanie reguģy, który dopasuje pakiety poruszające się w obu stronach operatorem dwukierunkowym "<>", np.:
alert tcp any any <> $HOME_NET 23 |
Do zasadniczej częķci reguģy moŋna dodaæ ograniczone okrągģymi nawiasami pole opcjonalne (tzw. ciaģo), zawierające definicję bardziej zģoŋonych i wyrafinowanych dziaģaņ związanych z przejęciem danego pakietu. Uŋytkownik moŋe takŋe sformuģowaæ wģasny komunikat, np.:
log tcp $EXTERNAL_NET -> $HOME_NET 110 \
("msg: Proba polaczenia z pop3";) |
Podjęte dziaģania nie muszą byæ ograniczone do pojedynczej czynnoķci. Ķrednik separuje deklaracje poszczególnych dziaģaņ, jak w poniŋszym przykģadzie, w którym opcją content testowana jest treķæ przesyģanego strumienia TCP, a w razie odnotowania podejrzanego ciągu znaków generowany jest odpowiedni komunikat:
alert tcp any any -> 192.168.1.0/24 80 (content: "/cgi-bin/phf"; \
msg: "PHF probe!";) |
Opcji content moŋna uŋyæ nawet kilka razy w jednej regule.
Pozwala to na wyszukiwanie wielu róŋnych ciągów znaków w
obrębie przesyģanych treķci.
Warto nadmieniæ, iŋ do przeszukania treķci pakietów i reasemblowanych strumieni uŋywany jest obecnie najbardziej efektywny algorytm - Boyera-Moore'a, którego wydajnoķæ roķnie wraz z dģugoķcią poszukiwanych ciągów. Moŋliwoķæ rekonstrukcji caģych strumieni transmisji TCP, wglądu w warstwę aplikacyjną i efektywne wyszukiwanie treķci pozwala na walkę przy uŋyciu Snorta równieŋ z zainfekowanymi zaģącznikami elektronicznych listów. Oprócz przeszukiwania treķci pakietów moŋemy badaæ pod róŋnymi kątami ich nagģówki, m.in. pola i kody ICMP, pole TTL, rozmiary fragmentacji czy numery sekwencji.
Bardzo silną konstrukcją w reguģach Snorta jest moŋliwoķæ aktywowania kolejnych reguģ po pierwszym dopasowaniu. Konstrukcja ta nosi nazwę activate/dynamic rules i wygląda w następujący sposób:
activate tcp any any -> $HOME_NET 143 (flags: PA; content: \ "|E8C0FFFFFF|bin|;activates: 1; msg: "IMAP buffer overflow!";) dynamic tcp any any -> $HOME_NET 143 (activated_by: 1; count: 50;) |
Opcje activates i
activated_by wiąŋą reguģy
activate i
dynamic. W powyŋszym przykģadzie wykrycie ataku typu buffer
overflow na serwer IMAP powoduje uruchomienie kolejnej,
dynamicznej reguģy, która zbiera treķæ następnych 50 pakietów
(opcja count) w celu póžniejszej analizy. Druga opcja w reguģy
dynamicznej jest obligatoryjna - reguģa zawierająca wyģącznie
opcję dowiązania do innej, macierzystej konstrukcji jest
bezuŋyteczna.
Następne godne uwagi parametry, to
resp i react wspierają
mechanizm elastycznego reagowania na atak. Opcja
resp moŋe
doprowadziæ do zerwania poģączenia, np. poprzez wysģanie do
atakującego komunikatu ICMP o niedostępnoķci trasy do
zaatakowanego komputera, natomiast react sģuŋy do blokowania
dostępu do usģug związanych z WWW.
Ciekawe projekty
Nessus - sieciowy tester bezpieczeņstwa, przydatny do okreķlania skutecznoķci skonfigurowanego przez nas Snorta.
SnortALog - skrypt Perlowy pozwalający na generowanie róŋnego rodzaju raportów, grafów i statystyk. Korzystając z logów Snorta, format wygenerowanych raportów moŋe stanowiæ plik tekstowy, HTML, a nawet PDF.
Snort Inline - poprawka dla Snorta, umoŋliwiająca wspóģprace z reguģami firewalla IPtables, stosowanego w systemach opartych na jądrze Linux. Specjalnie sformuģowane sygnatury Snorta, reagują na atak i blokują bądž przekierowują za pomocą ķciany ogniowej drogę pakietów pochodzących od intruza.
SnortSam - jest to zestaw pluginów do Snorta peģniących podobną funkcje jak Snort Inline, ale wspomagająca większą liczbę róŋnego rodzaju zapór ogniowych (m.in. Checkpoint Firewall-1, Cisco PIX, Cisco Routers z ACL, Netscreen, IP Filter dla *BSD, Linux IPchains, Linux IPtables, WatchGuard Firebox).
FLoP - projekt ma na celu, przyspieszenie logowania w procesie wykrywania wģamaņ. Do tego wykorzystuje odpowiednie bufory i moŋliwoķæ szybkiego zapisu przez gniazdo unixowe do baz danych MySQL i PostgreSQL. Bardzo przydatne narzędzie przy pracy w sieciach o duŋej przepustowoķci.
Syslog-ng
Wstęp
W PLD domyķlnie instalowanym systemem magazynowania zdarzeņ systemowych (logów) jest syslog-ng (syslog - new generation), zająģ on miejsce klasycznego tandemu syslogd i kalogd. Jest to program o bogatych opcjach konfiguracji, zapewniający większą pewnoķæ dziaģania, a co za tym idzie większe bezpieczeņstwo logów.
Większe bezpieczeņstwo zapewnia moŋliwoķæ uŋycia protokoģu TCP w komunikacji z tzw. loghostem, aby jednak korzystaæ z dobrodziejstw tego protokoģu na obu maszynach musi byæ uŋyty demon "nowej generacji". Moŋliwa jest takŋe komunikacja z klasycznym syslogiem, w tym wypadku musimy uŋyæ protokoģu UDP i portu 514 (wartoķæ domyķlna dla syslog-ng).
Konfiguracja
Syslog-ng jest dostarczany z rozbudowanym plikiem konfiguracji, znajdziemy w nim wiele gotowych do wykorzystania przykģadów.
Konfiguracja demona polega na zdefiniowaniu pewnych obiektów, a na następnie poģączenie ich ze sobą w reguģy. Mamy trzy rodzaje obiektów: žródģa, filtry i cele. Žródģa wskazują miejsca pochodzenia komunikatów, filtry pozwalają selekcjonowaæ dane, cele zaķ wskazują sposób i miejsce magazynowania logów (zwyczajowo jako pliki tekstowe w katalogu /var/log). Caģą konfigurację umieszczamy w jednym pliku: /etc/syslog-ng/syslog-ng.conf.
Žródģa - definiujemy je następująco:
source $nazwa { $žródģo($opcje); };
najpopularniejsze žródģa komunikatów to:
internal - komunikaty demona syslog-ng
tcp - komunikaty od innych komputerów w sieci (TCP)
udp - komunikaty od innych komputerów w sieci (UDP)
pipe - nazwane potoki
unix-stream - gniazda uniksowe
source src { internal(); }; source udp { udp(); }; source tcp { tcp(ip(192.168.1.5) port(1999) max-connections(20)); };Pierwszy z przykģadów jest žródģem komunikatów syslog-a. Drugi tworzy žródģo komunikatów wysyģanych z dowolnej maszyny w sieci - nasģuch na domyķlnym porcie (514 UDP). Trzeci oczekuje komunikatów od komputera 192.168.1.5 na porcie 1999 z ograniczeniem do 20 poģączeņ.
Filtry:
filter $nazwa { $rodzaj($wartoķæ); };
rodzaje:
facility - pochodzenie zdarzenia: cron, daemon, mail, ... - szczegóģy w dodatku
level - priorytet: emerg, alert, crit, ... - szczegóģy w dodatku
host - filtrowane po nazwie hosta z uŋyciem wyraŋeņ regularnych
program - filtrowane po nazwie programu z uŋyciem wyraŋeņ regularnych
Pierwszy przykģadowy filtr przepuszcza jedynie powiadomienia o najpowaŋniejszych bģędach. Drugi zdarzenia pochodzące od demonów, trzeci wybiera zdarzenia pochodzące od komputera mającego w nazwie ciąg "foo". Ostatni odfiltrowuje zdarzenia wywoģywane w skutek dziaģania programów su i sudo - uŋycie wyraŋeņ regularnych.filter f_emergency { level(emerg); }; filter f_daemon { facility(daemon); }; filter f_foo { host("foo"); }; filter f_su_sudo { program("^su|sudo$"); };W filtrach moŋemy uŋywaæ operatorów logicznych (and, or, not):
filter f_syslog { not facility(authpriv, cron, lpr, mail, news); }; filter f_ppp { facility(daemon) and program(pppd) or program(chat); };Cele - ogólna definicja:
destination $nazwa { $cel($miejsce); };
najpopularniejsze cele:
file - plik tekstowy / urządzenie znakowe (/dev/)
usertty - ekran terminala wskazanego uŋytkownika
tcp - komunikaty do loghosta (TCP)
udp - komunikaty do loghosta (UDP)
W pierwszym przykģadnie komunikaty są kierowane do pliku /var/log/kernel, w drugim będą wyķwietlane na dwunastym wirtualnym terminalu. Trzeci cel spowoduje wyķwietlanie komunikatu na ekranie terminala uŋytkownika root. Czwarty obiekt pozwoli na wysyģanie komunikatów do loghosta o adresie IP 10.0.0.1 (uwaga na zgodnoķæ protokoģów TCP/UDP u nadawcy i odbiorcy).destination kernel { file("/var/log/kernel"); }; destination console_all { file("/dev/tty12"); }; destination root { usertty("root"); }; destination loghost { udp("10.0.0.1"); };Reguģki - budujemy je na samym koņcu, kiedy mamy juŋ zdefiniowane žródģa, filtry i cele:
log { source($žródģo); destination($cel); };
log { source($žródģo); filter($filtr1); filter($filtr2); destination($cel); };
np.:
log { source(src); destination(console_all); }; log { source(src); filter(f_emergency); destination(loghost); };
Aby zmiany weszģy w ŋycie oraz utworzone zostaģy nowe pliki dzienników, naleŋy ponownie uruchomiæ demona:
# service syslog-ng reload |
Test konfiguracji
Najlepszą metodą sprawdzenia konfiguracji sysloga jest wysģanie wģasnych komuników systemowych. Posģuŋymy się w tym celu programem logger, pozwalającym wysyģaæ dowolne komunikaty z wiersza poleceņ. Dla naszych potrzeb wywoģujemy program następująco:
logger -p {$žródģo}.{$poziom} {$komunikat} np.:
# logger -p mail.warning Test ostrzeŋenia |
Uwagi
Podobnie jak poprzednik nie kontroluje objętoķci logów, tak więc nie moŋna zapomnieæ o programie rotującym np. logrotate.
Domyķlnie demon nie nasģuchuje komunikatów z sieci, definicja žródģa za to odpowiedzialna jest wykomentowana.
W ramach ochrony przed atakami DoS syslog-ng obsģuguje domyķlnie do 10 poģączeņ sieciowych, aby to zmieniæ naleŋy uŋyæ parametru "max-connections" w opcjach žródģa (patrz przykģady).
Dodatek
System operacyjny posiada wewnętrzny, niezaleŋny od demona logów, schemat klasyfikowania zdarzeņ, dzielą się one na dwie grupy:
Pochodzenie komunikatów (facility):
Priorytety (level):
X-Window
Rozdziaģ opisuje konfigurację ķrodowiska graficznego.
Wstęp
W rozdziale tym postaramy pomóc w stworzeniu systemu "biurkowego", czyli systemu z X-Window. Będziemy tu opisywaæ implementację X.Org, więcej na jej temat moŋna znaležæ na witrynie projektu http://www.x.org/wiki/. Sam proces tworzenia desktopu moŋemy podzieliæ na dwa etapy:
Instalacja i konfiguracja serwera protokoģu X11
Instalacja i konfiguracja menedŋera okienek dla X.org (przedstawimy tutaj KDE i GNOME)
Od razu naleŋy przestrzec, ŋe ķrodowisko graficzne jest obsģugiwane przez skoņczoną liczbę urządzeņ (dotyczy to zwģaszcza kart graficznych) i moŋe się niestety zdarzyæ, ŋe posiadamy kartę graficzną, która nie jest obsģugiwana. Dotyczy to gģównie najnowszego sprzętu, starsze modele mają dosyæ dobre wsparcie.
W przypadku kart firm firm ATI i NVIDIA, mamy dostępne zarówno sterowniki będące częķcią X.Org jak i sterowniki zamknięte, tworzone przez samych producentów. Nielicznymi zaletami tych drugich jest bardzo dobra wydajnoķæ i peģne wsparcie dla akceleracji grafiki trójwymiarowej.
X-Server
Instalacja
Na początku, korzystając z programu poldek instalujemy konieczne pakiety. W przypadku Ac będą to:
$ poldek -i X11 X11-modules X11-fonts-100dpi-ISO8859-2 X11-setup \ X11-imake X11-libs X11-Xserver X11-OpenGL-libs X11-fonts \ X11-common X11-fonts-base X11-xauth X11-fonts \ X11-fonts-75dpi-ISO8859-2 X11-OpenGL-core X11-fonts-100dpi \ X11-fonts-ISO8859-2 X11-sessreg |
W Th zmieniģy się nazwy pakietów i są o wiele bardziej rozdrobnione, zaczynamy od instalacji rdzenia X-Serwera i podstawowych sterowników:
$ poldek -i xorg-xserver-server \ xorg-driver-input-keyboard \ xorg-driver-input-mouse |
$ poldek -i xorg-driver-video-nv |
$ poldek -i xorg-driver-video-ati |
$ poldek -i xorg-driver-video-vesa |
Zanim zaczniemy konfigurację
Uŋytkownicy myszek PS/2 lub USB, którzy nie korzystają z dobrodziejstw udeva muszą zaģadowaæ oprócz moduģu huba USB moduģy:
# modprobe psmouse # modprobe usbhid |
Aby moduģy ģadowaģy się za kaŋdym razem, gdy uruchamiamy system, naleŋy dodaæ ich nazwy do pliku /etc/modules. Więcej o zarządzaniu moduģami w sekcja Statyczne zarządzanie moduģami w rozdziaģ Kernel i urządzenia.
Pierwsze uruchomienie
X.Org nie wymaga pliku konfiguracji do podstawowego dziaģania, po uruchomieniu automatycznie próbuje wykryæ doģączony sprzęt. X-Serwer uruchamiamy następująco:
# X |
Teraz moŋemy przejķæ do konfiguracji X-Servera lub do uruchomienia ķrodowiska graficznego. Warto przeprowadziæ przynajmniej podstawową konfigurację, by uzyskaæ większą ergonomię pracy, ustawiæ ukģad klawiatury dla danego języka, czy obsģuŋyæ dodatkowe moŋliwoķci sprzętu.
Konfiguracja
Generujemy wstępną konfigurację serwera X11:
# X -configure |
W wyniku dziaģania w/w polecenia w katalogu domowym uŋytkownika (w tym wypadku /root/) powstanie plik xorg.conf.new. X-Server stara się rozpoznaæ uŋywany przez nas sprzęt i ustawia wģaķciwe parametry w pliku konfiguracji.
Przenosimy plik we wģaķciwe miejsce:
# mv ~/xorg.conf.new /etc/X11/xorg.conf |
Teraz moŋemy spróbowaæ, czy serwer nam się uruchamia:
# X |
W ten oto sposób mamy wstępnie skonfigurowany X-Server i moŋemy rozpocząæ pracę w ķrodowisku graficznym. Wskazówki bardziej wyrafinowanej konfiguracji odnajdziemy w sekcja Zaawansowane. Częķæ z nich będziemy mogli dokonaæ za pomocą poniŋej opisanych programów (np. xorgcfg -textmode), bardziej zaawansowane opcje ustawimy wyģącznie edytując plik konfiguracji.
