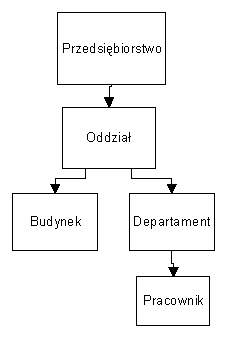
Hierarchiczna struktura danych
Języki obsługi
- o charakterze nawigacyjnym
- operacje typu:
- GET LEFTMOST typ WHERE warunek
- GET NEXT typ
Ograniczenia
- nie ma związków typu n-m (np. oddziały pomieszane w kilku budynkach)
- tylko jeden rodzaj związku między dwoma typami obiektów
- dodatkowe związki
(np. pracownik-budynek):- dodatkowe drzewa hierarchii
- odsyłacze do rekordów "oryginału"
Znaczenie praktyczne
- system IBM IMS (1978)
- bardzo wielkie dane zgromadzone
- poprzednik użyty w programie Apollo
- nowych projektów nie robi się
Model sieciowy
Cechy podstawowe
- struktura danych ma postać grafu (sieci)
- wierzchołki grafu -- typy obiektów
- łuki w grafie -- wiązania między typami
- opis obiektu (rekord) zbudowany z pól zawierających dane opisujące obiekt
- reprezentacja wiązań (wskaźniki):
- odesłanie bezpośrednie (jednowart.)
- odesłanie inwersyjne (wielowart.)
- wiązanie codasylowe
Realizacja wiązań -- model DBTG CODASYL
- rekordy powiązane stanowią kolekcję (set)
- jeden rekord nadrzędny
- wiele rekordów podrzędnych
- kolekcja realizowana jako lista zamknięta
- brak bezpośredniej reprezentacji
wiązań n-m
Języki obsługi
- języki manipulowania -- nawigacyjne
- CODASYL: język definiowania danych pozwala określić sposób automatycznego włączania rekordów do kolekcji
Przykłady
Więzy i ich realizacja w CODASYL
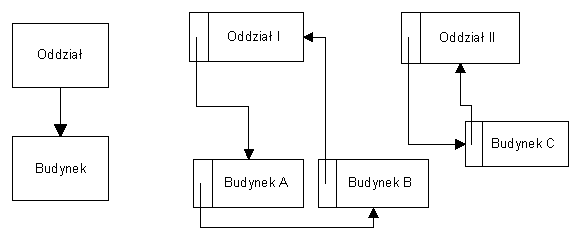
Sposób realizacji wiązania m-n
Znaczenie praktyczne
- system IDS (General Electric)
- obecnie raczej nie używany
Model relacyjny
Cechy podstawowe
- dane zawarte w tabelach
- tabele składają się z kolumn
- liczba kolumn i typy -- stałe
- liczba wierszy zmienna
- wiersze nie mają tożsamości innej niż wynikająca z zawartości kolumn
- związki pomiędzy wierszami tabel -- zdefiniowane poprzez zależności między wartościami wybranych kolumn, tzw. kluczy (nie ma wskaźników)
- z punktu widzenia teorii model można opisać algebrą relacji między zbiorami atrybutów
Języki obsługi
- nieproceduralne: SQL, Sequel, QUEL, QBE
- proceduralne: xBase
Znaczenie praktyczne
- model dominujący w zastosowaniach komercyjnych
- przykłady SZBD: Oracle, Informix, Sybase, Ingres, DB2, Progress, Gupta, Access, dBase, Paradox
Przykład
Przykładowy schemat danych -- związek 1-n
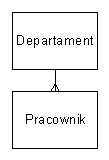
# Id * Nazwa * Id departamentu oddziału ... ... ...
# Id * Nazwisko * o Stanowisko * Id pracownika Imię departamentu ... ... ... ... ...Realizacja relacyjna
Ograniczenia
- brak bezpośredniej reprezentacji
związków n-m - dla trudniejszych problemów
-- bardzo wiele tabel - mało naturalna reprezentacja danych
- ograniczona podatność na zmiany
- trudne operowanie na złożonych obiektach -- dane rozproszone w wielu tabelach
- brak złożonych typów danych
- model mało wygodny dla zastosowań
CAD, GIS itp.