Inne sposoby konfiguracji
Z aplikacją dostarczane są dodatkowo dwa programy do konfiguracji, obydwie moŋna uŋyæ do generowania pliku konfiguracji zamiast operacji X -configure, pozwalają na precyzyjnie ustawianie parametrów X-Servera X -configure, jednak wymagają teŋ więcej wiedzy i pracy.
xorgcfg - program który moŋe dziaģaæ w dwóch trybach: graficznym i tekstowym (z uŋyciem parametru
-textmode). Program ma tą zaletę, ŋe moŋe modyfikowaæ istniejący plik konfiguracji. O ile wygodę trybu graficznego moŋna uznaæ za dyskusyjną, o tyle tryb tekstowy nie powinien sprawiaæ nikomu problemów.xorgconfig - jest to konsolowe narzędzie, które prowadzi krok po kroku przez kolejne etapy konfiguracji. W zasadzie to przydaje się do generowania pliku konfiguracji po raz pierwszy (zamiast X -configure), jeķli chce się dokonaæ jakiejkolwiek zmiany trzeba przechodziæ przez wszystkie kroki na nowo. Program ten dodatkowo dodaje do pliku liczne komentarze, co nie wszystkim odpowiada.
Rozwiązywanie problemów
Jeŋeli pojawi się jakiķ problem musimy przeanalizowaæ komunikaty wypisywane na ekran i do pliku /var/log/Xorg.0.log. Bģędy są oznaczane dwoma literkami EE np.:
(EE) Failed to load module "ati" (module does not exist, 0) |
Ķrodowisko graficzne (GUI)
Do wyboru mamy dwa potęŋne, zintegrowane ķrodowiska: KDE i Gnome, nieco mniejsze XFCE4, czy caģkiem proste np. : blackbox, fluxbox będące jedynie zarządcami okien i pulpitu. ķrodowiska opisaliķmy w dalszych rozdziaģach. Oprócz ķrodowiska musimy wybraæ sposób jego uruchamiania. Moŋemy uruchamiaæ je z wiersza poleceņ za pomocą skryptu startx lub demonów GDM/KDM. Zagadnienia te szczegóģowo omówiliķmy w sekcja Uruchamianie ķrodowiska graficznego.
Zaawansowane
W tym miejscu zajmiemy się bardziej zaawansowaną konfiguracją X-Servera. Zakģadam, ŋe istnieje wstępnie skonfigurowany plik /etc/X11/xorg.conf, za pomocą polecenia X -configure. Wiele opisanych tu czynnoķci konfiguracyjnych dla konkretnych podsystemów, wykonujemy za pomocą programu xorgcfg, uruchamiamy go w trybie tekstowym :
# xorgcfg -textmode |
Bardziej zaawansowane będą wymagaģy ingerencji za pomocą edytora tekstu, przypominam, ŋe "obrabiamy" plik # /etc/X11/xorg.conf.
Mysz
Zakģadam, ŋe w programie wybraliķmy sekcję konfiguracji myszki.
Dla wspóģczesnych myszek, w konfiguracji protokoģu wybieramy
Auto, dla myszek szeregowych wybierzemy
Microsoft. Następnie konfigurator spyta o to,
czy dla myszek dwuprzyciskowych wģączyæ emulację trzeciego klawisza,
w przypadku myszek o większej iloķci przycisków odpowiadamy
negatywnie. Jako urządzenie
wybieramy /dev/input/mice.
Po zapisaniu wybranej konfiguracji, otrzymamy w sekcji
ustawieņ myszy w pliku /etc/X11/xorg.conf
fragment o zbliŋonej konstrukcji:
Section "InputDevice"
Identifier "Mouse0"
Driver "mouse"
Option "Protocol" "Auto"
Option "Device" "/dev/input/mice"
Option "ZAxisMapping" "4 5 6 7"
EndSection |
Jeķli posiadamy myszkę z wieloma klawiszami i rolkami, a standardowy sterownik nie radzi sobie z obsģugą wszystkich zdarzeņ, to moŋemy wybraæ bardziej nowoczesny i elegancki sposób na uruchomienie naszego sprzętu - evdev. Przykģadowa instalacja i konfiguracja zostanie przedstawiona dla popularnej myszki Logitech MX500. Pierwszym krokiem jest zaģadowanie moduģu jądra modprobe evdev oraz instalacja pakietu xorg-driver-input-evdev (X11-driver-evdev dla Ac). Następnie odszukujemy w /proc/bus/input/devices numer urządzenia eventX naszej myszki i wpisujemy do konfiga X.Org poniŋszą sekcję:
Section "InputDevice"
Identifier "Mouse1"
Driver "evdev"
Option "Device" "/dev/input/event1"
Option "Buttons" "10"
EndSection |
Klawiatura
Nowo wygenerowany plik konfiguracji nie zawiera opcji lokalnych,
aby je ustawiæ, z menu programu wybieramy Configure keyboard,
Jako model (Keyboard model)
wybieramy np. Generic 104-key PC,
a w Keyboard layout ustawiamy Poland.
Powyŋsza operacja wygeneruje następującą konfigurację klawiatury:
Section "InputDevice"
Identifier "Keyboard0"
Driver "kbd"
Option "XkbModel" "pc104"
Option "XkbLayout" "pl"
EndSection |
Jeķli posiadamy klawiaturę multimedialną i chcemy wykorzystywaæ jej dodatkowe klawisze, to musimy wybraæ odpowiedni model klawiatury. Nasz wybór będzie dotyczyģ wartoķci parametru XkbModel, następnie musimy sprawdziæ za pomocą programu xev czy wszystkie zdarzenia z klawiszy multimedialnych są prawidģowo obsģugiwane przez X-serwer.
Monitor
Wģaķciciele monitorów LCD/Plasma są na uprzywilejowanej pozycji, jeķli sterownik karty graficznej potrafi "porozumieæ się" z monitorem (za pomocą DDC), to nie są wymagane ŋadne czynnoķci konfiguracyjne. Aby detekcja następowaģa automatycznie musimy w pliku konfiguracji postawiæ znak komentarza ("#") przed opcjami HorizSync, VertRefresh.
W pozostaģych przypadkach musimy okreķliæ parametry monitora. Wybierając opcje programu Configure monitor, będziemy będziemy mogli wybraæ jakiķ monitor z listy lub podaæ parametru wģasnego urządzenia: Enter your own horizontal sync range. Tu podajemy wartoķci HorizSync (w kHz) i VertRefresh w (Hz) zgodne ze specyfikacją naszego urządzenia. Po zapisaniu pliku konfiguracji otrzymamy:
Section "Monitor"
Identifier "Monitor0"
HorizSync 31.5 - 96.0
VertRefresh 50 - 100
Option "DPMS"
EndSection |
O ile HorizSync jest opcją ķciķle zaleŋną od moŋliwoķci monitora i pod ŋadnym pozorem nie powinniķmy jej dowolnie zmieniaæ, o tyle VertRefresh daje więcej swobody. Za jej pomocą ustawiamy odķwieŋanie obrazu, Nie moŋemy oczywiķcie przekroczyæ parametrów monitora, ale moŋemy ustawiæ minimalne odķwieŋanie, np. 85 - 85 wymusi częstotliwoķæ 85Hz. (oczywiķcie pod warunkiem, ŋe nasz monitor, przy danej rozdzielczoķci pozwala na wyķwietlanie z taką wartoķcią).
Rozdzielczoķæ obrazu
Wstępnie plik konfiguracji nie zawiera ŋadnych definicji rozdzielczoķci i będzie ona ustalana automatycznie, co jest wskazane przy monitorach LCD/Plasma. W przypadku monitorów CRT, zapewne będziemy chcieli uŋyæ najbardziej ergonomicznej. Mamy tu dwa wyjķcia, moŋemy nic nie ustawiaæ w X.Org, ale za to ustawiæ ją w aplikacjach konfiguracyjnych ķrodowisk Gnome/KDE, lub ustawiæ ją na staģe w konfiguracji X-serwera. Moŋliwoķci ustawieņ konfiguratorów w ķrodowiskach graficznych są dosyæ skromne, dlatego niektórzy pokuszą się zapewne o ustawienie odpowiednich wartoķci na staģe.
Po wybraniu Configure screen w programie, zostaniemy zapytani o iloķæ dostępnych kolorów, dla wspóģczesnego sprzętu bez zastanowienia moŋemy wybraæ 24bity na piksel a następnie wybieramy listę rozdzielczoķci, które mają byæ dostępne. W większoķci wypadków wystarczy nam jedna rozdzielczoķæ. Oczywiķcie musi byæ obsģugiwana przez monitor. Zapisana konfiguracja moŋe wyglądaæ następująco:
Section "Screen"
Identifier "Screen0"
Device "Card0"
Monitor "Monitor0"
SubSection "Display"
Viewport 0 0
Depth 24
Modes "1024x768"
EndSubSection
EndSection |
Zaawansowane - DPI
X.Org pozwala na wskazanie DPI (dots per inch), w celu lepszego dopasowania wielkoķci wyķwietlanych czcionek ekranowych. W przypadku wspóģczesnych monitorów, za pomocą DDC odczytywany jest rozmiar obszaru wyķwietlania, by automatycznie okreķliæ DPI. Dla monitorów, które nie posiadają takiej moŋliwoķci lub podają ją nieprawidģowo, będziemy mogli sami ten parametr ustawiæ. Wartoķæ DPI moŋna teŋ ustawiæ bezpoķrednio w konfiguracji ķrodowiska (np. w Gnome) my jednak pokaŋemy jak zrobiæ do w X-serwerze. W sekcji Monitor pliku konfiguracji naleŋy dodaæ opcję:
DisplaySize $x $y |
gdzie parametry $x i $y są wymiarami w milimetrach, odczytanymi z dokumentacji urządzenia lub po prostu zmierzonymi linijką. Sekcja konfiguracji monitora moŋe wyglądaæ następująco:
Section "Monitor"
Identifier "Monitor0"
HorizSync 31.5 - 96.0
VertRefresh 50 - 100
DisplaySize 269 201
EndSection |
Zaawansowane - serwer czionek
Zaczynamy od instalacji serwera XFS(Th): xorg-app-xfs, w przypadku Ac jest to pakiet X11-xfs. Dla wygody zaģoŋymy takŋe, ŋe będziemy korzystaæ z serwera czcionek X11-xfs, który uruchamiamy poleceniem /etc/init.d/xfs start. Dlatego teŋ sekcja dotycząca czcionek w pliku xorg.conf.new powinna wyglądaæ podobnie do podanego niŋej przykģadu:
Section "Files" RgbPath "/usr/X11R6/lib/X11/rgb" # FontPath "/usr/X11R6/lib/X11/fonts/local/" # FontPath "/usr/X11R6/lib/X11/fonts/misc/" # FontPath "/usr/X11R6/lib/X11/fonts/75dpi/:unscaled" # FontPath "/usr/X11R6/lib/X11/fonts/100dpi/:unscaled" # FontPath "/usr/X11R6/lib/X11/fonts/Type1/" # FontPath "/usr/X11R6/lib/X11/fonts/Speedo/" # FontPath "/usr/X11R6/lib/X11/fonts/75dpi/" # FontPath "/usr/X11R6/lib/X11/fonts/100dpi/" FontPath "unix/:7100" # ModulePath "/usr/X11R6/lib/modules" EndSection |
Czyli komentujemy wszystkie wywoģania bezpoķrednie do czcionek i przekazujemy obsģugę zarządzania czcionkami serwerowi xfs.
Uwagi
Parametry monitora mogą byæ odczytywane za pomocą moduģu DDC, o ile monitor jest wģączony. Powinniķmy zatem wģączaæ monitor przed uruchomieniem X-Servera lub ustawiæ "na sztywno" jego parametry, inaczej w skrajnym wypadku obraz będzie miaģ rozdzielczoķæ 640x480, przy odķwieŋaniu 60Hz.
Ķrodowisko GNOME
Instalacja
GNOME jest rozbudowanym ķrodowiskiem, dodatkowo filozofia mikropakietów w PLD nie uģatwia jego instalacji początkującym. Aby temu zaradziæ stworzone zostaģy metapakiety, które oszczędzą nam sporej iloķci pracy, oto ich zestawienie:
metapackage-gnome - gģówna częķæ ķrodowiska
metapackage-gnome-extras - dodatki
metapackage-gnome-extras-accessibility - narzędzie uģatwieņ dostępu
metapackage-gnome-office - pakiet aplikacji biurowych
poldek> install metapackage-gnome |
Jeķli jednak jesteķmy zwolennikami instalacji tylko tego co jest potrzebne, musimy instalowaæ kaŋdy pakiet z osobna:
poldek> install gnome-desktop gnome-session nautilus xscreensaver-gnome2 gnome-themes \ gnome-icon-theme gnome-panel gnome-splash-gnome metacity \ gnome-applets |
Lista komponentów i aplikacji dla GNOME jest w PLD imponująca, aby ģatwiej byģo się odnaležæ w tym gąszczu, zachęcamy do zapoznania się z zestawieniem aplikacji w dalszej częķci rozdziaģu.
Internacjonalizacja
Aby GNOME i GDM obsģugiwaģy język inny niŋ angielski, naleŋy ustawiæ tzw. Locale, co zostaģo opisane w sekcja Internacjonalizacja w rozdziaģ Konfiguracja systemu, a następnie wybraæ preferowany język: Language z menu GDM-a.
Džwięk
Zakģadam, ŋe juŋ zostaģa skonfigurowana juŋ ALSA, zgodnie ze wskazówkami opisanymi w sekcja ALSA - Džwięk w Linuksie w rozdziaģ Usģugi dostępne w PLD. Od GNOME 2.26 džwięk jest obsģugiwany przez aplikację pulseaudio, zapewniającą programowe miksowanie džwięku z wielu žródeģ, czy teŋ przesyģanie strumienia za poķrednictwem sieci. Instalujemy:
$ poldek -i pulseaudio pulseaudio-gconf pulseaudio-alsa gstreamer gstreamer-audiosink-esd |
$ poldek -i gstreamer-audio-formats gstreamer-mad |
$ poldek -i gnome-media gnome-applets-mixer totem gnome-audio |
Uruchomienie
Zanim uruchomimy ķrodowisko, musimy się upewniæ, czy nazwa hosta (opcja HOSTNAME z pliku /etc/sysconfig/network) jest przypisana do adresu IP. Aby to ustawiæ, naleŋy dodaæ odpowiedni wpis do pliku /etc/hosts, zgodnie ze wskazówkami zawartymi w sekcja Podstawowa konfiguracja sieci w rozdziaģ Interfejsy sieciowe, np.:
127.0.0.1 pldmachine |
Administracja - GNOME System Tools
GST to zestaw wygodnych narzędzi administracyjnych, obsģugujących PolicyKit. Pozwala na zarządzanie m.in. usģugami, uŋytkownikami oraz siecią. Instalacja:
$ poldek -i gnome-system-tools system-tools-backends |
# /etc/init.d/system-tools-backends start |
# groupmod -A jkowalski adm |
Przydatne drobiazgi
O wygodzie pracy w ķrodowisku czasami decydują drobiazgi, oto lista takich niewielkich narzędzi, przydatnych w codziennej pracy:
gnome-volume-manager - narzędzie do zarządzania woluminami wymiennymi: montowaniem noķnikow, odtwarzaniem muzyki i innymi
gnome-utils-screenshot - program do szybkiego wykonywania zrzutów ekranu.
nautilus-cd-burner - rozszerzenie do nautilusa sģuŋące do nagrywania pģyt CD/DVD
gnome-system-monitor - monitor zasobów i procesów
gnome-utils-search-tool - wyszukiwarka plików
Godne polecenia aplikacje
Zaletą zģoŋonych ķrodowisk takich jak GNOME czy KDE jest duŋa liczba programów, które dobrze integrują się ze ķrodowiskiem, poniŋej zostaģa zamieszczona lista uŋytecznych programów.
gnome-terminal - rozbudowany emulator terminala z obsģugą zakģadek
gcalctool - wielofunkcyjny kalkulator
totem - odtwarzacz audio i video.
Exaile, Quod Libet i Rhythmbox - wygodne odtwarzacze audio z dobrą obsģugą duŋych bibliotek muzyki, wszystkie obsģugują gstreamera.
eog - Eye of GNOME - narzędzie do przeglądania obrazków
evince - program sģuŋący do przeglądania dokumentów w formatach pdf, postscript i wielu innych.
gedit2 - edytor tekstu z obsģugą kolorowania skģadni języków programowania i wtyczek.
epiphany - przeglądarka WWW z silnikiem renderującym Gecko
evolution - rozbudowany klient poczty i narzędzie do planowania zadaņ
gajim - klient Jabbera
file-roller - zarządca archiwów - jest graficznym interfejsem dla wģasciwych narzędzi archiwizacji danych
Brasero (dawniej Bonfire) - komfortowe narzędzie do nagrywania pģyt CD/DVD.
Więcej na stronie www.gnome.org/projects/, warto teŋ odwiedziæ stronę www.gnomefiles.org, będącej bogatym zestawieniem aplikacji bardziej lub mniej związanych ze ķrodowiskiem.
Pomoc i rozwiązywanie problemów
GNOME jest dostarczane z pokažną dokumentacją - niestety brak jest polskiego tģumaczenia. Jest dostępna dla aktywnego okna po wciķnięciu przycisku F1 lub po wywoģaniu programu yelp - przeglądarki dokumentacji. Musimy tylko doinstalowaæ konieczne pakiety:
$ poldek -i gnome-user-docs yelp |
Jeķli natkniemy się na jakieķ problemy z dziaģaniem aplikacji, na początek powinniķmy zajrzeæ do specjalnego dziennika bģędów:
$ cat ~/.xsession-errors |
Ķrodowisko KDE
Poniŋej przedstawiamy listę zalecanych pakietów dla KDE:
kdeaddons-ark kdeadmin-kpackage kdebase-desktop kdebase-kate \ kdebase-konsole kdebase-kwrite kdegraphics-kfile \ kdegraphics-kghostview kdegraphics-kpdf kdemultimedia-akode \ kdemultimedia-juk kdemultimedia-kaboodle kdemultimedia-kfile \ kdemultimedia-kmid kdemultimedia-kmix kdemultimedia-kscd \ kdemultimedia-mpeglib kdenetwork-kget kdesdk-kfile \ kdeutils-ark kdeutils-kcalc kdeutils-kedit kdeutils-kfloppy \ kdeutils-kwalletmanager konqueror |
Aby móc uruchomiæ KDE dla danego uŋytkownika, w jego katalogu domowym wykonujemy polecenie:
$ echo "kde" >.desktop |
Od tej chwili, domyķlnym ķrodowiskiem graficznym dla tego uŋytkownika jest KDE, które moŋemy uruchomiæ za pomocą polecenia startx.
Blackbox - Szybki i lekki zarządca okien
Wstęp
Blackbox jest lekkim menedŋerem okien dla XFree86. Jest napisany w C++, a jego projekt zakģadaģ wydajnoķæ, niskie uŋycie pamięci oraz brak zaleŋnoķci od zewnętrznych bibliotek. Blackbox zabiera bardzo niewiele miejsca na ekranie na dekoracje okien. Mimo swojego minimalizmu, jest bardzo wygodny i funkcjonalny. Zawiera wszystko, czego oczekuje się od menedŋera okien - obsģugę wirtualnych pulpitów, okna typu sticky, zwijanie okien, okna pozbawione dekoracji. Posiada teŋ pasek dokowania, zwany slitem, na którym mogą umieszczaæ się aplety w stylu NEXTstep (np. Window Maker, AfterStep) oraz okna w trybie withdrawn (np. gkrellm). Te cechy sprawiģy, ŋe Blackbox staģ się caģkiem popularny wķród osób nie lubiących przeģadowania towarzyszącego ķrodowiskom KDE i GNOME
Dzięki swoim zaletom Blackbox staģ się na tyle znany, ŋe wypączkowaģo z niego kilka odmian z nowymi cechami. Naleŋą do nich Fluxbox, Openbox i Kahakai. Blackbox i jego pochodne są doskonaģym wyborem, jeķli poŋądane jest oszczędzanie pamięci i niskie wykorzystanie procesora. Są teŋ dobre dla tych, którzy wolą elegancję ponad nadmiar elementów, jaki występuje w popularnych ķrodowiskach. My w tym opisie zajmiemy się instalacją Blackbox.
Instalacja pakietów
Czas zainstalowaæ potrzebne nam pakiety.
# poldek -i blackbox vfmg xinitrc |
Instalacja zajmuje bardzo maģo czasu, poniewaŋ jak juŋ wspomniane zostaģo wczeķniej Blackbox jest bardzo maģo wymagający jeŋeli chodzi o zasoby.
Konfiguracja
Teraz aby Blackbox byģ naszym domyķlnym menadŋerem okien naleŋy ustawiæ go w pliku /etc/sysconfig/desktop
# cat /etc/sysconfig/desktop # PREFERRED can be GNOME, KDE or empty # when left empty $DEFAULTWM will be started PREFERRED=blackbox DEFAULTWM= # Default window manager to use. Should be basename of file from # /etc/sysconfig/wmstyle/ WMSTYLE= |
W tym momencie mamy juŋ skonfigurowanego Blackbox i w zasadzie moŋna by go juŋ uruchomiæ ale my skonfigurujemy sobie menu, aby byģo zgodne z zainstalowanymi przez nas programami
W tym celu z pomocą przyjdzie nam program vfmg, który juŋ wczeķniej zainstalowaliķmy. Komendy które są poniŋej naleŋy wykonywaæ w katalogu domowym ~/
# mkdir ~/.blackbox # vfmg blackbox > .blackbox/menu |
Mamy juŋ gotowe menu, ale nie ma w nim opcji "Wyjķcie", która jest niewątpliwie przydatną opcją.
W ~/.blackbox/menu naleŋy pod sam koniec dopisaæ "Wyjķcie" tak, aby 3 ostatnie linijki wyglądaģy następująco:
# tail -3 ~/.blackbox/menu
[end]
[exit] (Wyjķcie)
[end] |
Dodatkowo naleŋy edytowaæ plik ~/.blackboxrc i zmieniæ w nim linijkę session.menuFile na:
# grep menu .blackboxrc session.menuFile: .blackbox/menu |
Mając juŋ menu Blackbox moŋemy go wreszcie uruchomiæ:
# startx |
Aby wszystko poprawnie funkcjonowaģo naleŋy zapoznaæ się z dziaģem "Konfiguracja ķrodowiska graficznego", który znajduje się w dokumentacji PLD.
Fluxbox - Następca BlackBoxa
Wstęp
Mģodszym bratem BlackBoxa jest Fluxbox, bazujący na kodzie Blackboxa. Fluxbox wygląda tak samo jak Blackbox, który korzysta z tych samych styli, kolorów, poģoŋenia okien i generalnie jest zachowana peģna kompatybilnoķæ z Blackboxem.
Jakie są więc róŋnice? Odpowiedž brzmi: DUŊE. Np:
Konfigurowalne taby okien
Pasek ikon (do zminimalizowanych okien)
Scroll myszki uŋywany do zmiany obszarów roboczych.
Wsparcie dla KDE i GNOME, a takŋe rozszerzone wsparcie dla WindowMakera.
i jeszcze wiele innych udogodnieņ.
Instalacja pakietów
Czas zainstalowaæ potrzebne nam pakiety.
# poldek -i fluxbox fluxconf |
Wģaķciwie do pracy potrzebny nam jest tylko fluxbox, ale fluxconf trochę uģatwia konfiguracje.
Konfiguracja
Aby fluxbox byģ naszym domyķlnym menadŋerem okien w .Xclients dajemy wpis.
exec fluxbox |
wygląd menu moŋna zmieniaæ edytując plik ~/.fluxbox/menu
Przykģadowy wpis:
[begin] (Fluxbox)
[exec] (aterm) {aterm -tr}
[exec] (Run) {fbrun }
[submenu] (Net)
[exec] (PSI) {psi}
[end]
[end] |
Moŋemy takŋe automatycznie wygenerowaæ menu korzystając z programu vfmg. Instalujemy go poleceniem:
# poldek -i vfmg |
Następnie wydajemy polecenia:
# mkdir ~/.fluxbox # vfmg blackbox > ~/.fluxbox/menu |
Mamy juŋ gotowe menu, ale nie ma w nim opcji "Wyjķcie", która jest niewątpliwie przydatną opcją.
W ~/.fluxbox/menu naleŋy pod sam koniec dopisaæ "Wyjķcie" tak, aby 3 ostatnie linijki wyglądaģy następująco:
# tail -3 ~/.blackbox/menu
[end]
[exit] (Wyjķcie)
[end] |
Chcąc dodaæ tģo pulpitu moŋemy się posģuŋyæ np. programem dispalay z pakietu ImageMagik. Instalujemy go:
# poldek -i ImageMagick |
dodatkowo konieczne jest doinstalowanie moduģów kodera dla plików np. jpeg, png i tiff
# poldek -i ImageMagick-coder-jpeg-5.5.7.12-2 ImageMagick-coder-png-5.5.7.12-2 ImageMagick-coder-tiff-5.5.7.12-2 |
następnie w pliki ~/.fluxbox/init odszukujemy wpis:
session.screen0.rootCommand: i dodajemy: display -size ROZDZIELCOZĶÆ -window root NAZWA_PLIKU_Z_GRAFIKA |
u mnie wpis ten wygląda następująco:
session.screen0.rootCommand: display -size 1024x768 \
-window root ~/DREAMVISIONS.jpg |
I to by byģo wģaķciwie juŋ tyle, moŋna juŋ uruchomiæ naszego menagera okien poleceniem
# startx |
Uruchamianie ķrodowiska graficznego
Istnieją dwie metody uruchamiania ķrodowiska, pierwszą jest uruchamianie systemu na trzecim poziomie pracy (domyķlnie) i autoryzowaniu się w terminalu tekstowym. Po zalogowaniu uruchamiamy program startx. Drugą moŋliwoķcią jest instalacja jednego ze specjalnych demonów: gdm (dla Gnome) kdm (dla KDE) lub xdm i dokonywanie autoryzacji za ich poķrednictwem. Demony te dziaģają na piątym poziomie pracy, dlatego musimy skonfigurowaæ system by domyķlnie startowaģ na tym poziomie. Estetyka i wygoda to nie jedyne zalety demonów, są one silnie zintegrowane ze swoimi ķrodowiskami, dzięki czemu zapewniają wiele dodatkowych funkcji.
Skrypt startx
W tej metodzie po zalogowaniu się w terminalu, uŋytkownik wydaje polecenie startx. Na podstawie wpisu w pliku .xinitrc (w katalogu uŋytkownika) uruchamiane jest wskazane tam ķrodowisko. Aby uŋywaæ tej metody, musimy doinstalowaæ potrzebne pakiety, w przypadku Ac wykonujemy polecenie:
$ poldek -i xinitrc-ng |
$ poldek -i xinitrc-ng xorg-app-xinit |
$ echo "gnome-session" >~/.xinitrc |
$ echo "exec gnome-session" >~/.xinitrc |
$ startx |
Gnome: gnome-session
KDE: startkde
XFCE: startxfce4
fluxbox: fluxbox
icewm: icewm
GDM
Zaczynamy od instalacji demona GDM:
poldek> install gdm gdm-init |
# service gdm start |
KDM
Instalujemy KDM
# poldek -i kdm |
Dla lokalnej pracy nie trzeba nic specjalnie konfigurowaæ, więc od razu moŋemy uruchomiæ demona poleceniem:
# /etc/init.d/kdm start |
Pozostaģo nam jeszcze poinformowaæ nasz system, ŋe chcemy, aby nasz zarządca uruchamiaģ się po starcie systemu (na piątym poziomie).
Ustawienie poziomu pracy
W przypadku demonów GDM/KDM powinniķmy jeszcze skonfigurowaæ system tak, by domyķlnie uruchamiaģ się na piątym poziomie. pracy. Owe usģugi uruchamiają się tylko na tym poziomie, poza tym jest to domyķlny poziom dla aplikacji X-Window. Powinniķmy zmodyfikowaæ plik /etc/inittab, zgodnie ze wskazówkami przedstawionymi w sekcja Zmiana poziomu pracy systemu w rozdziaģ Administracja. Wiersz z opcją initdefault powinien wyglądaæ następująco:
id:5:initdefault: |
Porady
Naleŋy za wszelką cenę unikaæ logowania się jako administrator (root), jeķli chcemy uŋywaæ aplikacji wymagających wysokich uprawnieņ, powinniķmy je uruchamiaæ za pomocą programu sudo.
Karty firmy nVidia
Do zainstalowania kart graficznych firmy NVIDIA zalecamy wykorzystaæ firmowe sterowniki nvidia. Z serwerem X11 dostarczany jest sterownik nv jednak w stosunku do firmowych sterowników jest zdecydowanie wolniejszy, chociaŋ w przypadku wykorzystania rivafb jesteķmy zmuszeni do uŋycia otwartych sterowników nv.
Aby wczytaæ sterowniki firmowe, naleŋy za pomocą programu poldek zainstalowaæ pakiety:
# X11-driver-nvidia kernel-video-nvidia |
Następnie w wygenerowanym pliku konfiguracyjnym serwera X11 dokonujemy zmian w sekcji Device Card0:
Identifier "Card0" Driver "nvidia" VendorName "nVidia Corporation" BoardName "NV5M64 [RIVA TNT2 Model 64/Model 64 Pro]" BusID "PCI:1:0:0" Option "HWCursor" "on" Option "CursorShadow" "on" Option "DPMS" "on" Option "noDCC" "on" Option "NoLogo" "on" |
Czyli praktycznie zamieniamy ciąg znaków w linijce Driver z nv na nvidia.
Teraz wracamy do serwera X11 i jego testowego uruchomienia. W przypadku problemów standardowo zaglądamy w logi.
Karty firmy ATI
Do zainstalowania kart graficznych firmy ATI zalecamy wykorzystaæ firmowe sterowniki firegl. Z serwerem X11 dostarczane są takŋe otwarte sterowniki X11-driver-ati - jednak nie wykorzystują one wszystkich moŋliwoķci jakie dają sterowniki firegl i dopiero przy duŋych problemach z nimi moŋemy jako awaryjne skonfigurowaæ serwer X11 z otwartymi sterownikami ATI.
Instalacja i konfiguracja
Aby wczytaæ firegl, naleŋy za pomocą programu poldek zainstalowaæ pakiety:
# X11-driver-firegl kernel-video-firegl |
Następnie za pomocą programu fglrxconfig generujemy plik konfiguracyjny dla serwera X11. Oprócz pytaņ związanych z serwerem odpowiemy na szereg pytaņ dotyczących karty graficznej i monitora (moŋemy np. zdecydowaæ o tym czy chcemy pracowaæ w systemie jedno-monitorowym, czy teŋ z monitorem i odbiornikiem TV).
Wygenerowany plik, tak jak przedstawiono to w rozdziale dotyczącym instalacji X11 naleŋy z katalogu domowego uŋytkownika root do katalogu /etc/X11/ i dokonaæ ewentualnych korekt dotyczących myszy i obsģugi czcionek
Aby karta graficzna zostaģa poprawnie zainicjowana musimy wczytaæ odpowiednie moduģy kernela. Na początku musi to byæ moduģ, który umoŋliwi nam prace karty z AGP - moduģ ten jest zaleŋny od posiadanej pģyty gģównej. Przykģadowo dla pģyt z chipsetem nforce2 jest to moduģ:
# modprobe nvidia-agp |
Następnie wczytujemy moduģ kernela obsģugujący karty ATI:
# modprobe fglrx |
Aby zmiany byģy trwaģe, dopiszmy oba moduģy do pliku /etc/modules i wykonajmy polecenie depmod -a
Na koniec musimy się upewniæ, ŋe mamy zamontowany pseudo-system plików shm uŋywany do obsģugi dzielonej pamięci POSIX. Wymagany wpis w /etc/fstab wygląda następująco:
none /dev/shm tmpfs defaults 0 0 |
Test konfiguracji
Teraz moŋemy wróciæ do konfigurowania serwera X11 i jego testowego uruchomienia. Kiedy uruchomimy X-Window moŋemy sprawdziæ poprawnoķæ konfiguracji pomocą programów glxinfo oraz glxgears uruchamianych z emulatora terminala (np. xterm-a). Pierwszy z nich wyķwietla dokģadne informacje o naszej karcie i sterowniku, zaķ drugi to program do testowania wydajnoķci. Dobrze skonfigurowana karta graficzna pozwala osiągnąæ wydajnoķæ kilku tysięcy klatek na sekundę. W przypadku problemów standardowo zaglądamy w logi.