Model obiektowy (object-oriented)
Cechy podstawowe
- obiekt w bazie reprezentuje obiekt w świecie zewnętrznym
- typ obiektowy (klasa):
- definicja złożonego typu danych (może zawierać inne typy obiektowe lub ich kolekcje)
- procedury (metody) i operatory do manipulowania tymi danymi
- tożsamość obiektu jest niezależna od zawartości danych
- dziedziczenie (inheritance):
- strukturalne: potomek dziedziczy strukturę danych
- behawioralne: potomek dziedziczy metody i operatory
Cechy dodatkowe
- enkapsulacja: wnętrze obiektu dostępne jedynie w sposób w nim zdefiniowany
- polimorfizm: tak samo nazwane metody i operatory działają swoiście w zależności od klasy obiektu
Przykład
Model obiektowy -- zawieranie i dziedziczenie
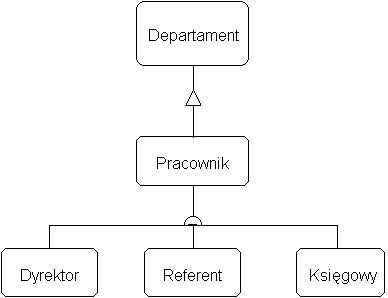
Zalety modelu
- dość naturalna reprezentacja świata
- łatwość działania na złożonych obiektach
- duża podatność na zmiany
Znaczenie praktyczne
- w zastosowaniach naukowych lub eksperymentalnych
- przykłady systemów: GemStone, O2
- przewidywana ewolucja baz relacyjnych w kierunku obiektowo-relacyjnych
Relacyjne bazy danych
Literatura
C. Delobel, M Adiba: Relacyjne bazy danych. WNT, Warszawa 1989. M. Muraszkiewicz, H. Rybiński: Bazy danych. AOW, 1993. W. Harris: Bazy danych nie tylko dla ludzi biznesu. WNT, 1994. K. Subieta: Ingres. AOW PLJ, 1994. Wellesley Software: SQL. Język relacyjnych baz danych. WNT. M. Gruber: SQL. Helion, 1996. Ulka Rodgers: Oracle. Przewodnik projektanta baz danych. WNT, 1995. J. Gnybek: Oracle łatwiejszy niż przypuszczasz. Helion, 1996. R. Barker: CASE*Method. Modelowanie związków encji. WNT, 1996.
Podstawy teoretyczne modelu relacyjnego
Pojęcie relacji
- rozważamy model pojęciowy
- cechy rzeczywistości opisane są w atrybutach
- schemat relacji to zbiór nazw atrybutów:
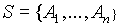
- wartości atrybutów należą do dziedzin:
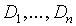
- relacja na schemacie S to podzbiór iloczynu kartezjańskiego
dziedzin atrybutów:
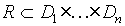
- relacja jest zbiorem krotek:
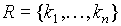
- zbiór krotek może być reprezentowany jako tabela:
- kolumny odpowiadają nazwom atrybutów
- wiersze odpowiadają krotkom
Relacyjna baza danych
- schemat relacyjnej bazy danych jest zbiorem schematów relacji
- relacyjna baza danych jest zbiorem relacji spełniających warunki integralności dla każdej relacji i między relacjami
Klucze
- klucz relacji K = zbiór atrybutów, które jednoznacznie wyznaczają
krotkę:
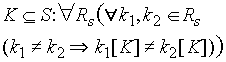
gdzie ki[K] oznacza podkrotkę zawierającą tylko atrybuty z klucza K - klasyfikacja kluczy:
- klucze właściwe: żaden podzbiór właściwy klucza właściwego nie jest kluczem
- klucz główny: jeden z kluczy właściwych relacji, wybrany do identyfikowania krotek
- klucze wykrywa się analizując opisywany świat, a nie dostępne dane!