V. Tworzenie PLD - Praktyczny poradnik
Moŋliwa droga do zostania szeregowym developerem PLD
Co jest potrzebne
Kaŋdego uŋytkownika Linuxa pracującego na swojej maszynie nachodziģa refleksja na tematy filozoficzne - kto to wymyķliģ? kto to zrobiģ? i jak to zrobiģ? Pytania ciekawe - Prezentując sposób pracy przy PLD moŋemy częķciowo zrozumieæ mechanizmy tworzenia takich projektów.
Naszym miejscem pracy będzie samo PLD i dodatki, które poniŋej spróbuje opisaæ. W chwili pisania tego tekstu byģa to wersja 1.0 ''Ra''. Póžniej jest juŋ z górki - instalujemy parę pakietów - sam proces instalacji w praktycznie zostanie pominięty, gdyŋ uŋytkownicy juŋ powinni wiedzieæ co to jest poldek i jak się go uŋywa.
# rpm -qa |grep rpm rpm-4.0.2-106 rpm-build-tools-4.0.2-106 rpm-utils-4.0.2-106 rpm-perlprov-4.0.2-106 rpm-build-4.0.2-106 rpm-devel-4.0.2-106 rpm-pythonprov-4.0.2-106 # rpm -qa |grep cvs cvs-1.11.5-2 # rpm -qa |grep mc mc-4.5.55-10 |
Zwrócę uwagę tylko na CVS. Sposób instalacji ķrodowiska bardzo dobrze opisuje Baseciq - ten krok naleŋy wykonaæ ze szczególną starannoķcią
Innym waŋnym pakietem jest rpm plus dodatki. Gģównym zajęciem szeregowego developera jest tworzenie lub modyfikacja plików .spec, które są gģównym czynnikiem budowania pakietów RPM. Są jeszcze potrzebne róŋne inne pakiety i žródģa - ale to juŋ w zaleŋnoķci od tego co będziemy budowaæ.
Žródģa wiedzy
Największą skarbnicą wiedzy o RPMie i budowaniu pakietów moŋemy znaležæ w publikacji Maximum RPM - opis jest w języku angielskim i nie jest mi znane tģumaczenie na nasz język. Na szczęķcie są jeszcze inne žródeģka, a takŋe i niniejszy opis - więc powinno nam byæ lŋej przyswajaæ wiedzę. Szczególnie polecam stronę Grzegorza Niewęgģowskiego (lub lokalną kopię) gdzie duŋo teorii i praktycznych rad moŋe nam rozjaķniæ w naszych gģowach czym jest praca ze "specami".
Jest dostępny takŋe opis stworzony przez Developera PLD lecz z tego co się dowiedziaģem jest juŋ trochę leciwy i niektóre dane mogą byæ nieķcisģe.
Po tej bombie teorii jaką niestety musimy przejķæ, czeka nas przestudiowanie jeszcze jednego dokumentu, którego najnowszą wersję moŋemy ķciągnąæ z CVS PLD. Będzie to nasze pierwsze æwiczenie.
Uruchamiamy terminal (czy to zwykģy, czy teŋ np. przez SSH) i wykonujemy kroki:
$ cd rpm $ cvs get PLD-doc/devel-hints-pl.txt U PLD-doc/devel-hints-pl.txt $ |
Jak widaæ kroki wykonujemy jako zwykģy uŋytkownik (nie root) i tej zasady będziemy się konsekwentnie trzymali.
Do katalogu ~/rpm/PLD-doc/ ķciągneliķmy z repozytorium PLD dokument tekstowy devel-hints-pl.txt. W tym dokumencie zawarte są zalecenia i ustalenia jakich powinniķmy się trzymaæ aby tworzyæ wģaķciwe dla PLD pakiety RPM.
Przykģad budowania
Teraz spróbujemy ķciągnąæ jakiķ .spec z CVS PLD i zbudujemy sobie jakąķ paczkę - np. pakiet tar (przykģad budowania 'ekg' mogliķmy obejrzeæ takŋe podczas instalacji CVS na stronie Baseciq):
$ cd rpm
$ cvs get SPECS/tar.spec
U SPECS/tar.spec
$ cd SPECS/
$ rpmbuild -ba tar.spec
bģąd: File /home/users/marekc/rpm/SOURCES/tar-1.13.25.tar.gz: \
Nie ma takiego pliku ani katalogu
$ ./getsrc tar.spec
Trying to download sources for tar-1.13.25-7
Searching for file: tar-1.13.25.tar.gz
Trying CVS... OK
Searching for file: tar-non-english-man-pages.tar.bz2
Trying CVS... OK
Searching for file: tar-man_from_debian_tar_1.13.25-2.patch
Trying CVS... OK
Searching for file: tar-info.patch
Trying CVS... OK
Searching for file: tar-pipe.patch
Trying CVS... OK
Searching for file: tar-namecache.patch
Trying CVS... OK
Searching for file: tar-error.patch
Trying CVS... OK
Searching for file: tar-sock.patch
Trying CVS... OK
Searching for file: tar-nolibrt.patch
Trying CVS... OK
Searching for file: tar-man.patch
Trying CVS... OK
Searching for file: tar-ac25x.patch
Trying CVS... OK
Searching for file: tar-dots.patch
Trying CVS... OK
Searching for file: tar-pl.po-fix.patch
Trying CVS... OK
Download opreation completed: all files retrieved successfully |
W przykģadzie, za szybko chcieliķmy zbudowaæ pakiet - zaraz po ķciągnięciu ''tar.spec''.
Sam .spec bez žródeģ jest jak karabin bez amunicji... Moŋna wykorzystaæ skrypt 'builder' (i póžniej nawet zalecam go uŋywaæ) w katalogu SPECS, który to sam przeanalizuje potrzeby i ķciągnie odpowiedniego .speca (oczywiķcie jeŋeli tylko zawiera go repozytorium CVS), žródģa i wykona paczki rpm i srpms - ale my nie będziemy tutaj sobie za bardzo uģatwiaæ pracy :-)
Po ķciągnięciu plików dobrze jest obejrzeæ danego .speca aby zobaczyæ, co jest jeszcze potrzebne do zbudowania - moŋna to zrobiæ zwykģym edytorem tekstowym lub wykonaæ:
$ cat tar.spec |grep BuildReq BuildRequires: autoconf BuildRequires: automake BuildRequires: bison BuildRequires: gettext-devel |
Wiemy juŋ co nam jest potrzebne - Teraz sprawdzimy czy mamy te pakiety w naszym PLD:
$ rpm -q autoconf autoconf-2.53a-1 $ rpm -q automake automake-1.6.3-1 $ rpm -q bison pakiet bison nie jest zainstalowany $ rpm -q gettext-devel pakiet gettext-devel nie jest zainstalowany $ |
Czyli dwóch, potrzebnych pakietów brak. A więc 'poldek' rusza do boju (tutaj juŋ lepiej uŋyæ konta 'root' - chyba ŋe mamy poldka skonfigurowanego do pracy 'sudo'):
# poldek Wczytywanie ftp://ftp.pld-linux.org/dists/[...]/RPMS/packages.dir.gz... Wczytywanie ftp://ftp.pld-linux.org/dists/ra/[...]/packages.dir.gz... Wczytywanie ftp://ftp.pld-linux.org/dists/ra/[...]/packages.dir.gz... Wczytywanie ftp://ep09.kernel.pl/pub/People/[...]/packages.dir.gz... Wczytywanie ftp://ftp.pld-linux.org/dists/[...]/packages.dir.gz... Wczytywanie http://pld.mysza.eu.org/Ra/i686/packages.dir.gz... Przeczytano 6814 pakietów Usunięto 16 zdublowanych pakietów z listy dostępnych Wczytywanie /root/.poldek-cache/packages.dir.dbcache.var.lib.rpm.gz... Przeczytano 559 pakietów Witaj w poldekowym trybie interaktywnym. Wpisz "help" aby otrzymaæ pomoc. poldek> install bison gettext-devel Przetwarzanie zaleŋnoķci... Zaznaczono 1 pakiet do instalacji: I bison-1.35-5 Pobieranie ftp://ftp.pld-linux.org/dists/[...]/bison-1.35-5.i686.rpm... .................................................. 100.0% [196.5K] Uruchamianie rpm --upgrade -vh --root / --noorder... Preparing... ########################################### [100%] 1:bison ########################################### [100%] Installing set #2 Przetwarzanie zaleŋnoķci... Zaznaczono 1 pakiet do instalacji: I gettext-devel-0.10.40-4 Pobieranie ftp://[...]/gettext-devel-0.10.40-4.i686.rpm... .................................................. 100.0% [295.6K] Uruchamianie rpm --upgrade -vh --root / --noorder... Preparing... ########################################### [100%] 1:gettext-devel ########################################### [100%] poldek> |
I jak tu nie kochaæ Poldka? :-)
Mamy juŋ teoretycznie wszystko aby zbudowaæ pakiet 'tar'. Wracamy więc do naszego zwykģego konta i:
$ rpmbuild -ba tar.spec Executing(%prep): /bin/sh -e /var/tmp/rpm-tmp.22007 Patch #0 (tar-man_from_debian_tar_1.13.25-2.patch): Patch #1 (tar-info.patch): Patch #2 (tar-pipe.patch): Patch #3 (tar-namecache.patch): Patch #4 (tar-error.patch): Patch #5 (tar-sock.patch): Patch #6 (tar-nolibrt.patch): Patch #7 (tar-man.patch): Patch #8 (tar-ac25x.patch): Patch #9 (tar-dots.patch): Patch #10 (tar-pl.po-fix.patch): Executing(%build): /bin/sh -e /var/tmp/rpm-tmp.97619 [...] Zapisano: /home/users/marekc/rpm/SRPMS/tar-1.13.25-7.src.rpm Zapisano: /home/users/marekc/rpm/RPMS/tar-1.13.25-7.i686.rpm Executing(%clean): /bin/sh -e /var/tmp/rpm-tmp.54009 + umask 022 + cd /home/users/marekc/rpm/BUILD + _autoreqprov=n + [ n = y ] + cd tar-1.13.25 + rm -rf /home/users/marekc/tmp/tar-1.13.25-root-marekc + exit 0 $ |
[...] oznacza, wycięte przeze mnie komunikaty jakie generuje kompilowany 'tar'.
Polecenie 'rpmbuild -ba ' kaŋe nam zbudowaæ ze speca kompletny pakiet - ale to juŋ wiemy z teoretycznych szkoleņ ;-)
Wszelkie komunikaty w razie jakiegoķ bģędu podczas budowania moŋemy odnaležæ w pliku: '/var/tmp/rpm-tmp.22007'
Widzimy, ŋe gotowe pakiety mamy w okreķlonych katalogach i moŋemy je spokojnie zainstalowaæ. A komunikat 'exit 0' oznacza brak bģędów podczas budowania.
Nasz pierwszy pakiet zostaģ zbudowany.
Pozostaje jednak niedosyt - ciągle czujemy, ŋe jak na razie korzystamy z czyjeķ pracy, a w koņcu pragniemy takŋe coķ zrobiæ dla potomnoķci i sami chcemy stworzyæ plik .spec
Pierwszy spec
No to zaczynamy. Naszym pierwszym (a wģaķciwie moim) wykonanym specem będzie Mantis czyli system kontroli bģędów oparty o stronę WWW (PHP) i bazę SQL Mysql.
Tutaj maģa dygresja - większoķæ pakietów powstaje dlatego, ŋe danemu Developerowi byģ on akurat potrzebny; oznacza to ŋe nie ma sensu pisanie na listę dyskusyjną z proķbą o stworzenie okreķlonego pakietu bo moŋna otrzymaæ parę przykrych komentarzy (w najlepszym razie).
Pierwszą czynnoķcią jest zainstalowanie pakietu ze žródeģ. Potem notujemy sobie co naleŋy zrobiæ aby dany pakiet zacząģ dziaģaæ - wszystko po to aby przewidzieæ co dany .spec powinien zrobiæ aby pakiet pracowaģ w miarę bezproblemowo po instalacji RPMa - Moŋna to zanotowaæ np. na kartce papieru - ale od czego mamy komputery?
Moje notatki wyglądaģy tak:
// MANTIS
// Mysql init
# cd /etc/rc.d/init.d
# ./mysql init
# /usr/bin/mysqladmin -u mysql password 'password'
// Tworzenie bazy w mysql
# mysqladmin -umysql -p create bugtracker
# cd /mantis/sql
# mysql -umysql -p bugtracker < db_generate.sql
// Plik config_inc.php
// Sprawdzenie i poprawka
http:/mantis/admin/check.php
// Pierwsze logowanie
u: administrator
p: root
Dodaæ nowe i skasowaæ stare :-)
// co potrzebne do uruchomienia
- mysql
- mysql-client
- php
- php-common
- php-pcre
- php-mysql
- apache
// do rpma (zmiany w związku z językiem)
plik: config_defaults_inc.php
$g_default_language = 'english';
$g_default_language = 'polish';
// Zamiana ģaņcucha w config_defaults_inc.php
sed -e s/$g_default_language = 'english';/$g_default_language = 'polish';/g
config_defaults_inc.php
// Zamiana usera z root na mysql
w config_inc.php |
Do kaŋdego pakietu naleŋy podchodziæ indywidualnie - dlatego parę sģów o samym mantisie. System jest oparty o gotowe pliki skģadające się na stronę WWW, dokumentacje i plik potrzebny do stworzenia odpowiedniej bazy Mysql. Nie będziemy dokonywali ŋadnych kompilacji - więc uproķci to nasz proces budowania i testowania pakietu.
Ģącząc informacje zawarte w dostarczonej dokumentacji i wģasnych notatek wiemy juŋ ŋe gģównym zadaniem naszego RPMa będzie takie zaprojektowanie go, aby odpowiednie pliki PHP zostaģy przekopiowane w odpowiednie miejsce, dokonaæ niezbędnych poprawek w plikach konfiguracyjnych lub innych poprawek, które naszym zdaniem mogą uģatwiæ pracę przyszģym uŋytkownikom. Pamiętajmy jednak ŋeby nie przedobrzyæ.
Niestety nie wszystko uda nam się zautomatyzowaæ - dlatego stworzymy dwa pliki tekstowe (w dwóch wersjach językowych PL i EN) z krótkim opisem, co naleŋy wykonaæ aby system zadziaģaģ.
Wydaje mi się takŋe, ŋe dobrym zwyczajem jest po zainstalowaniu žródeģ przewidzieæ wģaķciwe zaleŋnoķci, aby nasz pakiet dziaģaģ bez problemu na innym komputerze. Na przykģad w instrukcji do instalacji mantisa w wymaganiach jest wymieniony m.in. pakiet PHP - W PLD po instalacji samego PHP, mantis będzie wyķwietlaģ bģędy. Okazuje się ŋe pakiety w PLD są maksymalnie ''rozdrobnione'' i do dziaģania potrzebny jest jeszcze pakiet 'php-pcre' - a do tego, ŋeby strony PHP odpowiednio komunikowaģy się z bazą 'mysql' jest potrzeba zainstalowania 'php-mysql'. Zaleŋnoķci moŋe byæ wiele i moim skromnym zdaniem lepiej ŋebyķmy umieķcili jakiķ nadmiarowy pakiet w zaleŋnoķciach niŋ ŋeby jakiegoķ brakowaģo.
W naszym przypadku po zainstalowaniu i uruchomieniu pakietu Mantis ze žródeģ, wystarczy wykonaæ np. 'rpm -qa |grep php' aby wybraæ odpowiednie pliki. To samo robimy z 'mysql' i 'apache'.
Zaczynamy od stworzenia pliku (moŋemy uŋyæ polecenia 'touch') lub korzystamy z innego pliku .spec w celu modyfikacji do naszych potrzeb (np. 'cvs get SPECS/template.spec' spowoduje ķciągnięcie szkieletu z CVS PLD). Otwieramy go w naszym ulubionym edytorze tekstowym (vim, emacs, pico, mcedit itp.)
Summary: The Mantis Bug Tracker Summary(pl): Mantis - System Kontroli Bģędów Name: mantis Version: 0.18.0a4 # define _alpha a4 Release: 1 License: GPL Group: Development/Tools [...] |
Zaczynamy wypeģniaæ tzw. preambuģę, czyli wstęp w którym opisujemy nasz pakiet - myķlę, ŋe wyjaķnianie powyŋszego nie jest specjalnie potrzebne. Zwrócę tylko uwagę na linię 'Version' i 'Ralease' - zgodnie z devel-hints-pl.txt powinno ono raczej wyglądaæ tak (poniewaŋ ta wersja mantis'a jest okreķlona jako alpha):
Version: 0.18.0 %define alpha a4 Release: 0.%{_alpha}.1
ale u mnie powodowaģo to bģąd przy budowaniu, gdyŋ jak dalej zobaczymy nazwa žródeģ korzysta z pola 'Version' i kaŋda manipulacja na nim powoduje potrzebę przebudowania .speca lub zmianę nazwy archiwum w którym są žródģa (co jest bardzo zģym nawykiem i karygodnym bģędem!). Tak więc w koņcu zostawiģem tak jak jest i nikt specjalnie nie zwróciģ mi na to uwagi :-) (przyp. autora: jednak póžniejsza praktyka pokaŋe nam, ŋe zmiany takie są jednak chlebem powszednim więc nie bójmy się ich dokonywaæ)
[...]
Source0: http://dl.sourceforge.net/mantisbt/%{name}-%{version}.tar.gz
# Source0-md5: 4c730c1ecf7a2449ef915387d85c1952
Source1: %{name}-doc-PLD.tar.gz
URL: http://mantisbt.sourceforge.net/
[...] |
Dalej mamy opis žródeģek - w PLD podaje się go najczęķciej w formie linku plus fraza %{name}-%{version}.tar.gz i tak naprawdę ta fraza jest najwaŋniejsza do zbudowania pakietu, poniewaŋ URL (w naszym przypadku http://dl.sourceforge.net/mantisbt/) jest ignorowany. Tak więc z makra %name i %version budowana jest nazwa pakietu i taka nazwa jest wyszukiwana w ~/rpm/SOURCES/
Žródeģ programu moŋe byæ kilka. U nas występuje jeszcze Source1 - jest to dodatkowa dokumentacja skģadająca się z dwóch plików tekstowych zawierająca dodatkowe wskazówki po instalacyjne. Pierwotnie próbowaģem zrobiæ to korzystając z mechanizmu Patch i polecenia:
diff -urN katalog_z_oryginaģem katalog_z_poprawionym_oryginaģem > žródģa-powód.patch
opisanego w devel-manual (rozdziaģ 1.2.2), ale mechanizm ten nie pozwala tworzyæ nowych plików więc pozostaģo tylko wykonaæ dodatkowe žródģa.
Pamiętajmy takŋe aby w ŋadnym przypadku nie modyfikowaæ ręcznie žródeģ programu. Prawidģowy .spec powinien wykorzystywaæ natywne žródģa, a wszelkie zmiany dokonujemy w %build, %install lub za pomocą patch'ów.
Sygnatura md5 po # jest wynikiem wykorzystania tzw. distfiles i na razie to musi nam wystarczyæ. Distfiles omówimy gdy będziemy zapisywaæ do CVS PLD - czyli nieprędko ;-)
[...]
Requires: apache >= 1.3.27-4
Requires: apache-mod_dir >= 1.3.27-4
Requires: php >= 4.0.3
Requires: php-mysql >= 4.0.3
Requires: php-pcre >= 4.3.1-4
Requires: php-common >= 4.3.1-4
Requires: mysql >= 3.23.2
Requires: mysql-client >= 3.23.56-1
Requires: sed
BuildArch: noarch
BuildRoot: %{tmpdir}/%{name}-%{version}-root-%(id -u -n)
[...] |
W 'Requires' podajemy zaleŋnoķci, czyli co musi byæ zainstalowane aby dany pakiet dziaģaģ lub ŋeby wykonaģy się poprawnie polecenia wykonywane przez .spec (np. sekcja %post)
W 'BuildArch' architekturę pod który przeznaczony jest RPM - u nas jest to 'noarch' czyli bez ŋadnej konkretnej architektury - z moich obserwacji wynika ŋe developerzy PLD omijają to pole - chyba ŋe jest to wģaķnie 'noarch'.
'BuildRoot' jest bardzo waŋnym tagiem - na szczęķcie występuje zawsze w takiej postaci jak u nas - a oznacza katalog w którym rpm będzie budowaģ pakiet z sekcji %install naszego .speca.
[...]
%define _mantisdir /home/services/httpd/mantis
# define _mantisdir /home/httpd/html/mantis
%description
Mantis is a web-based bugtracking system.
%description -l pl
Mantis jest systemem kontroli bģędów opartym na interfejsie \
WWW i MySQL.
[...] |
W tej częķci wykorzystujemy przydatną wģaķciwoķæ RPMa czyli definiowanie staģych. W naszym przykģadzie '_mantisdir' jest katalogiem w którym będą zainstalowane pliki dla serwera WEB. Tutaj maģa uwaga dotycząca komentarza '#' - Gdy definiujemy makro wtedy komentarz nie dziaģa, dlatego usunęliķmy '%' przed sģowem 'define' (moŋemy takŋe uŋyæ frazy '%%') czyli gdybyķmy napisali:
%define _mantisdir /home/services/httpd/mantis
# %define _mantisdir /home/httpd/html/mantis
To wtedy staģa '_mantisdir' miaģa by wartoķæ /home/httpd/html/mantis, mimo ŋe nie taka jest nasz intencja - Nie muszę chyba wyjaķniaæ jakie to moŋe spowodowaæ problemy?
W '%description' opisujemy krótko charakterystykę pakietu, a niŋej widzimy jak to zrobiæ dla opisu w języku polskim - póžniej RPM wykorzystując zmienne locale wyķwietla odpowiednią wersję językową 'description' gdy sobie tego od RPMa ŋyczymy.
[...] %prep %setup -q -a1 [...] |
Od tego momentu skoņczyliķmy wypeģniaæ dane preambuģy. Sekcja %prep moŋe wykonaæ skrypt potrzebny przed instalacją plików. My akurat nic przed instalacją robiæ nie musimy dlatego sekcja ta jest pusta.
Dalej jest '%setup -q -a1' - czyli rozpakowanie žródeģ do katalogu zdefiniowanego wczeķniej przez 'BuildRoot'. Dodatkowe parametry tego tagu wyģączają komunikaty przy rozpakowaniu '-q', a parametr '-a1' okreķla które žródģa naleŋy rozpakowaæ. Po '%setup' moŋemy takŋe korzystaæ z makra '%patch' który nakģada ģatki na žródģa. Umoŋliwia to taką modyfikację žródeģ jakie tylko chcemy bez potrzeby zmian w samych žródģach (o czym pisaliķmy wczeķniej).
[...]
%install
rm -rf $RPM_BUILD_ROOT
install -d $RPM_BUILD_ROOT%{_mantisdir}
cp -af *.php admin core css graphs images lang sql \
$RPM_BUILD_ROOT%{_mantisdir}
sed -e 's/root/mysql/g' config_inc.php.sample > \
$RPM_BUILD_ROOT%{_mantisdir}/config_inc.php
[...] |
Tak naprawdę w większoķci pakietów przed '%install' wykonywane jest makro '%build', które kompiluje nam žródģa, a w najprostszej postaci wygląda tak:
%build %configure make
U nas nie ma potrzeby wykonywania ŋadnych kompilacji więc od razu wykonywana jest sekcja '%install'. Na początku czyķcimy sobie katalog w którym będziemy instalowali nasz program (czyli 'fake root') - mimo ŋe prawdopodobnie jest pusty - ale lepiej dmuchaæ na zimne. Potem dokonujemy instalacji pakietu przekazując mu w parametrze '-d' ŋe docelowo ma byæ zainstalowany w 'fake root', ale same pliki pojawią się w naszym katalogu tymczasowym (TMPDIR), dlatego póžniej za pomocą polecenia 'cp' kopiujemy pliki, jakie są potrzebne, do wģaķciwego 'fake root' - zauwaŋmy ŋe pominęliķmy np. katalog 'doc'.
Następnie jeszcze za pomocą komendy 'SED' dokonujemy drobnej poprawki w pliku konfiguracyjnym mantisa - zamieniając domyķlnego uŋytkownika MYSQL z 'root' na 'mysql'. Taką poprawkę mogliķmy wykonaæ wczeķniej w sekcji '%prep' i tagu '%patch' ale przy tak maģych poprawkach bardziej efektywniej jest to zrobiæ tutaj.
[...] %clean rm -rf $RPM_BUILD_ROOT [...] |
Tag '%clean' jest w .specach tworzonych dla PLD obowiązkowy i okreķla co naleŋy zrobiæ gdy caģy pakiet zostanie zbudowany. Tutaj maģa uwaga - ten tag w tym miejscu nie oznacza ŋe jest w tej chwili wykonany - jeŋeli by tak byģo, to występujący póžniej tag '%files' miaģby niejakie problemy z nieistniejącymi juŋ plikami. Czyli po poprawnym zbudowaniu pakietu, wykonywane jest makro '%clean', a w przypadku jakiegokolwiek bģędu, nie jest - czyli rozpakowane i zainstalowane žródģa pozostają. Umoŋliwia nam to np. diagnostykę w przypadku bģędów podczas budowania pakietu.
[...]
%post
if [ "$LANG" = "pl_PL" ]; then
#sed -e "s/= 'english';/= 'polish';/g" \
%{_mantisdir}/config_defaults_inc.php > \
#%{_mantisdir}/config_defaults_inc_PLD.php
#mv -f %{_mantisdir}/config_defaults_inc_PLD.php \
%{_mantisdir}/config_defaults_inc.php
echo
echo "Mantis zapisany..."
echo "Więcej: /usr/share/doc/mantis-%{version}/PLD_Install_PL.txt.gz"
echo
else
echo
echo "Mantis loaded..."
echo "More: /usr/share/doc/mantis-%{version}/PLD_Install_EN.txt.gz"
echo
fi
[...] |
Tutaj mamy przykģad co moŋemy zrobiæ z plikami, które będą instalowane po zbudowaniu pakietu. Makro '%post' wykonywane jest przez RPM podczas instalacji pakietu. Zakomentowane polecenia umoŋliwiają zmianę w zainstalowanym pliku 'config_defaults_inc.php' zgodnie z zawartoķcią zmiennej locale 'LANG'. Póžniej w zaleŋnoķci od tej zmiennej wyķwietlany jest komunikat w języku PL lub EN.
Zadacie pytanie dlaczego częķæ tych poleceņ jest ''wyģączona" - otóŋ, póžniej gdy dany .spec chcemy juŋ udostępniæ ogóģowi zostanie on sprawdzony pod względem ''czystoķci rasowej'' :-) - W tym przypadku okazaģo się, ŋe taka zmiana w plikach konfiguracyjnych, moŋe spowodowaæ kģopoty podczas np. zmiany uŋytkownika. Programy korzystające z 'locale' powinny odpowiednio reagowaæ na zmiany 'locale' - np. po modyfikacji LANG na 'EN_en' zacząæ pracowaæ po angielsku - W naszym przypadku strona PHP nie zacznie pracowaæ po angielsku, dlatego dodany zostaģ w/w komentarz, a w pliku 'PLD_Install_PL.txt.gz', który jest dodatkową instrukcją, co naleŋy zrobiæ po instalacji pakietu RPM aby 'mantis' po uruchomieniu rozmawiaģ z nami po polsku.
[...]
%files
%defattr(644,root,root,755)
%doc doc/* PLD_Install_PL.txt PLD_Install_EN.txt config_inc.php.sample
%dir %{_mantisdir}
%{_mantisdir}/admin/
%{_mantisdir}/core/
%{_mantisdir}/css/
%{_mantisdir}/graphs/
%{_mantisdir}/images/
%{_mantisdir}/lang/
%{_mantisdir}/sql/
%{_mantisdir}/account*
%{_mantisdir}/bug*
%{_mantisdir}/core.*
%{_mantisdir}/csv*
%{_mantisdir}/docum*
%{_mantisdir}/file*
%{_mantisdir}/history*
%{_mantisdir}/index*
%{_mantisdir}/jump*
%{_mantisdir}/log*
%{_mantisdir}/ma*
%{_mantisdir}/me*
%{_mantisdir}/news*
%{_mantisdir}/print*
%{_mantisdir}/proj*
%{_mantisdir}/set*
%{_mantisdir}/sig*
%{_mantisdir}/sum*
%{_mantisdir}/view*
%config(noreplace) %{_mantisdir}/config_inc.php
%config(noreplace) %{_mantisdir}/config_defaults_inc.php
%exclude %{_mantisdir}/core/.cvsignore
[...] |
Dochodzimy powoli do finaģu :-). W sekcji tej okreķlamy co, gdzie i jak ma zostaæ zainstalowane u uŋytkownika instalującego naszego RPMa. Tag %files jest bardzo waŋny gdyŋ bģędy spowodowane tutaj mogą uniemoŋliwiæ dziaģanie pakietu u koņcowego uŋytkownika. W 'podtagu':
%defattr(644,root,root,755)
okreķlamy domyķlne atrybuty instalowanych plików - moŋemy oczywiķcie okreķlaæ atrybuty dla kaŋdego pliku osobno.
Następnie w:
%doc doc/* PLD_Install_PL.txt PLD_Install_EN.txt config_inc.php.sample
okreķlamy nasze pliki, które znajdą się w dokumentacji. Czyli katalog 'doc/' z katalogu 'TMPDIR' i pliki z 'SOURCE1' oraz 'config_inc.php.sample' zostaną spakowane i przy instalacji pakietu RPM umieszczone w domyķlnym katalogu dokumentacji - w PLD jest to /usr/share/doc/...
I wreszcie w:
%dir %{_mantisdir}
nakazujemy podczas instalacji RPM'a stworzenie katalogu zgodnie ze staģą '%{_mantisdir}' i kopiujemy pliki jakie są poniŋej tego tagu. Na początku nie wypisywaģem wszystkich tych katalogów i plików indywidualnie, a po prostu uŋyģem frazy:
%{_mantisdir}
Jednak przy takiej konstrukcji i wykorzystaniu makra %config(noreplace), pojawi się bģąd podczas budowania pakietu:
[...] RPM build errors: File listed twice: /home/services/httpd/mantis/config_defaults_inc.php File listed twice: /home/services/httpd/mantis/config_inc.php |
Czyli dwa pliki miaģy podwójne znaczenie - występowaģy na liķcie do skopiowania i jako pliki konfiguracyjne. Dlatego trzeba niestety zrobiæ listę plików jak to my zrobiliķmy minus pliki, które znajdą się w makro '%config'. Samo makro '%config' pozwala szczególnie traktowaæ pliki konfiguracyjnie podczas kasowania RPMa lub jego aktualizacji.
Ostatnie makro:
'%exclude %{_mantisdir}/core/.cvsignore'
nakazuje wyģączenie pliku z pakietu RPM - w tym przypadku jest to pozostaģoķæ po CVS mantisa.