- przykład:
- id pracownika jest kluczem
- nazwisko nie jest kluczem
- nazwisko + imię + data urodzenia + imię ojca -- jest kluczem
Operacje na relacjach
Selekcja
- selekcja = wybór krotek (wierszy):
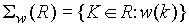
gdzie w jest warunkiem selekcji - selekcja jest komutatywna:
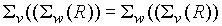
Projekcja (rzut)
- projekcja = wybór atrybutów (kolumn):
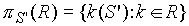
- gdzie S' jest podzbiorem schematu S
- projekcja jest wzajemnie komutatywna z selekcją:
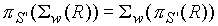
o ile warunek selekcji ma sens po projekcji, tj. dotyczy tylko atrybutów wybranych w projekcji
Operacje teoriomnogościowe
- dotyczą relacji opartych na identycznych schematach:
- suma
- iloczyn
- różnica
Złączenie
- operacja na dwóch relacjach -- podzbiór iloczynu kartezjańskiego dwóch
relacji:
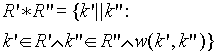
gdzie w jest warunkiem złączenia - krotki złączenia stanowią sklejenie (konkatenację) krotek relacji złączanych
- rodzaje złączeń:
- równościowe -- warunek równościowy
- naturalne -- równościowe i nazwy atrybutów zgodne
Rachunki relacji
- algebra relacji -- oparta na w/w operacjach
- rachunek predykatów -- określa się schemat relacji wynikowej i
kwalifikatory (predykaty) określające warunki
- rachunek krotek
- rachunek dziedzin
- algebra relacji prowadzi do języków proceduralnych
- rachunek predykatów prowadzi do języków deklaratywnych
Zależności semantyczne w relacyjnej bazie danych
Ograniczenia integralności
- świat rzeczywisty opisują tylko te z możliwych relacji, które spełniają zależności semantyczne istniejące w modelowanym świecie
- zależności w b.d. modeluje się jako tzw. ograniczenia integralności (integrity constraints)
- zależności semantyczne wykrywa się analizując opisywany świat, a nie dostępne dane!
Rodzaje zależności
- ograniczenia dotyczące atrybutu
- obowiązkowość
- ograniczenia wartości
- ograniczenia dotyczące jednej relacji
- funkcyjne (functional dependency)
- wielowartościowe (multivalued )
- zależności między relacjami
- referencyjne -- zgodność wartości wybranych atrybutów
Zależności funkcyjne
- zbiór atrybutów Y jest zależny funkcyjnie od zbioru X gdy z
każdą konfiguracją wartości atrybutów z X jest związana co najwyżej
jedna konfiguracja wartości z Y:
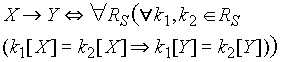
- przykład:
- imię zależy funkcyjnie od id pracownika
- id nie zależy funkcyjnie od imienia
- imię nie zależy funkcyjnie od nazwiska
- aksjomaty Armstronga -- pozwalają znaleźć nowe zależności funkcyjne na
podst. już znalezionych:
-
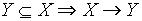 -- zwrotność
-- zwrotność
-
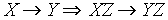 -- rozszerzenie
-- rozszerzenie
-
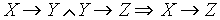
-- przechodniość
-
- każdy atrybut i cały schemat zależą funkcyjnie od klucza
- zależność tranzytywna A od X:
-
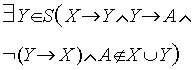
Zależności wielowartościowe
- zbiór atrybutów Y jest zależny wielowartościowo od zbioru X
gdy z każdą konfiguracją wartości atrybutów z X jest związany zbiór
konfiguracji wartości z Y niezależnie od wartości pozostałych
atrybutów:
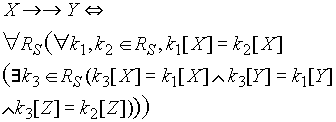
gdzie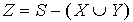
(znaczy to, że można wymienić części krotek: X i Y z k1 i resztę z k2) - najważniejsze własności:
-
- relacja RS daje się rozłożyć w sposób odwracalny na dwie: RXY i RXZ
- istnieje odpowiednik aksjomatów Armstronga dla zależności wielowartościowych
- przykład:
- podręczniki nie zależą od wykładowców
- nie ma zależności funkcyjnych
- zachodzą zależności
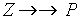 i
i
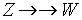 (zawsze para!)