I to juŋ koniec naszej pracy. Po wykonaniu polecenia 'rpmbuild -ba mantis.spec' powinien nam zbudowaæ się pakiet rpm i srpm. Zostaje jeszcze przetestowanie czy wszystkie pliki są tam gdzie chcieliķmy, czy mają odpowiednie prawa i czy pakiet dziaģa tak jak powinien. Jeszcze ewentualne poprawki i musimy przepuķciæ naszą pracę przez zestaw adaptujący 'adapter.awk'.
Ķciągamy go z CVSu:
$ cvs get SPECS/adapter.awk U SPECS/adapter.awk $ |
następnie zmieniamy nazwę pliku .speca dodając na koņcu np. org i wykonujemy:
$ ./adapter.awk mantis.spec.org > mantis.spec $ |
W wyniku tej operacji otrzymamy 'mantis.spec' który zostaje przystosowany do wymagaņ PLD. Zainteresowanych zmianami, zapraszam do przestudiowania 'nowego' .speca.
Teraz moŋemy szukaæ kogoķ, kto umieķci naszego .speca i žródģa w repozytorium CVS PLD. Mamy do dyspozycji listę developerów: w mailu umieszczając zaģącznik z naszym .specem (oczywiķcie bez žródeģ - lub jeŋeli mamy jakieķ wģasne žródģa to umieszczamy je na jakieķ stronie WWW lub innym ftp. i podajemy linka - žródģa natywne powinny daæ się ķciągnąæ z lokacji jaką umieķciliķmy w naszym .specu.). Zaģącznik powinien byæ typu plain-text.
Moŋna takŋe spróbowaæ na grupie IRC #PLD znaležæ ofiarę, która umieķci naszą pracę w repozytorium.
Dobrze teŋ w czasie nauki robienia .speców podglądaæ jak to robią inni - W repozytorium CVS jest naprawdę z czego wybieraæ. A my nabywając umiejętnoķæ czytania plików .spec moŋemy skupiæ się juŋ tylko na odpowiednim ich napisaniu.
W koņcu otrzymamy moŋliwoķæ zapisu do CVS i wtedy czytamy następną częķæ poradnika ''W krainie CVS''
W krainie CVS - czyli wielki kocioģ
Wstęp
Umiemy juŋ w miarę kleciæ nowe spece, naprawiaæ stare - chcemy doģączyæ do druŋyny PLD... Musimy mieæ więc moŋliwoķæ pogrania na boisku, a nie tylko zasiadaæ na trybunach jako widz. Naszym boiskiem będzie CVS a moŋliwoķæ czytania i pisania do niego (Read-Write) naszym sposobem na grę :)
Jak to ŋyciu, aby coķ dostaæ musimy najpierw się postaraæ i wykonaæ parę czynnoķci.
Ŋeby otrzymaæ wģasne konto CVS naleŋy uzyskaæ poparcie juŋ aktywnych deweloperów. Zwykle osoby wykazujące się aktywnoķcią na listach dyskusyjnych (podsyģające patche, itp.) prędzej czy póžniej są wręcz proszone o zgģoszenie się po konto. W typowym przypadku wystarczy, ŋe trzech deweloperów wyrazi poparcie kandydata na dewelopera (trzeci z nich powinien wskazaæ mu dokąd powinien się zgģosiæ po konto). Osoba popierająca kandydata jednoczeķnie staje się jego opiekunem i nadzoruje jego dziaģania w początkowej fazie. W przypadku gdyby, mimo poparcia przez niektórych, osoba kandydata wywoģywaģa kontrowersje, decyzja o jego przyjęciu (lub nie) będzie podjęta zgodnie z obowiązującą procedurą rozwiązywania konfliktów.
Kiedy juŋ zostaniemy przyjęci, musimy wymyķleæ sobie ksywkę i hasģo. Potem z linii poleceņ wykonujemy jednolinijkowe polecenie - wstawiając za login i haslo odpowiednie dane:
perl -e 'print "login:" . crypt("haslo", join "", (".", "/", 0..9, "A".."Z", "a".."z")[rand 64, rand 64]) . "\n"'
w wyniku którego otrzymamy ciąg znaków podobny do:
login:/APGG.cfeqPpk
Ciąg ten kopiujemy do listu e-mail z proķbą o moŋliwoķæ RW na CVS PLD i wysyģamy na adres cvsadmin@pld-linux.org
To na razie wszystko co moŋemy zrobiæ - trzeba czekaæ na odpowiedž od wģadzy CVS. Po kilku, kilkunastu lub kilkudziesięciu dniach przyjdzie mail z odpowiedzią. U mnie byģa to wiadomoķæ podobna do:
Quoting Marek Ciesielski <marekc@adres.email>:
> Prosze o dostep RW do CVS PLD.
> dane do <login>:/APGG.cfeqPpk // oczywiķcie tej linii
// w mailu nie ma - dodaģem ją dla przykģadu :)
Witam,
twoje konto zostaģo zaģoŋone, proszę dopisz się do CVSROOT/users
--
Admin CVS <imię i nazwisko> :) |
Czyli pierwsze formalnoķci mamy za sobą. Moŋemy juŋ dziaģaæ na CVS. Jednak proponuję znowu trochę teorii - tym razem zdecydowana większoķæ dokumentacji jest w języku angielskim. Mamy więc bardzo dobry, oficjalny podręcznik CVS (uwaga ponad 800KB), ksiąŋkę kucharską CVS (uwaga ponad 600KB) - jest takŋe opis po polsku - stworzony przez developerów PLD, a takŋe ksiąŋka z cyklu leksykon kieszonkowy "CVS" Gregor N. Purdy (koszt ok. 10PLN) - tak więc jest w czym wybieraæ.
Jeszcze raz zwróæmy uwagę na maila którego otrzymaliķmy. Jest tam coķ o dopisaniu "users". Musimy wykonaæ zalecenie. Aby to zrobiæ musimy znowu przygotowaæ sobie ķrodowisko CVS - albo modyfikując istniejące, dotychczasowe konto "anonymous" albo tworząc od początku ķrodowsko w nowym katalogu. Ja wybraģem pierwszy sposób (trochę wbrew zaleceniom z dokumentacji - ale za to szybszy), polega on na modyfikacji kaŋdego pliku "Root" w podkatalogach "CVS" - naleŋy tam wpisaæ frazę:
:pserver:<nasz_login>@cvs.pld-linux.org:/cvsroot
Czyli w naszym przypadku wchodzimy do katalogu ./rpm i wchodzimy do kaŋdego podkatalogu "CVS" i zmieniamy ręcznie plik "Root" - nie ma w tej chwili tych katalogów wiele, więc nie powinno to sprawiæ kģopotu.
Proponuję takŋe poustawiaæ sobie zmienne CVS np. CVSEDITOR itp. (szczegóģy - oczywiķcie dokumentacja).
Następnie moŋemy juŋ spróbowaæ zalogowaæ się do CVS PLD:
$ cvs login Logging in to :pserver:<nasz_login>@cvs.pld-linux.org:2401/cvsroot CVS password: $ |
Wpisujemy hasģo które wymyķleliķmy i jesteķmy zalogowani. Kaŋdy komunikat bģędu oznacza ŋe coķ wczeķniej žle wykonaliķmy, albo ŋe np. nie dziaģa sieæ. Login wykonujemy praktycznie raz i dopóki nie wykonamy polecenia "cvs logout" jesteķmy ciągle gotowi do pracy.
Czas juŋ zabraæ się za plik "users"
$ cvs get CVSROOT/users U CVSROOT/users $ |
Do naszego lokalnego repozytorium, do katalogu CVSROOT ķciągneliķmy plik users, który sģuŋy w PLD do wpisania aliasu pocztowego - przy okazji moŋemy zobaczyæ w jakim towarzystwie przyjdzie nam pracowaæ :)
nasz_login:uŋytkownik_mail@domena_naszego_email:Imię i Nazwisko:user@jabber.domena
Ostatnie pole jest opcjonalne - wypeģniamy je tylko jeķli posiadamy swój wģasny JID (o ile go posiadamy). Jeķli z róŋnych przyczyn nie korzystamy z Jabbera - omijamy tę częķæ i zatrzymujemy się na imieniu i nazwisku. Dla zainteresowanych - istnieje oficjalny serwer Jabbera projektu PLD Linux - konta na nim zakģada Mariusz Mazur.
Edytujemy odpowiednio więc plik users (pamiętajmy, ŋeby zachowaæ alfabetyczną kolejnoķæ wpisów) - wystarczy tylko drobna znajomoķæ alfabetu i robimy nasz pierwszy commit - czyli potwierdzamy zmiany.
$ cvs ci CVSROOT/users // po tym poleceniu edytujemy log Checking in CVSROOT/users; /cvsroot/CVSROOT/users,v <-- users new revision: 1.40; previous revision: 1.39 done cvs server: Rebuilding administrative file database Mailing the commit message $ |
Po wydaniu polecenia cvs ci CVSROOT/users otworzy się nasz ulubiony edytor i pojawi się coķ podobnego do:
- added nasz_login // tu wpisujemy komentarz z kreseczką i po angielsku!!! CVS: --------------------------------------------------------------------- CVS: Enter Log. Lines beginning with `CVS:` are removed automatically CVS: CVS: Committing in . CVS: CVS: Updated Files: CVS: CVSROOT/users CVS: --------------------------------------------------------------------- |
Wģaķnie dokonaliķmy pierwszej zmiany w repozytorium PLD. Od tej chwili kaŋdy mail adresowany na <nasz_login>@pld-linux.org trafi na naszą skrzynkę pocztową.
Dalsza częķæ naszych rozwaŋaņ będzie juŋ w formie konkretnych przykģadów, poniewaŋ to co chcemy zrobiæ w repozytorium CVS PLD zaleŋy od konkretnych potrzeb. Od tej chwili nikt juŋ nas za rączkę nie będzie prowadziģ, a czekają nas pot, krew, ģzy i pierwsze "recenzje" naszych poczynaņ - np. na grupie PLD-devel czy kanale #PLD - a jedynymi nagrodami będzie brak tych recenzji, zdobyta wiedza, satysfakcja i dziaģające paczki, których przez chwilę nikt na ķwiecie nie będzie miaģ :)
Dodawanie plików do CVS PLD
Kaŋdy nowy plik, który chcemy umieķciæ w repozytorium naleŋy dodaæ za pomocą polecenia "cvs add"
$ cvs add nasz_nowy_pakiet.spec cvs server: scheduling file `nasz_nowy_pakiet.spec' for addition cvs server: use 'cvs commit' to add this file permanently $ |
Jak widaæ z komentarza, aby zakoņczyæ dodanie pliku naleŋy zatwierdziæ zmianę za pomocą polecenia "cvs ci" (polecenia podaję w formie skróconej) - Samo zatwierdzanie (commit) robiliķmy juŋ wczeķniej przy okazji pliku "users".
Aktualizacja plików
Pliki moŋemy zaktualizowaæ względem CVS - jeŋeli nasz plik jest nowszy nie zostanie dokonana ŋadna zmiana na naszym lokalnym repozytorium. Aktualizacją nie dokonujemy zmian na zdalnym repozytorium.
Jeŋeli w danym katalogu mamy juŋ zdefiniowaną kartotekę (czyli mamy juŋ odpowiedni podkatalog CVS) to aktualizacją moŋemy ķciągnąæ nowy plik.
$ cvs up python.spec P python.spec $ |
W powyŋszym przykģadzie dokonaliķmy aktualizacji pliku "python.spec". Literka "P" okreķla stan aktualizacji. Poniŋej przedstawię moŋlwe kody:
"A" - Plik dodany. Oznacza ŋe na pliku dokonano operacji "ADD" (czyli dodanie do repozytorium) ale nie wykonano commitu (zatwierdzenia)
"C" - Plik aktualizowany jest w konflikcie ze zdalnym repozytorium. Czyli np. dokonaliķmy zmian na lokalnym repozytorium i nasz plik jest "nowszy" względem zdalnego repozytorium.
"M" - Plik zostaģ zmodyfikowany w zdalnym repozytorium ale nie byģo ŋadnych konfliktów.
"P" - Plik byģ "ģatany" przez serwer (kod podobny do "U")
"R" - Plik usunięty ale nie zatwierdzony. Czyli dokonano operacji "cvs remove" ale nie zatwierdzono zmian (poleceniem "cvs ci")
"U" - Plik zostaģ zaktualizowany
"?" - Plik jest w naszym repozytorium lokalnym ale nie ma go w zdalnym repozytorium CVS
Zatwierdzanie zmian i Distfiles
Sam przykģad zatwierdzania zmian mogliķmy poznaæ wczeķniej. Jest to najczęķciej wykonywana operacja na CVS.
Jednak chciaģbym zwróciæ uwagę na inny sposób skģadowania žródeģ natywnych. W pewnym momencie okazuje się, ŋe skģadowanie wszystkich plików w repozytorium CVS jest maģo efektywne i powoduje zbyt duŋe obciąŋenia serwerów. Dlatego teŋ w PLD zastosowano mechanizm Distfiles którego krótki opis moŋemy odszukaæ tu. W wielkim skrócie oznacza to ŋe preparując odpowiednio spec (pamiętacie tajemnicze md5?) i korzystając z odpowiednich opcji programu ./builder moŋemy sterowaæ ķciąganiem plików do distfiles. Tak naprawdę najczęķciej wykorzystane są dwie opcje ./builder - "5" i "U". Jest to takŋe powód uŋywania programu ./builder (a nie frazy "rpmbuild -ba"), którego kopię najlepiej ķciągnąæ z CVS. Pamiętajmy takŋe o tym, ŋe w systemie istnieje inny builder, który jest dostarczany z narzędziami rpm ale oczywiķcie nie ma on moŋliwoķci pracy z distfiles. I jeszcze jedna uwaga: Distfiles jest przeznaczony tylko dla žródeģ natywnych - wszelkie patche i nasze pliki dodajemy normalnie do CVS (najczęķciej do katalogu SOURCES).
Oto przykģady uŋycia ./builder z odpowiednimi opcjami:
$ ./builder -5 mantis.spec # $Revision: 6218 $, $Date: 2004-09-26 17:31:14 +0200 (nie, 26 wrz 2004) $ --20:32:59-- http://dl.sourceforge.net/mantisbt/mantis-0.18.0a4.tar.gz => `mantis-0.18.0a4.tar.gz' Translacja dl.sourceforge.net... zrobiono. Ģączenie się z dl.sourceforge.net[193.1.219.87]:80... poģączono się. Ŋądanie HTTP wysģano, oczekiwanie na odpowiedž... 200 OK Dģugoķæ: 485,797 [application/x-tar] 100%[====================================>] 485,797 17.99K/s ETA 00:00 20:33:25 (17.99 KB/s) - zapisano `mantis-0.18.0a4.tar.gz' [485797/485797] Updating source-0 md5. $ |
Opcje "5" i "U" są podobne, z tym ŋe "5" próbuje poprawiæ md5 korzystając z istniejącego sources w lokalnym repozytorium. Natomiast "U" próbuje zawsze ķciągnąæ žródģa z podanego przez spec URL. Taka jest teoria. Ja praktycznie uŋywam opcji "U" kasując wczeķniej žródģa z lokalnego repozytorium, poniewaŋ w innym przypadku wyskakują dziwne bģędy o konflikcie z parametrem -nd
$ ./builder -U mantis.spec # $Revision: 6218 $, $Date: 2004-09-26 17:31:14 +0200 (nie, 26 wrz 2004) $ --20:44:39-- http://dl.sourceforge.net/mantisbt/mantis-0.18.0a4.tar.gz => `mantis-0.18.0a4.tar.gz' Translacja dl.sourceforge.net... zrobiono. Ģączenie się z dl.sourceforge.net[193.190.198.97]:80... poģączono się. Ŋądanie HTTP wysģano, oczekiwanie na odpowiedž... 200 OK Dģugoķæ: 485,797 [application/x-gzip] 100%[====================================>] 485,797 18.80K/s ETA 00:00 20:45:04 (18.80 KB/s) - zapisano `mantis-0.18.0a4.tar.gz' [485797/485797] Updating source-0 md5. $ |
Odnogi (Branche) i Etykiety (Tag)
W kaŋdym większym CVSie, projekty gģówne rozgaģęziają się tworząc tzw. branche - W przypadku PLD np. istnieje stabilny, lecz juŋ troche leciwy branch "RA-branch", który wywodzi się z brancha gģównego HEAD. W pewnym momencie RA-branch zostaģ "zamroŋony" i dokonywane są na nim tylko zmiany zawierające poprawki powaŋnych bģędów lub aktualizacje związane z bezpieczeņstwem. Branch HEAD "ŋyje" dalej i są w nim dokonywane zmiany i powstają nowe pakiety. Odgaģęzieņ moŋe byæ (i jest) wiele, co na początku troche gmatwa spojrzenie na CVS ale póžniej doceniamy zalety tego rozwiązania. Dane odnogi mają przydzielone odpowiednie etykiety "lepkie" (ang. sticky tag) - czyli etykieta jest przekazywana kaŋdej następnej wersji w danej odnodze. Zwykģe etykiety (ang. tag) moŋemy uŋyæ np. do okreslenia indywidualnego stanu danego pliku - okreķlając np. tag STABLE, UNSTABLE lub DEVELOP.
Jeŋeli chodzi o etykietowanie to trzeba zachowaæ rozwagę. Musimy byæ pewni ŋe wiemy co chcemy osiągnąæ, bo moŋemy popsuæ pracę komuķ innemu (dotyczy to takŋe zmian w cudzych specach).
Praktycznie najczęķciej wykorzystywane są następujące opcje związane z odnogami i etykietami:
$ cvs status -v mldonkey.spec // Statystyka odnóg i etykiet
===================================================================
File: mldonkey.spec Status: Up-to-date
Working revision: 1.14.2.8 // Rewizja (wersja) robocza na lokalnym CVS
Repository revision: 1.14.2.8 /cvsroot/SPECS/mldonkey.spec,v
// Rewizja na zdalnym CVS
Sticky Tag: RA-branch (branch: 1.14.2)
// Dane dotyczące lepkiej etykiety - związanej z branchem (odnogą)
Sticky Date: (none)
Sticky Options: (none)
Existing Tags: // Istniejące etykiety zwykģe
mldonkey-2_5_3-2 (revision: 1.14.2.7)
STABLE (revision: 1.14.2.7)
mldonkey-2_5-1 (revision: 1.14.2.2)
RA-branch (branch: 1.14.2)
$ |
Sam sposób robienia odnóg pozostawiam innym - lepiej poczytaæ np. opis CVS PLD bo sam tego jeszcze nie robiģem :). Etykietowanie moŋemy wykonaæ np.: mając plik w naszym lokalnym repozytorium wydajemy polecenie:
cvs tag UNSTABLE plik.spec
czyli plik.spec otrzymaģ etykietę UNSTABLE.
Ostatnim przykģadem będzie przenoszenie zmian między odnogami (branchami). Robiąc jakiķ spec w gģównej odnodze HEAD doszliķmy do wniosku, ŋe zmiany moŋna ogģosiæ w odnodze RA-branch. Moŋna spróbowaæ wykonaæ polecenie:
cvs update -r RA-branch -j HEAD mldonkey.init
ale najczęķciej róŋnice między wersjami w odnogach są tak duŋe, ŋe otrzymamy komunikat o braku automatycznej moŋliwoķci przeniesienia zmian. Wtedy moŋna rozwiązaæ ten problem innym sposobem. Tworzymy np. w podkatalogu "SPECS" katalog "RA-branch" (nazwa katalogu jest nieistotna, ale pomocna). W podkatalogu "RA-branch" wykonujemy:
$ cvs get -A SPECS/plik.spec // parametr "A" usuwa tag $ cd SPECS $ cvs tag -b RA-branch plik.spec // nowy tag dla odnogi RA-branch $ cp z_HEAD_plik.spec // podmieniamy plik na wģaķciwy z HEAD $ cvs commit -r RA-branch plik.spec // zatwierdzamy zmiany jako RA-branch $ |
Myķlę ŋe komentarze są czytelne. Gdy zrobimy co najmniej jedną taką operację, to istniejący katalog RA-branch moŋe nam sģuŋyæ do póžniejszych operacji kopiowania zmian między odnogami (np. korzystając z opcji "cvs up".
Zlecenia dla builderów
Zdarza się często, ŋe chcemy daæ sygnaģ iŋ dany pakiet powinien zostaæ przebudowany przez buildery PLD (czyli takie zdalne komputery-muģy robocze, które przygotowują pakiety) - wtedy podczas wpisywania komentarza po wydaniu polecenia "cvs ci" naleŋy napisaæ np.
- updated to version 2.5.3. Release 1 STBR for RA update general
STBR jest skrótem od "Send To Builder Request"
Zakoņczenie
Zbliŋamy się do koņca naszego praktycznego poradnika. Nie zostaģo poruszonych wiele kwestii, które wyjdą w codziennej pracy. Dlatego mamy do pomocy dokumentację, listy dyskusyjne, IRC, zasoby CVS i przeglądarkę GOOGLE ;). Praca ta miaģa na celu wprowadziæ w ķwiat pracy developerskiej i pokazaæ praktyczne rozwiązania niektórych problemów - reszta zaleŋy od naszej wiedzy i pracowitoķci - i pamiętajmy, ŋe najwaŋniejsze to rozwijaæ swoje zdolnoķci, bo od tego zaleŋy nasza przyszģoķæ i przyszģoķæ projektu dla którego pracujemy :)
VI. O podręczniku
- Spis treści
- O podręczniku
- Licencja i prawa autorskie
O podręczniku
Autorzy dokumentacji PLD
W tworzeniu tej pracy poķrednio lub bezpoķrednio udziaģ wzieli (w kolejnoķci alfabetycznej):
Abramowicz Michaģ (abram)
Boguszewski Paweģ (pawelb)
<pawelb.at.pld-linux.org>Buziak Tomasz (uho)
<uho.at.xhost.one.pl>Chomicki Arkadiusz (ChomAr)
<chomar.at.wla.pl>Ciesielski Marek (ciesiel)
<ciesiel.at.pld-linux.org>Doliņski Marcin
<averne.at.pld-linux.org>Drozd Rafaģ (Grifter)
Gandecki Ģukasz (gozda)
<gozda.at.pld-linux.org>Goģębiowski Adam (adamg)
<adamg.at.pld-linux.org>Krakowiak Paweģ
Królikowski Krzysztof
<krolik.at.pld-linux.org>Kwiatkowski Paweģ (qwiat)
<qwiat.at.o2.pl>Mozer Ģukasz Jarosģaw (Baseciq)
Nowak Ģukasz (Shufla)
<Lukasz.at.Nowak.eu.org>Panasiewicz Michaģ (wolvverine)
<wolvverine.at.pld-linux.org>Paszkiewicz Sģawomir (PaSzCzUs)
<paszczus.at.pld-linux.org>Pawģowicz Sergiusz (Ser)
Poķlad Marcin (Lop)
Rudnicki Daniel Dominik (sardzent)
<sardzent.at.pld-linux.org>Sikora Paweģ
<pluto.at.pld-linux.org>Szafko Bartģomiej
Wojtaszek Marek (speedo)
<speedo.at.linux.pl>
Licencja i prawa autorskie
Tģumaczenie Licencji GNU Wolnej Dokumentacji
Niniejsza dokumentacja jest wydawana na licencji GNU Wolnej Dokumentacji. Oryginalny tekst licencji wersji 1.2 w języku angielskim moŋemy odnaležæ na stronie GNU Free Documentation License. Tģumaczenie starszej wersji 1.1 zostanie tutaj przytoczone i znajduje się na stronie GNU.org.pl. Róŋnice między wersją 1.1 a 1.2 niniejszej licencji w wersji angielskiej moŋemy przeczytaæ korzystając z tego odnoķnika
Wersja 1.1, marzec 2000
Copyright (c) 2000 Free Software Foundation, Inc. 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA Zezwala się na kopiowanie i rozpowszechnianie wiernych kopii niniejszego dokumentu licencyjnego, jednak bez prawa wprowadzania zmian.
0. Preambuģa
Celem niniejszej licencji jest zagwarantowanie wolnego dostępu do podręcznika, treķci ksiąŋki i wszelkiej dokumentacji w formie pisanej oraz zapewnienie kaŋdemu uŋytkownikowi swobody kopiowania i rozpowszechniania wyŋej wymienionych, z dokonywaniem modyfikacji lub bez, zarówno w celach komercyjnych, jak i nie komercyjnych. Ponad to Licencja ta pozwala przyznaæ zasģugi autorowi i wydawcy przy jednoczesnym ich zwolnieniu z odpowiedzialnoķci za modyfikacje dokonywane przez innych.
Niniejsza Licencja zastrzega teŋ, ŋe wszelkie prace powstaģe na podstawie tego dokumentu muszą nosiæ cechę wolnego dostępu w tym samym sensie co produkt oryginalny. Licencja stanowi uzupeģnienie Powszechnej Licencji Publicznej GNU (GNU General Public License), która jest licencją dotyczącą wolnego oprogramowania.
Niniejsza Licencja zostaģa opracowana z zamiarem zastosowania jej do podręczników do wolnego oprogramowania, poniewaŋ wolne oprogramowanie wymaga wolnej dokumentacji: wolny program powinien byæ rozpowszechniany z podręcznikami, których dotyczą te same prawa, które wiąŋą się z oprogramowaniem. Licencja ta nie ogranicza się jednak do podręczników oprogramowania. Moŋna ją stosowaæ do róŋnych dokumentów tekstowych, bez względu na ich przedmiot oraz niezaleŋnie od tego, czy zostaģy opublikowane w postaci ksiąŋki drukowanej. Stosowanie tej Licencji zalecane jest gģównie w przypadku prac, których celem jest instruktaŋ lub pomoc podręczna.
1. Zastosowanie i definicje
Niniejsza Licencja stosuje się do podręczników i innych prac, na których umieszczona jest pochodząca od wģaķciciela praw autorskich informacja, ŋe dana praca moŋe byæ rozpowszechniana wyģącznie na warunkach niniejszej Licencji. Uŋywane poniŋej sģowo "Dokument" odnosiæ się będzie do wszelkich tego typu publikacji. Ich odbiorcy nazywani będą licencjobiorcami.
"Zmodyfikowana wersja" Dokumentu oznacza wszelkie prace zawierające Dokument lub jego częķæ w postaci dosģownej bądž zmodyfikowanej i/lub przeģoŋonej na inny język.
"Sekcją drugorzędną" nazywa się dodatek opatrzony odrębnym tytuģem lub sekcję początkową Dokumentu, która dotyczy wyģącznie związku wydawców lub autorów Dokumentu z ogólną tematyką Dokumentu (lub zagadnieniami z nią związanymi) i nie zawiera ŋadnych treķci bezpoķrednio związanych z ogólną tematyką (na przykģad, jeŋeli Dokument stanowi w częķci podręcznik matematyki, Sekcja drugorzędna nie moŋe wyjaķniaæ zagadnieņ matematycznych). Wyŋej wyjaķniany związek moŋe się natomiast wyraŋaæ w aspektach historycznym, prawnym, komercyjnym, filozoficznym, etycznym lub politycznym.
"Sekcje niezmienne" to takie Sekcje drugorzędne, których tytuģy są ustalone jako tytuģy Sekcji niezmiennych w nocie informującej, ŋe Dokument zostaģ opublikowany na warunkach Licencji.
"Treķæ okģadki" to pewne krótkie fragmenty tekstu, które w nocie informującej, ŋe Dokument zostaģ opublikowany na warunkach Licencji, są opisywane jako "do umieszczenia na przedniej okģadce" lub "do umieszczenia na tylnej okģadce".
"Jawna" kopia Dokumentu oznacza kopię czytelną dla komputera, zapisaną w formacie, którego specyfikacja jest publicznie dostępna. Zawartoķæ tej kopii moŋe byæ oglądana i edytowana bezpoķrednio za pomocą typowego edytora tekstu lub (w przypadku obrazów zģoŋonych z pikseli) za pomocą typowego programu graficznego lub (w przypadku rysunków) za pomocą ogólnie dostępnego edytora rysunków. Ponadto kopia ta stanowi odpowiednie dane wejķciowe dla programów formatujących tekst lub dla programów konwertujących do róŋnych formatów odpowiednich dla programów formatujących tekst. Kopia speģniająca powyŋsze warunki, w której jednak zostaģy wstawione znaczniki mające na celu utrudnienie dalszych modyfikacji przez czytelników, nie jest Jawna. Kopię, która nie jest "Jawna", nazywa się "Niejawną".
Przykģadowe formaty kopii Jawnych to: czysty tekst ASCII bez znaczników, format wejķciowy Texinfo, format wejķciowy LaTeX, SGML lub XML wykorzystujące publicznie dostępne DTD, standardowy prosty HTML przeznaczony do ręcznej modyfikacji. Formaty niejawne to na przykģad PostScript, PDF, formaty wģasne, które mogą byæ odczytywane i edytowane jedynie przez wģasne edytory tekstu, SGML lub XML, dla których DTD i/lub narzędzia przetwarzające nie są ogólnie dostępne, oraz HTML wygenerowany maszynowo przez niektóre procesory tekstu jedynie w celu uzyskania danych wynikowych.
"Strona tytuģowa" oznacza, w przypadku ksiąŋki drukowanej, samą stronę tytuģową oraz kolejne strony zawierające informacje, które zgodnie z tą Licencją muszą pojawiæ się na stronie tytuģowej. W przypadku prac w formatach nieposiadających strony tytuģowej "Strona tytuģowa" oznacza tekst pojawiający się najbliŋej tytuģu pracy, poprzedzający początek tekstu gģównego.
2. Kopiowanie dosģowne
Licencjobiorca moŋe kopiowaæ i rozprowadzaæ Dokument komercyjnie lub niekomercyjnie, w dowolnej postaci, pod warunkiem zamieszczenia na kaŋdej kopii Dokumentu treķci Licencji, informacji o prawie autorskim oraz noty mówiącej, ŋe do Dokumentu ma zastosowanie niniejsza Licencja, a takŋe pod warunkiem nie umieszczania ŋadnych dodatkowych ograniczeņ, które nie wynikają z Licencji. Licencjobiorca nie ma prawa uŋywaæ ŋadnych technicznych metod pomiarowych utrudniających lub kontrolujących czytanie lub dalsze kopiowanie utworzonych i rozpowszechnianych przez siebie kopii. Moŋe jednak pobieraæ opģaty za udostępnianie kopii. W przypadku dystrybucji duŋej liczby kopii Licencjobiorca jest zobowiązany przestrzegaæ warunków wymienionych w punkcie 3.
Licencjobiorca moŋe takŋe wypoŋyczaæ kopie na warunkach opisanych powyŋej, a takŋe wystawiaæ je publicznie.
3. Kopiowanie iloķciowe
Jeŋeli Licencjobiorca publikuje drukowane kopie Dokumentu w liczbie większej niŋ 100, a licencja Dokumentu wymaga umieszczenia Treķci okģadki, naleŋy doģączyæ kopie okģadek, które zawierają caģą wyražną i czytelną Treķæ okģadki: treķæ przedniej okģadki, na przedniej okģadce, a treķæ tylnej okģadki, na tylnej okģadce. Obie okģadki muszą teŋ jasno i czytelnie informowaæ o Licencjobiorcy jako wydawcy tych kopii. Okģadka przednia musi przedstawiaæ peģny tytuģ; wszystkie sģowa muszą byæ równie dobrze widoczne i czytelne. Licencjobiorca moŋe na okģadkach umieszczaæ takŋe inne informacje dodatkowe. Kopiowanie ze zmianami ograniczonymi do okģadek, dopóki nie narusza tytuģu Dokumentu i speģnia opisane warunki, moŋe byæ traktowane pod innymi względami jako kopiowanie dosģowne.