(zawsze para!)
- można zamienić części krotek ZP i W
- można rozłożyć na: ZW, ZP
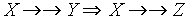
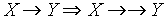
Zajęcia Wykładowca Podręcznik
Normalizacja
Redundancja
- redundancja polega na powtarzaniu
- wady redundancji:
- anomalie
- konieczność utrzymania spójności kopii
- marnowanie miejsca
Anomalie
- rodzaje:
- istnienia
- wstawiania
- usuwania
- modyfikacji
- przykład:
Imię Nazwisko Nr depart. Nazwa
depart.
Rozkład relacji i normalizacja
- redundancję usuwa się przez rozkład relacji
- rozkład odwracalny: można odwrócić przez naturalne złączenie
- rozkład relacji powinien doprowadzić do tzw. postaci normalnej
- rozkład relacji nie powinien powodować utraty zależności istniejących w relacji pierwotnej
Pierwsza postać normalna
- relacja jest w 1NF gdy wszystkie atrybuty są atomowe -- prostych typów
- 1NF jest wymogiem dla rachunku relacyjnego, a więc i języków zapytań
- kontrprzykłady:
- atrybut tablicowy
- zbiór
Druga postać normalna
- relacja jest w 2NF gdy każdy atrybut niekluczowy (nie należący do klucza właściwego) jest zależny funkcyjnie od całego klucza właściwego
- przyczyną braku 2NF jest zwykle błędne połączenie danych
- kontrprzykład: spis przepustek
- nazwisko zależy funkcyjnie od id prac., czyli od fragmentu klucza
- rozkład IB, IN doprowadza do 2NF
# Id prac. # Budynek Nazwisko
Trzecia postać normalna
- relacja jest w 3NF gdy
- jest w 1 NF i
- każdy atrybut niekluczowy jest bezpośrednio zależny funkcyjnie od całego klucza właściwego
- możliwe przypadki naruszenia 3NF:
- naruszenie 2NF
- istnienie zależności tranzytywnej (a więc niebezpośredniej) od klucza właściwego
- przyczyną braku 3NF jest zwykle błędne połączenie danych
- 3NF jest zazwyczaj wystarczająca dla usunięcia praktycznie ważnych anomalii
- każdy schemat można doprowadzić do 3NF zachowując:
- zależności
- odwracalność rozkładu
- kontrprzykład
- jest 2NF, bo klucz jest jednoatrybutowy
- zależność tranzytywna: I S P
(pensja zależy funkcyjnie od stanowiska) - rozkład INS, IP doprowadza do 3NF
# Id Nazwisko Stanowisko Pensja prac.
Postać normalna Boyce-Codda
- relacja jest w BCNF gdy każda nietrywialna zależność funkcyjna jest zależnością od klucza (niekoniecznie właściwego)
- w BCNF zależności tranzytywne nie istnieją w ogóle
- nie każdy schemat można doprowadzić do BCNF z zachowaniem zależności
- kontrprzykład: relacja w 3NF z anomaliami:
- istnieją tu klucze: MU, UK
(nazwy ulic mogą się powtarzać w różnych miastach, zakładamy że nazwy miast się nie powtarzają) - występują zależności:
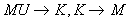
- anomalie: usuwając ulicę możemy utracić informację o mieście
- schemat jest w 3NF: brak atrybutów niekluczowych
- schemat nie jest w BCNF: K nie jest kluczem
- schemat jest nierozkładalny do BCNF bez utraty zależności
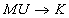
- istnieją tu klucze: MU, UK
Miasto Ulica Kod
- najczęściej zależności prowadzące do braku BCNF nie są istotne z punktu widzenia projektu
Czwarta postać normalna
- relacja jest w 4NF gdy jeśli każda nietrywialna zależność wielowartościowa jest zależnością od klucza (niekoniecznie właściwego)
- schemat doprowadza się do 4NF przez rozkład
- kontrprzykład:
- istnieją zależności
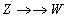 i
i
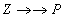
- nie ma zależności funkcyjnych
- jest więc BCNF
- występuje nadmiar informacji: powtórzone dane podręczników i wykładowców
- rozkład ZW, ZP doprowadza do 4NF
- istnieją zależności
Zajęcia Wykładowca Podręcznik
Związki między postaciami normalnymi
4NF => BCNF => 3NF => 2NF => 1NF
Projektowanie schematów relacyjnych
Model pojęciowy
Cele modelowania pojęciowego
- precyzyjne określenie zakresu projektu
- modelowanie informacji:
- niezbędnej dla działania organizacji
- niezależnie od implementacji
- wg określonego modelu danych
Diagramy związków encji (ERD)
- elementy:
- encje
- atrybuty encji
- związki
- unikalne identyfikatory
- ważne są konwencje!
Przykład diagramu ERD
Encje
- model rzeczy, osób itp.:
- o których chcemy przechowywać informacje
- które mają tożsamość
- nazwa: rzeczownik w l.poj., wielkie litery
- Przykłady:
- produkt (towar), przedmiot
- osoba, pracownik, klient
- dokument, pozycja dokumentu
Atrybuty
- określają cechy rzeczy, osób itp.:
- identyfikują
- opisują
- podają ilości
- klasyfikują
- są prostego (atomowego) typu
- muszą mieć precyzyjne nazwy
- Przykłady:
- kod towaru, nazwa
- nr identyfikacyjny, imię, nazwisko, adres