Jeŋeli napisy wymagane na którejķ z okģadek są zbyt obszerne, by mogģy pozostaæ czytelne po ich umieszczeniu, Licencjobiorca powinien umieķciæ ich początek(taką iloķæ, jaka wydaje się rozsądna) na rzeczywistej okģadce, a pozostaģą częķæ na sąsiednich stronach.
W przypadku publikowania lub rozpowszechniania Niejawnych kopii Dokumentu w liczbie większej niŋ 100, Licencjobiorca zobowiązany jest albo doģączyæ do kaŋdej z nich Jawną kopię czytelną dla komputera, albo wymieniæ w lub przy kaŋdej kopii Niejawnej publicznie dostępną w sieci komputerowej lokalizację peģnej kopii Jawnej Dokumentu, bez ŋadnych informacji dodanych -- lokalizację, do której kaŋdy uŋytkownik sieci miaģby bezpģatny anonimowy dostęp za pomocą standardowych publicznych protokoģów sieciowych. W przypadku drugim Licencjobiorca musi podjąæ odpowiednie ķrodki ostroŋnoķci, by wymieniona kopia Jawna pozostaģa dostępna we wskazanej lokalizacji przynajmniej przez rok od momentu rozpowszechnienia ostatniej kopii Niejawnej (bezpoķredniego lub przez agentów albo sprzedawców) danego wydania.
Zaleca się, choæ nie wymaga, aby przed rozpoczęciem rozpowszechniania duŋej liczby kopii Dokumentu, Licencjobiorca skontaktowaģ się z jego autorami celem uzyskania uaktualnionej wersji Dokumentu.
4. Modyfikacje
Licencjobiorca moŋe kopiowaæ i rozpowszechniaæ Zmodyfikowaną wersję Dokumentu na zasadach wymienionych powyŋej w punkcie 2 i 3 pod warunkiem ķcisģego przestrzegania niniejszej Licencji. Zmodyfikowana wersja peģni wtedy rolę Dokumentu, a więc Licencja dotycząca modyfikacji i rozpowszechniania Zmodyfikowanej wersji przenoszona jest na kaŋdego, kto posiada jej kopię. Ponadto Licencjobiorca musi w stosunku do Zmodyfikowanej wersji speģniæ następujące wymogi:
A. Uŋyæ na Stronie tytuģowej (i na okģadkach, o ile istnieją) tytuģu innego niŋ tytuģ Dokumentu i innego niŋ tytuģy poprzednich wersji (które, o ile istniaģy, powinny zostaæ wymienione w Dokumencie, w sekcji Historia). Tytuģu jednej z ostatnich wersji Licencjobiorca moŋe uŋyæ, jeŋeli jej wydawca wyrazi na to zgodę.
B. Wymieniæ na Stronie tytuģowej, jako autorów, jedną lub kilka osób albo jednostek odpowiedzialnych za autorstwo modyfikacji Zmodyfikowanej wersji, a takŋe przynajmniej pięciu spoķród pierwotnych autorów Dokumentu (wszystkich, jeķli byģo ich mniej niŋ pięciu).
C. Umieķciæ na Stronie tytuģowej nazwę wydawcy Zmodyfikowanej wersji.
D. Zachowaæ wszelkie noty o prawach autorskich zawarte w Dokumencie.
E. Dodaæ odpowiednią notę o prawach autorskich dotyczących modyfikacji obok innych not o prawach autorskich.
F. Bezpoķrednio po notach o prawach autorskich, zamieķciæ notę licencyjną zezwalającą na publiczne uŋytkowanie Zmodyfikowanej wersji na zasadach niniejszej Licencji w postaci podanej w Zaģączniku poniŋej.
G. Zachowaæ w nocie licencyjnej peģną listę Sekcji niezmiennych i wymaganych Treķci okģadki podanych w nocie licencyjnej Dokumentu.
H. Doģączyæ niezmienioną kopię niniejszej Licencji.
I. Zachowaæ sekcję zatytuģowaną "Historia" oraz jej tytuģ i dodaæ do niej informację dotyczącą przynajmniej tytuģu, roku publikacji, nowych autorów i wydawcy Zmodyfikowanej wersji zgodnie z danymi zamieszczonymi na Stronie tytuģowej. Jeŋeli w Dokumencie nie istnieje sekcja pod tytuģem "Historia", naleŋy ją utworzyæ, podając tytuģ, rok, autorów i wydawcę Dokumentu zgodnie z danymi zamieszczonymi na stronie tytuģowej, a następnie dodając informację dotyczącą Zmodyfikowanej wersji, jak opisano w poprzednim zdaniu.
J. Zachowaæ wymienioną w Dokumencie (jeķli taka istniaģa) informację o lokalizacji sieciowej, publicznie dostępnej Jawnej kopii Dokumentu, a takŋe o podanych w Dokumencie lokalizacjach sieciowych poprzednich wersji, na których zostaģ on oparty. Informacje te mogą się znajdowaæ w sekcji "Historia". Zezwala się na pominięcie lokalizacji sieciowej prac, które zostaģy wydane przynajmniej cztery lata przed samym Dokumentem, a takŋe tych, których pierwotny wydawca wyraŋa na to zgodę.
K. W kaŋdej sekcji zatytuģowanej "Podziękowania" lub "Dedykacje" zachowaæ tytuģ i treķæ, oddając równieŋ ton kaŋdego z podziękowaņ i dedykacji.
L. Zachowaæ wszelkie Sekcje niezmienne Dokumentu w niezmienionej postaci (dotyczy zarówno treķci, jak i tytuģu). Numery sekcji i równowaŋne im oznaczenia nie są traktowane jako naleŋące do tytuģów sekcji.
M. Usunąæ wszelkie sekcje zatytuģowane "Adnotacje". Nie muszą one byæ zaģączane w Zmodyfikowanej wersji.
N. Nie nadawaæ ŋadnej z istniejących sekcji tytuģu "Adnotacje" ani tytuģu pokrywającego się z jakąkolwiek Sekcją niezmienną.
Jeŋeli Zmodyfikowana wersja zawiera nowe sekcje początkowe lub dodatki stanowiące Sekcje drugorzędne i nie zawierające materiaģu skopiowanego z Dokumentu, Licencjobiorca moŋe je lub ich częķæ oznaczyæ jako sekcje niezmienne. W tym celu musi on dodaæ ich tytuģy do listy Sekcji niezmiennych zawartej w nocie licencyjnej Zmodyfikowanej wersji. Tytuģy te muszą byæ róŋne od tytuģów pozostaģych sekcji.
Licencjobiorca moŋe dodaæ sekcję "Adnotacje", pod warunkiem, ŋe nie zawiera ona ŋadnych treķci innych niŋ adnotacje dotyczące Zmodyfikowanej wersji -- mogą to byæ na przykģad stwierdzenia o recenzji koleŋeņskiej albo o akceptacji tekstu przez organizację jako autorytatywnej definicji standardu.
Na koņcu listy Treķci okģadki w Zmodyfikowanej wersji, Licencjobiorca moŋe dodaæ fragment "do umieszczenia na przedniej okģadce" o dģugoķci nie przekraczającej pięciu sģów, a takŋe fragment o dģugoķci do 25 sģów "do umieszczenia na tylnej okģadce". Przez kaŋdą jednostkę (lub na mocy ustaleņ przez nią poczynionych) moŋe zostaæ dodany tylko jeden fragment z przeznaczeniem na przednią okģadkę i jeden z przeznaczeniem na tylną. Jeŋeli Dokument zawiera juŋ treķæ okģadki dla danej okģadki, dodaną uprzednio przez Licencjobiorcę lub w ramach ustaleņ z jednostką, w imieniu której dziaģa Licencjobiorca, nowa treķæ okģadki nie moŋe zostaæ dodana. Dopuszcza się jednak zastąpienie poprzedniej treķci okģadki nową pod warunkiem wyražnej zgody poprzedniego wydawcy, od którego stara treķæ pochodzi.
Niniejsza Licencja nie oznacza, iŋ autor (autorzy) i wydawca (wydawcy) wyraŋają zgodę na publiczne uŋywanie ich nazwisk w celu zapewnienia autorytetu jakiejkolwiek Zmodyfikowanej wersji.
5. Ģączenie dokumentów
Licencjobiorca moŋe ģączyæ Dokument z innymi dokumentami wydanymi na warunkach niniejszej Licencji, na warunkach podanych dla wersji zmodyfikowanych w częķci 4 powyŋej, jednak tylko wtedy, gdy w poģączeniu zostaną zawarte wszystkie Sekcje niezmienne wszystkich oryginalnych dokumentów w postaci niezmodyfikowanej i gdy będą one wymienione jako Sekcje niezmienne poģączenia w jego nocie licencyjnej.
Poģączenie wymaga tylko jednej kopii niniejszej Licencji, a kilka identycznych Sekcji niezmiennych moŋe zostaæ zastąpionych jedną. Jeŋeli istnieje kilka Sekcji niezmiennych o tym samym tytule, ale róŋnej zawartoķci, Licencjobiorca jest zobowiązany uczyniæ tytuģ kaŋdej z nich unikalnym poprzez dodanie na jego koņcu, w nawiasach, nazwy oryginalnego autora lub wydawcy danej sekcji, o ile jest znany, lub unikalnego numeru. Podobne poprawki wymagane są w tytuģach sekcji na liķcie Sekcji niezmiennych w nocie licencyjnej poģączenia.
W poģączeniu Licencjobiorca musi zawrzeæ wszystkie sekcje zatytuģowane "Historia" z dokumentów oryginalnych, tworząc jedną sekcję "Historia". Podobnie ma postąpiæ z sekcjami "Podziękowania" i "Dedykacje". Wszystkie sekcje zatytuģowane "Adnotacje" naleŋy usunąæ.
6. Zbiory dokumentów
Licencjobiorca moŋe utworzyæ zbiór skģadający się z Dokumentu i innych dokumentów wydanych zgodnie z niniejszą Licencją i zastąpiæ poszczególne kopie Licencji pochodzące z tych dokumentów jedną kopią doģączoną do zbioru, pod warunkiem zachowania zasad Licencji dotyczących kopii dosģownych we wszelkich innych aspektach kaŋdego z dokumentów.
Z takiego zbioru Licencjobiorca moŋe wyodrębniæ pojedynczy dokument i rozpowszechniaæ go niezaleŋnie na zasadach niniejszej Licencji, pod warunkiem zamieszczenia w wyodrębnionym dokumencie kopii niniejszej Licencji oraz zachowania zasad Licencji we wszystkich aspektach dotyczących dosģownej kopii tego dokumentu.
7. Zestawienia z pracami niezaleŋnymi
Kompilacja Dokumentu lub jego pochodnych z innymi oddzielnymi i niezaleŋnymi dokumentami lub pracami nie jest uznawana za Zmodyfikowaną wersję Dokumentu, chyba ŋe odnoszą się do niej jako do caģoķci prawa autorskie. Taka kompilacja jest nazywana zestawieniem, a niniejsza Licencja nie dotyczy samodzielnych prac skompilowanych z Dokumentem, jeķli nie są to pochodne Dokumentu.
Jeŋeli do kopii Dokumentu odnoszą się wymagania dotyczące Treķci okģadki wymienione w częķci 3 i jeŋeli Dokument stanowi mniej niŋ jedną czwartą caģoķci zestawienia, Treķæ okģadki Dokumentu moŋe byæ umieszczona na okģadkach zamykających Dokument w obrębie zestawienia. W przeciwnym razie Treķæ okģadki musi się pojawiæ na okģadkach caģego zestawienia.
8. Tģumaczenie
Tģumaczenie jest uznawane za rodzaj modyfikacji, a więc Licencjobiorca moŋe rozpowszechniaæ tģumaczenia Dokumentu na zasadach wymienionych w punkcie 4. Zastąpienie Sekcji niezmiennych ich tģumaczeniem wymaga specjalnej zgody wģaķcicieli prawa autorskiego. Dopuszcza się jednak zamieszczanie tģumaczeņ wybranych lub wszystkich Sekcji niezmiennych obok ich wersji oryginalnych. Podanie tģumaczenia niniejszej Licencji moŋliwe jest pod warunkiem zamieszczenia takŋe jej oryginalnej wersji angielskiej. W przypadku niezgodnoķci pomiędzy zamieszczonym tģumaczeniem a oryginalną wersją angielską niniejszej Licencji moc prawną ma oryginalna wersja angielska.
9. Wygaķnięcie
Poza przypadkami jednoznacznie dopuszczonymi na warunkach niniejszej Licencji nie zezwala się Licencjobiorcy na kopiowanie, modyfikowanie, czy rozpowszechnianie Dokumentu ani teŋ na cedowanie praw licencyjnych. We wszystkich pozostaģych wypadkach kaŋda próba kopiowania, modyfikowania lub rozpowszechniania Dokumentu albo cedowania praw licencyjnych jest niewaŋna i powoduje automatyczne wygaķnięcie praw, które licencjobiorca nabyģ z tytuģu Licencji. Niemniej jednak w odniesieniu do stron, które juŋ otrzymaģy od Licencjobiorcy kopie albo prawa w ramach niniejszej Licencji, licencje nie zostaną anulowane, dopóki strony te w peģni się do nich stosują.
10. Przyszģe wersje Licencji
W miarę potrzeby Free Software Foundation moŋe publikowaæ nowe poprawione wersje GNU Free Documenation License. Wersje te muszą pozostawaæ w duchu podobnym do wersji obecnej, choæ mogą się róŋniæ w szczegóģach dotyczących nowych problemów czy zagadnieņ. Patrz http://www.gnu.org/copyleft/. Kaŋdej wersji niniejszej Licencji nadaje się wyróŋniający ją numer. Jeŋeli w Dokumencie podaje się numer wersji Licencji, oznaczający, iŋ odnosi się do niego podana "lub jakakolwiek póžniejsza" wersja licencji, Licencjobiorca ma do wyboru stosowaæ się do postanowieņ i warunków albo tej wersji, albo którejkolwiek wersji póžniejszej opublikowanej oficjalnie (nie jako propozycja) przez Free Software Foundation. Jeķli Dokument nie podaje numeru wersji niniejszej Licencji, Licencjobiorca moŋe wybraæ dowolną wersję kiedykolwiek opublikowaną (nie jako propozycja) przez Free Software Foundation.
Zaģącznik: Jak zastosowaæ tę Licencję dla swojego dokumentu.
Aby zastosowaæ tę Licencję w stosunku do dokumentu swojego autorstwa, doģącz kopię Licencji do dokumentu i zamieķæ następującą informację o prawach autorskich i uwagi o licencji bezpoķrednio po stronie tytuģowej.
Copyright (c) ROK TWOJE IMIE I NAZWISKO Udziela się zezwolenia do kopiowania rozpowszechniania i/lub modyfikację tego dokumentu zgodnie z zasadami Licencji GNU Wolnej Dokumentacji w wersji 1.1 lub dowolnej póžniejszej opublikowanej przez Free Software Foundation; wraz z zawartymi Sekcjami Niezmiennymi LISTA TYTUĢÓW SEKCJI, wraz z Tekstem na Przedniej Okģadce LISTA i z Tekstem na Tylnej Okģadce LISTA. Kopia licencji zaģączona jest w sekcji zatytuģowanej "GNU Free Documentation License"
Jeķli nie zamieszczasz Sekcji Niezmiennych, napisz "nie zawiera Sekcji Niezmiennych" zamiast spisu sekcji niezmiennych. Jeķli nie umieszczasz Teksu na Przedniej Okģadce wpisz "bez Tekstu na Okģadce" w miejsce "wraz z Tekstem na Przedniej Okģadce LISTA", analogicznie postąp z "Tekstem na Tylnej Okģadce"
Jeķli w twoim dokumencie zawarte są nieszablonowe przykģady kodu programu, zalecamy abyķ takŋe uwolniģ te przykģady wybierając licencję wolnego oprogramowania, taką jak Powszechna Licencja Publiczna GNU, w celu zapewnienia moŋliwoķci ich uŋycia w wolnym oprogramowaniu.