- cena, wartość, rodzaj płatności
Rodzaje atrybutów
- obowiązkowe (*)
- opcjonalne (o)
Związki
- pokazują zależności między encjami
- powinny być obustronnie nazwane
- nie zapisuje się sposobu realizacji
Cechy związków
- opcjonalność:
- obowiązkowy
- opcjonalny
- stopień:
- jeden (1)
- wiele (n)
- transferowalność
- związki rekurencyjne
Poprawność związków
- związki 1-1 są podejrzane
- związki obustronnie obowiązkowe są podejrzane
- związki rekurencyjne muszą być obustronnie opcjonalne
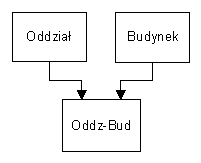
- związki n-m powinny zostać rozbite:
Związek n-m i jego rozbicie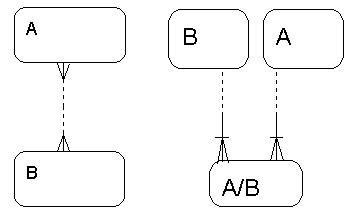
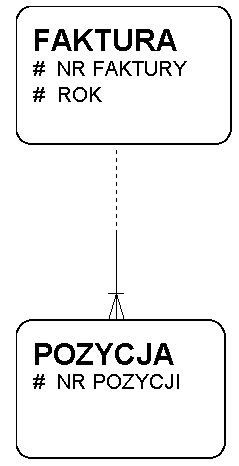
Identyfikacja encji
Unikalne identyfikatory
- każda encja powinna posiadać przynajmniej jeden unikalny identyfikator
- możliwe składniki:
- atrybuty
- związki
- atrybuty i związki
- pierwotny UID:
- identyfikuje wszystkie wystąpienia encji
- wszystkie składniki obowiązkowe
- przykład: numer id pracownika
- wtórne UID:
- do celów kontrolnych
- składniki mogą być opcjonalne
- przykłady: PESEL, nazwisko+imię+data urodzenia+imię ojca
Pożądane cechy pierwotnego UID
- niezmienność
- łatwość wyznaczenia wartości
- czytelność
- niewielka złożoność
Przykłady
UID faktury: atrybuty
UID pozycji: związek + atrybut (sequence in parent)
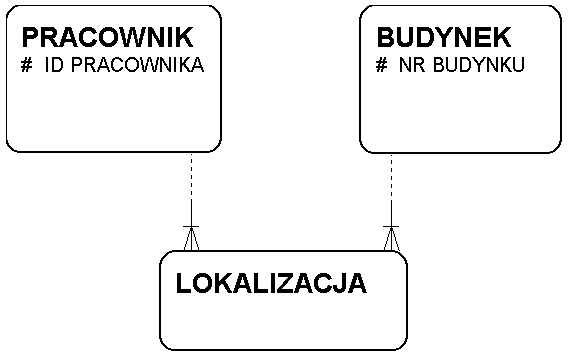
UID lokalizacji: tylko związki
Typowe konstrukcje
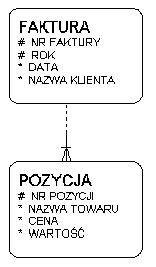
Master - detail
- typowa struktura dokumentu:
- nagłówek
- pozycje
- związek obowiązkowy po stronie detail
- UID detalu: związek + atrybut (najczęściej sequence in parent)
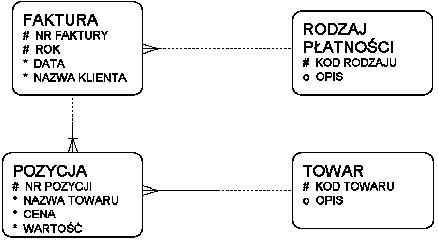
Struktura master - detail: faktura-pozycja
Klasyfikacja: faktura-płatność
Słownik: pozycja-towar
Słowniki
- stosuje się by uniknąć powtarzania danych
- przykłady: spis klientów, spis towarów
Klasyfikacja
- encję dla klasyfikacji stosuje się, gdy:
- klasyfikacja ma być ograniczona
- słownik klasyfikacji ma być zmienny
- przykłady: rodzaje płatności, grupy towarów, kolory
- kontrprzykłady: dni tygodnia, płeć
Śledzenie zmienności
- do śledzenia zmienności atrybutu tworzy się dodatkową encję
- nie należy używać konstrukcji z atrybutami: wartość1, wartość2, wartość3,...
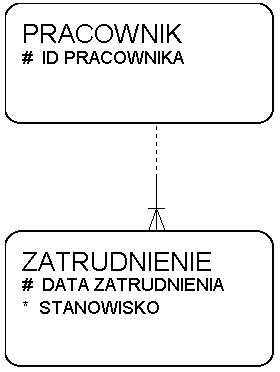
Zapis zmian stanowiska pracownika
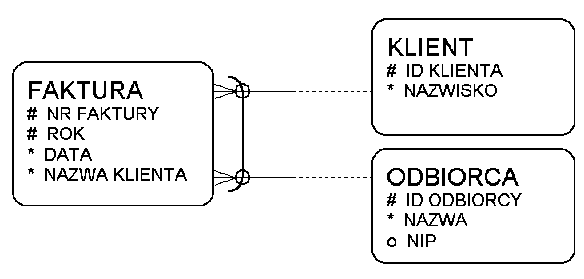
Związki wykluczające się
- zapisuje się za pomocą konwencji "łuku"
- łuk może być:
- obowiązkowy: jeden związek zachodzi
- opcjonalny: zachodzi jeden lub żaden
Związki wykluczające się (łuk obowiązkowy)
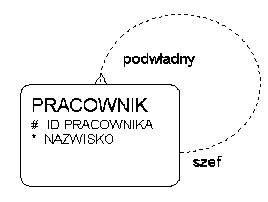
Drzewo
- stosowane np. do opisu hierarchii
- modelowane jako związek rekurencyjny obustronnie opcjonalny
Związek rekurencyjny -- hierarchia
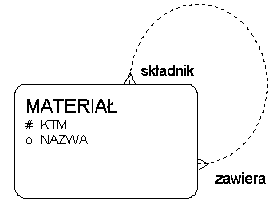
Graf
- stosowany np. do opisu struktur materiałowych: składnik--produkt
- może być reprezentowany przez związek rekurencyjny n-m
- reprezentacja ostateczna:
- węzły -- encja "pierwotna"
- łuki -- dodatkowa encja
- dwa związki 1-n
Reprezentacje grafu materiałów:
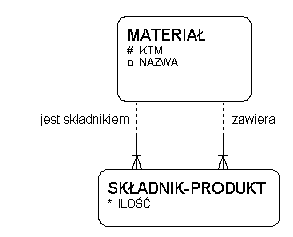
w postaci związku rekurencyjnego n-m
i w postaci dwóch encji
Lista
- nie stosuje się wskaźników
- pozycje listy oznacza się numerami kolejnymi
Projekt logiczny
Cele projektowania logicznego
- zaprojektowanie:
- struktur danych
- ograniczeń integralności
- obudowy proceduralnej (wyzwalacze)
- perspektyw
- rozwiązań dla przetwarzania rozproszonego
- bierze się pod uwagę konkretny SZRBD
Przekształcenie modeli pojęciowy logiczny
- encje tabele
- nazwy tabel -- w liczbie mnogiej
- usuwamy znaki narodowe z nazw obiektów b.d.
- atrybuty kolumny
- typy z SZRBD
- obowiązkowość więzy not null
- pierwotne UID klucze główne
- wtórne UID ograniczenia unikalności
- związki klucze obce:
- kolumny
- ograniczenia
- obowiązkowość klucz not null
- nietransferowalność klucz niezmienny
Ograniczenia integralności
Ograniczenia deklaratywne i proceduralne
- deklaratywne:
- wykonywane przez serwer b.d.
- dotyczą wszystkich operacji
- dotyczą wszystkich wierszy (statyczne)
- wykonanie bezbłędne i zoptymalizowane
- proceduralne:
- wykonywane przez serwer (dotyczą wszystkich operacji) lub aplikację (dotyczą tylko operacji tej aplikacji)
- dotyczą tylko zmienianych danych (dynamiczne)
- kod może zawierać błędy
- należy dążyć do ograniczeń:
- deklaratywnych
- po stronie serwera b.d.
Rodzaje
ograniczeń deklaratywnych
- kolumny: not null, check (in-line)
- wiersza: check
- tabeli: primary key, unique
- referencyjne: foreign key
Wyzwalacze
(triggers)
- procedury rezydujące w serwerze b.d.
- automatycznie wyzwalane przez:
- wstawienie wiersza
- usunięcie wiersza
- modyfikację określonych kolumn
- służą do:
- wymuszania nietypowych reguł integralności (bussiness rules)
- nietypowych zabezpieczeń dostępu
- śledzenia zmian w b.d. (audit)
- wymuszania integralności referencyjnej w rozproszonych b.d.
- nietypowej replikacji danych
Klucze
Klucz główny (primary key)
- funkcja: jednoznaczne identyfikowanie wiersza tabeli
- budowa:
- ogr. deklaratywne primary key
- dla UID z atrybutów -- odpowiednie kolumny
- dla UID zawierającego związki -- kolumny odpowiednich kluczy obcych
- wszystkie kolumny klucza głównego muszą być obowiązkowe (not null)
- pożądane cechy:
- niezmienność
- mała długość (wydajność!)
- sztuczne klucze główne:
- klucz numeryczny
- mechanizm do generowania unikalnych numerów (tzw. sekwencja)
- z kluczem głównym jest z reguły związany indeks unikalny
Klucze obce
- funkcja: realizują związki
- budowa:
- dodatkowe kolumny klucza obcego odpowiadające kolumnom wskazywanego klucza głównego
- ogr. deklaratywne foreign key
- sposób obsługi kasowania/modyfikacji wskazywanego klucza głównego:
- restrykcja
- kaskada
- reprezentacja łuku:
- dwa osobne klucze obce opcjonalne
- dodatkowy warunek wykluczania (ograniczenia check lub wyzwalacz)
- należy rozważyć zdefiniowanie indeksu dla klucza obcego
Realizacja więzów: klucz obcy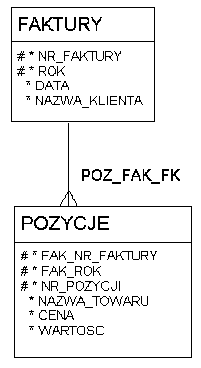
Etapy projektowania logicznego
Kolejność czynności
- przekształcenie modelu pojęciowego
- poprawki (np. usunięcie znaków narodowych i spacji z nazw)
- denormalizacja
- uzupełnianie modelu logicznego:
- indeksy
- wyzwalacze
- perspektywy
- projektowanie rozproszone
- projektowanie fizyczne (przestrzenie tabel, parametry alokacji, klastry itp.)
- implementacja (kod DDL)
- czynnośći pomocnicze
- szacowanie rozmiaru b.d.
- opracowanie strategii administrowania
(np. kopie zapasowe)
Perspektywy
- zapamiętane w b.d. definicje zapytań
- stanowią "widok" na tabele
- można ich używać tak jak tabel
(niektóre są tylko read-only!) - zastosowanie:
- ułatwienie powtarzających się zapytań
- zabezpieczenie dostępu
Indeksy
- służą do szybkiego wyszukiwania i sortowania danych
- budowa:
- oparte na kolumnie lub złożeniu kolumn (tzw. kluczu indeksowania)
- wewnątrz zwykle B-drzewo
(drzewo zrównoważone)
- wykorzystanie:
- indeks pozwala wyszukiwać według początku klucza indeksowania
- indeks unikalny (unique) zapewnia niepowtarzalność klucza indeksowania
- przykład:
CREATE INDEX prc_i ON pracownicy (nazwisko,imie,data_urodzenia);- przyspiesza wyszukanie wg: nazwiska, nazwiska+imienia, nazwiska+imienia_daty
- nie przyspiesza wyszukiwania wg: imienia+nazwiska, imienia, daty itp.
- okoliczności stosowania:
- dane używane często do wyszukań i złączeń, o dobrej selektywności
- klucze obce
- klucze unikalne
Denormalizacja
- stosuje się dla znaczącego poprawienia wydajności
- elementy:
- wprowadzenie redundantnych danych
- wprowadzenie kodu zapewniającego spójność
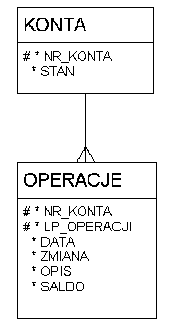
- przechowywanie agregatów (sumy, średnie):
Przechowywanie agregatów: ostatni stan
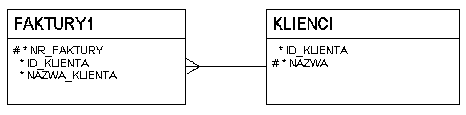
- pre-join:
Pre-join: kopia nazwy klienta

- pośredni klucz obcy:
Pośredni klucz obcy: pracownicy-oddziały

- nie każdy przypadek przechowywania wyników obliczeń jest denormalizacją!
Implementacja modelu logicznego
- instalacja SZRBD i utworzenie bazy danych
- tworzenie struktur danych:
- elementy projektu przekształca się w odpowiednie zdania DDL (Data Definition Language), umieszczane w skryptach
- tworzy się schemat użytkownika-właściciela obiektów struktury
- uruchamia się skrypty tworzące strukturę
- tworzy się konta użytkowników i nadaje się im uprawnienia dostępu
- tworzy się synonimy
- wykonuje się kopię rezerwową (backup)
- wprowadza się dane (np. przez import)
- opracowanie i wdrożenie strategii wykonywania kopii rezerwowych
- opracowanie i uruchomienie aplikacji
- strojenie:
- aplikacji
- bazy danych